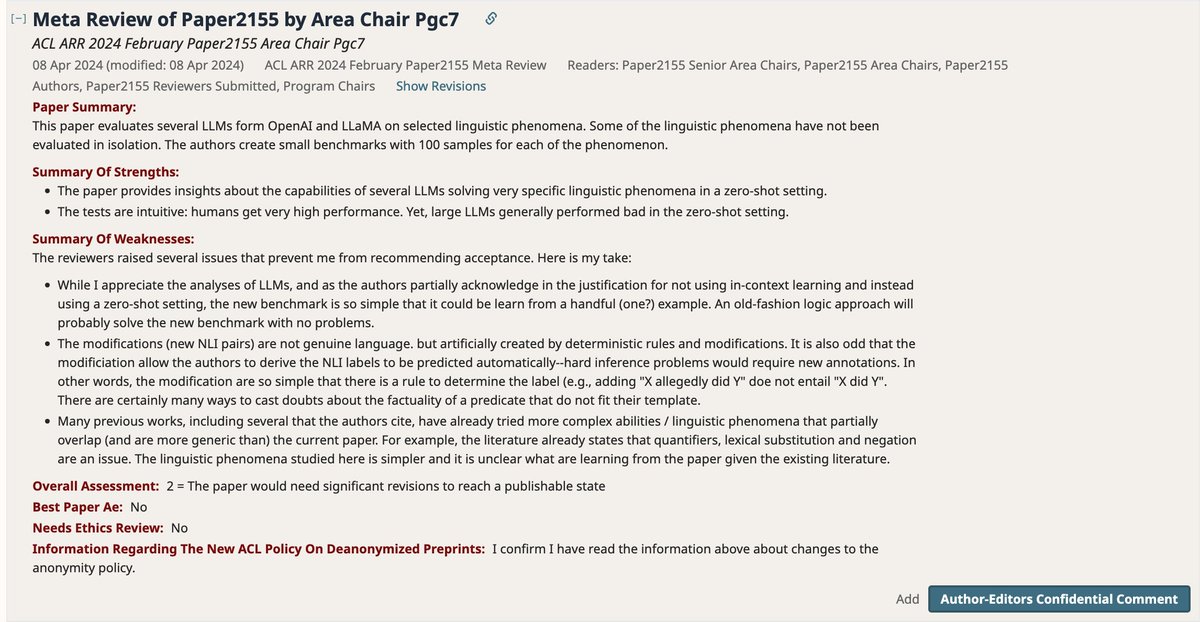
Thomas Kollar đã retweet

Meet LA-Pose. Our latest model taking Wayve another step towards generalization at scale.
LA-Pose employs large-scale self-supervised learning, building strong motion representations for 3D perception from 10.2 million unlabeled driving video snippets, unlike today's strongest approaches that often depend on expensive, carefully curated 3D supervision.
With only a lightweight pose head and limited labelled data, LA-Pose achieves:
📷 State-of-the-art camera pose estimation
🌎 Strong zero-shot generalization across diverse driving scenarios
🏷️ Orders of magnitude less labelled data than fully supervised 3D approaches
Our full blog post: wayve.ai/thinking/la-po…
Explore the full paper here: la-pose.github.io
English