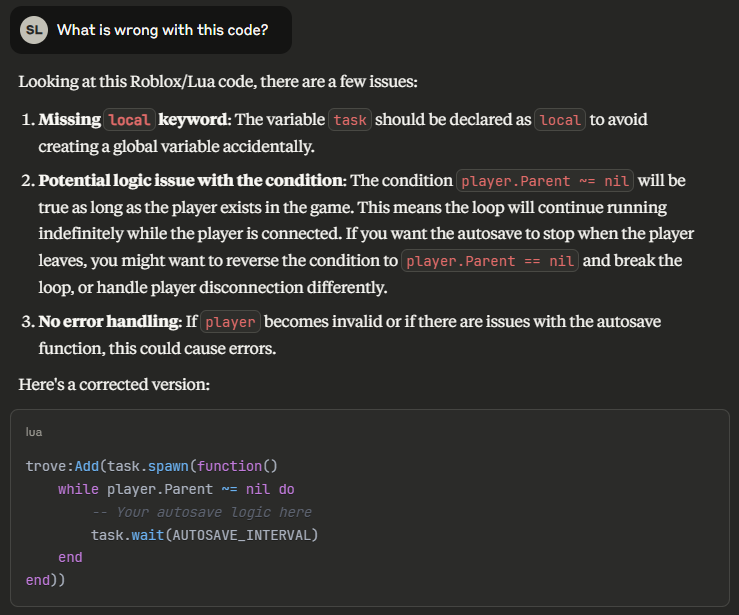
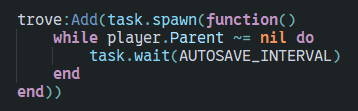
