
Altaf Ur Rahman
200 posts

A senior Google engineer just dropped a 421-page doc called Agentic Design Patterns.
Every chapter is code-backed and covers the frontier of AI systems:
→ Prompt chaining, routing, memory
→ MCP & multi-agent coordination
→ Guardrails, reasoning, planning
This isn’t a blog post. It’s a curriculum. And it’s free.

English
Altaf Ur Rahman đã retweet

Ilya Sutskever gave John Carmack a list of papers to read, so as to improve John's understanding of AI. That is a lot to read. If you want to quickly grasp what those papers are about, in this thread I share maps on over 20 of them 👇

English
Altaf Ur Rahman đã retweet

Congrats to @AIatMeta on Llama 3 release!! 🎉
ai.meta.com/blog/meta-llam…
Notes:
Releasing 8B and 70B (both base and finetuned) models, strong-performing in their model class (but we'll see when the rankings come in @ @lmsysorg :))
400B is still training, but already encroaching GPT-4 territory (e.g. 84.8 MMLU vs. 86.5 4Turbo).
Tokenizer: number of tokens was 4X'd from 32K (Llama 2) -> 128K (Llama 3). With more tokens you can compress sequences more in length, cites 15% fewer tokens, and see better downstream performance.
Architecture: no major changes from the Llama 2. In Llama 2 only the bigger models used Grouped Query Attention (GQA), but now all models do, including the smallest 8B model. This is a parameter sharing scheme for the keys/values in the Attention, which reduces the size of the KV cache during inference. This is a good, welcome, complexity reducing fix and optimization.
Sequence length: the maximum number of tokens in the context window was bumped up to 8192 from 4096 (Llama 2) and 2048 (Llama 1). This bump is welcome, but quite small w.r.t. modern standards (e.g. GPT-4 is 128K) and I think many people were hoping for more on this axis. May come as a finetune later (?).
Training data. Llama 2 was trained on 2 trillion tokens, Llama 3 was bumped to 15T training dataset, including a lot of attention that went to quality, 4X more code tokens, and 5% non-en tokens over 30 languages. (5% is fairly low w.r.t. non-en:en mix, so certainly this is a mostly English model, but it's quite nice that it is > 0).
Scaling laws. Very notably, 15T is a very very large dataset to train with for a model as "small" as 8B parameters, and this is not normally done and is new and very welcome. The Chinchilla "compute optimal" point for an 8B model would be train it for ~200B tokens. (if you were only interested to get the most "bang-for-the-buck" w.r.t. model performance at that size). So this is training ~75X beyond that point, which is unusual but personally, I think extremely welcome. Because we all get a very capable model that is very small, easy to work with and inference. Meta mentions that even at this point, the model doesn't seem to be "converging" in a standard sense. In other words, the LLMs we work with all the time are significantly undertrained by a factor of maybe 100-1000X or more, nowhere near their point of convergence. Actually, I really hope people carry forward the trend and start training and releasing even more long-trained, even smaller models.
Systems. Llama 3 is cited as trained with 16K GPUs at observed throughput of 400 TFLOPS. It's not mentioned but I'm assuming these are H100s at fp16, which clock in at 1,979 TFLOPS in NVIDIA marketing materials. But we all know their tiny asterisk (*with sparsity) is doing a lot of work, and really you want to divide this number by 2 to get the real TFLOPS of ~990. Why is sparsity counting as FLOPS? Anyway, focus Andrej. So 400/990 ~= 40% utilization, not too bad at all across that many GPUs! A lot of really solid engineering is required to get here at that scale.
TLDR: Super welcome, Llama 3 is a very capable looking model release from Meta. Sticking to fundamentals, spending a lot of quality time on solid systems and data work, exploring the limits of long-training models. Also very excited for the 400B model, which could be the first GPT-4 grade open source release. I think many people will ask for more context length.
Personal ask: I think I'm not alone to say that I'd also love much smaller models than 8B, for educational work, and for (unit) testing, and maybe for embedded applications etc. Ideally at ~100M and ~1B scale.
Talk to it at meta.ai
Integration with github.com/pytorch/torcht…
English
Level up 🎉 I reached @localguides level 5 by helping others explore on Google Maps. #localguides
GIF
English
Altaf Ur Rahman đã retweet
# on shortification of "learning"
There are a lot of videos on YouTube/TikTok etc. that give the appearance of education, but if you look closely they are really just entertainment. This is very convenient for everyone involved : the people watching enjoy thinking they are learning (but actually they are just having fun). The people creating this content also enjoy it because fun has a much larger audience, fame and revenue. But as far as learning goes, this is a trap. This content is an epsilon away from watching the Bachelorette. It's like snacking on those "Garden Veggie Straws", which feel like you're eating healthy vegetables until you look at the ingredients.
Learning is not supposed to be fun. It doesn't have to be actively not fun either, but the primary feeling should be that of effort. It should look a lot less like that "10 minute full body" workout from your local digital media creator and a lot more like a serious session at the gym. You want the mental equivalent of sweating. It's not that the quickie doesn't do anything, it's just that it is wildly suboptimal if you actually care to learn.
I find it helpful to explicitly declare your intent up front as a sharp, binary variable in your mind. If you are consuming content: are you trying to be entertained or are you trying to learn? And if you are creating content: are you trying to entertain or are you trying to teach? You'll go down a different path in each case. Attempts to seek the stuff in between actually clamp to zero.
So for those who actually want to learn. Unless you are trying to learn something narrow and specific, close those tabs with quick blog posts. Close those tabs of "Learn XYZ in 10 minutes". Consider the opportunity cost of snacking and seek the meal - the textbooks, docs, papers, manuals, longform. Allocate a 4 hour window. Don't just read, take notes, re-read, re-phrase, process, manipulate, learn.
And for those actually trying to educate, please consider writing/recording longform, designed for someone to get "sweaty", especially in today's era of quantity over quality. Give someone a real workout. This is what I aspire to in my own educational work too. My audience will decrease. The ones that remain might not even like it. But at least we'll learn something.
English


