Labomen
498 posts


Composer 2 is now available in Cursor.




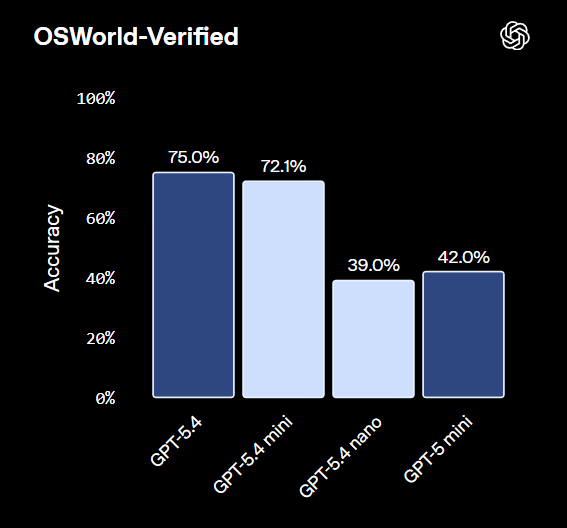



GPT-5.4-mini is dead on arrival you can just use Kimi-K2.5 for $1.5 less and better performance



idk if anyone will read this, but I tested OAI Responses API speed with GPT-5.4. Sub = the backend used by Codex (used my $20 sub), API = Tier 5 API key. In the end: priority on API right now is about 57t/s, normal API 47t/s, sub priority 50t/s, normal sub... only 35t/s.




Maybe qwen 2b can do it So far 4b is the smallest to follow skills reliably








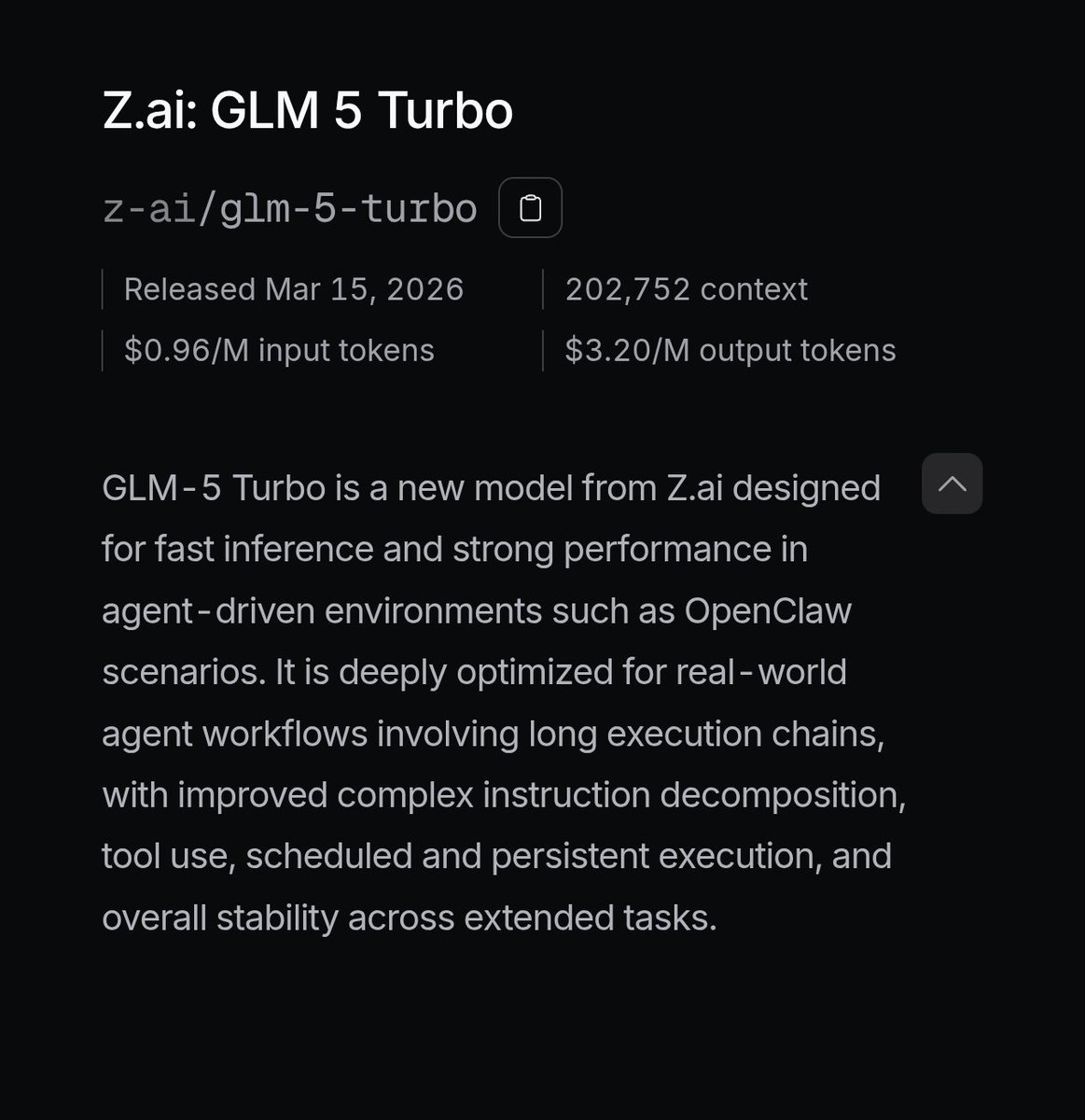
@Zai_org It costs more than 3 Flash (which is a very capable model and is also very fast), honestly at this point I think some Chinese model vendors lost the plot. Gemini 3 Flash is $0.5/$3 GLM 5 Turbo is $1.2/$4 (!) on the official API, $0.96/$3.2 on OpenRouter with a discount.



Need it sooner? Apply for Early Access: - Pro (GLM-5-Turbo): docs.google.com/forms/d/e/1FAI… - Lite (GLM-5): docs.google.com/forms/d/e/1FAI…