Crypto is a reality, and the world has already accepted it. Pakistan if goes into denial will be backwarded in the huge market
#darnawithwaqarzaka
English
This e-commerce eco system is future of Pakistan. Govt must ensure presence of Amazon Pakistan @fawadchaudhry
@amazon @ZakaWaqar #AmazonInPakistan
English
Pakistanis have more than 70 % success rate in Amazon business.
Please come to Pakistan @amazon #AmazonInPakistan
English
Altaf Ur Rahman đã retweet

English
Altaf Ur Rahman đã retweet

Looking forward to talks by @wellingmax and Yoshua Bengio this week as our special year on machine learning, @the_IAS
IAS Seminar Series on Theoretical Machine Learning@IASMLSeminars
This coming week Prof. @wellingmax of @UvA_Amsterdam and Prof. Yoshua Bengio of @umontreal @MILAMontreal will be speaking at @the_IAS as part of the Special Year on Theoretical #MachineLearning. Details and registration info at ias.edu/events/seminar… and ias.edu/events/seminar….
English
Altaf Ur Rahman đã retweet

If you guys want to join,
"United South Asian Social Media Front" which is the largest social media team of South Asian countries i.e 🇳🇵 🇵🇰 🇨🇳 🇧🇩 🇮🇷 🇷🇺 🇦🇫
We would request you to reply below this tweet for joining us.
#SAUSMF

English
Altaf Ur Rahman đã retweet


Altaf Ur Rahman đã retweet

⚡️ “Thank you for your love! @RanaAyyub @IamBilalAshraf @iihtishamm by @TRTErtugrulPTV twitter.com/i/events/12601…
English
New video is being uploaded, Kindly watch and subscribe to the channel
youtu.be/jIPoVFuWYYQ

YouTube
English
Dear all,
Join me on my Youtube channel. Kindly subscribe.
youtube.com/channel/UCqcbP…
English
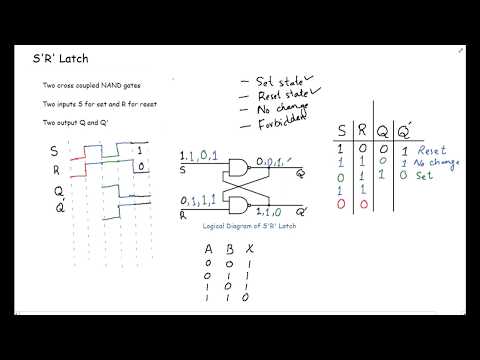
4.Latches Part 2: S'R' Latch | Digital Logic Design youtu.be/X3OG-CLpHc0 via @YouTube
YouTube
English
Altaf Ur Rahman đã retweet

1. This is how the positive cases are spread across Sector I-10/1 and 1-10/4. Ground surveillance teams are working. We will get a better picture of the sector in 2 days. I would request everyone to please stay put and cooperate with us. In sha Allah things will get better

English