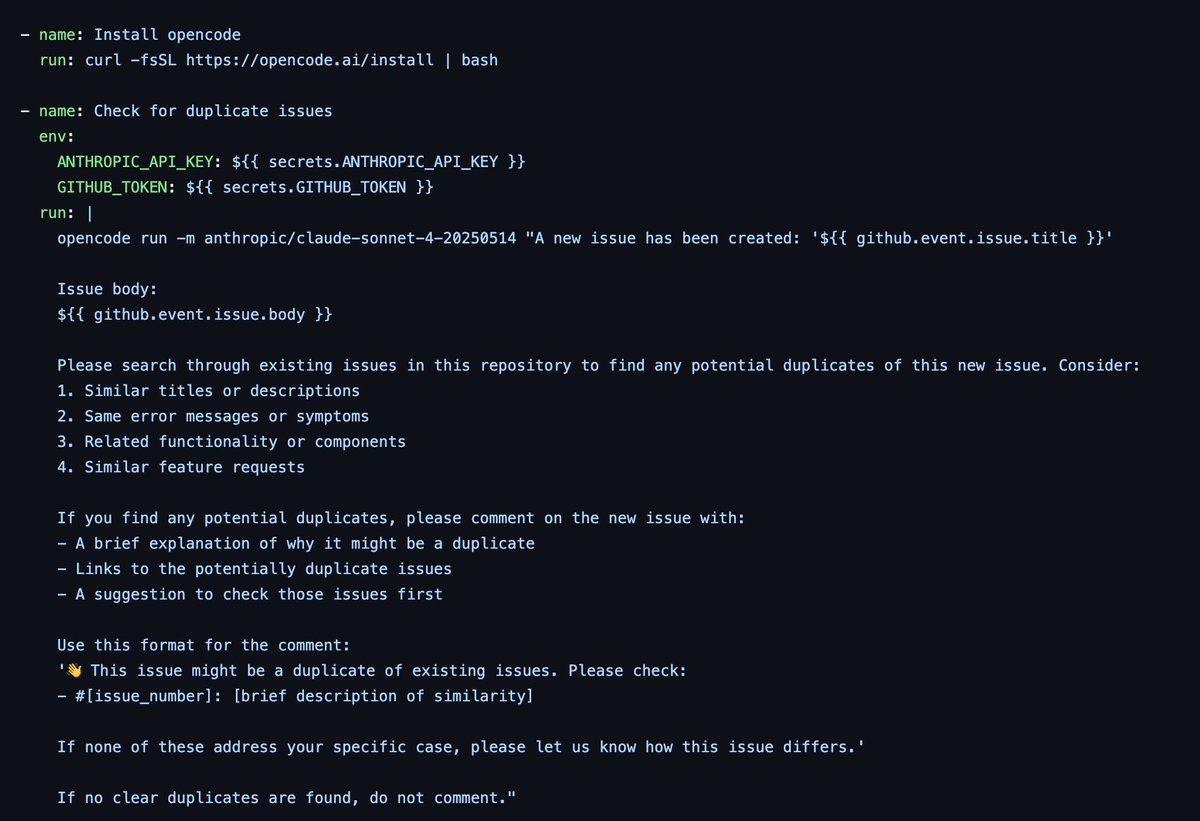
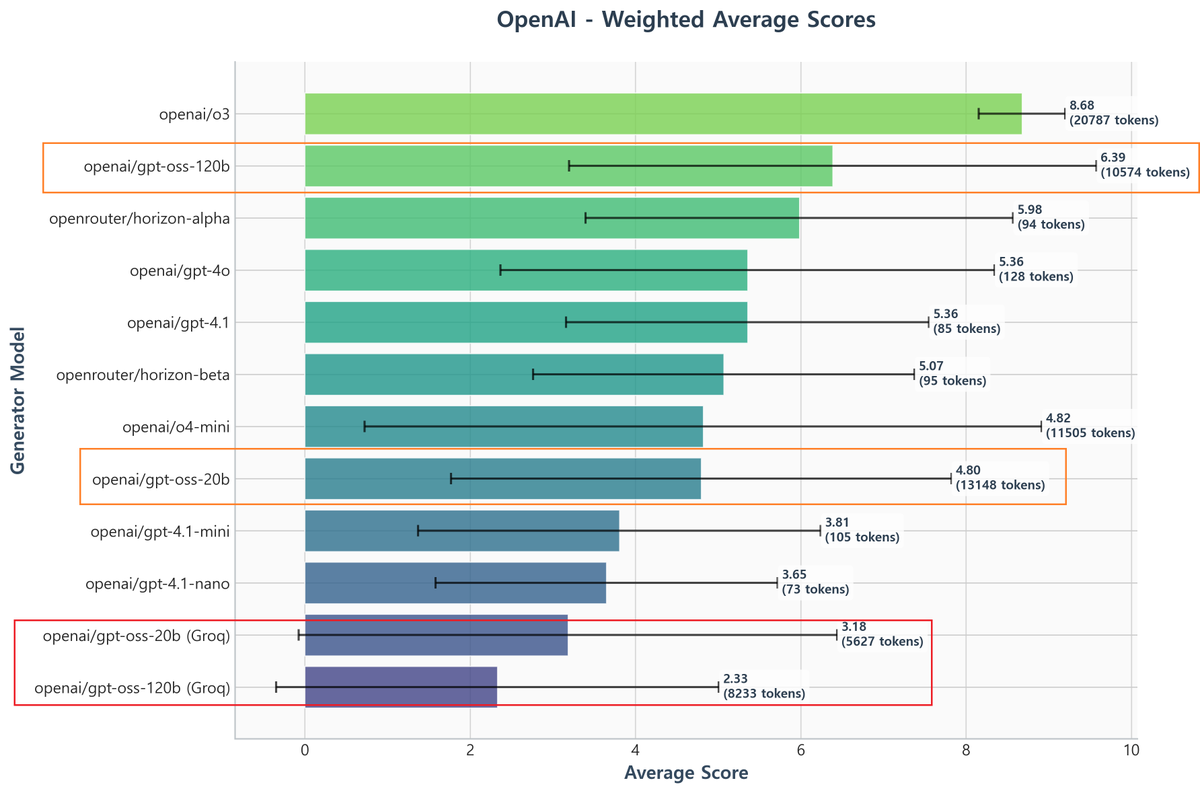
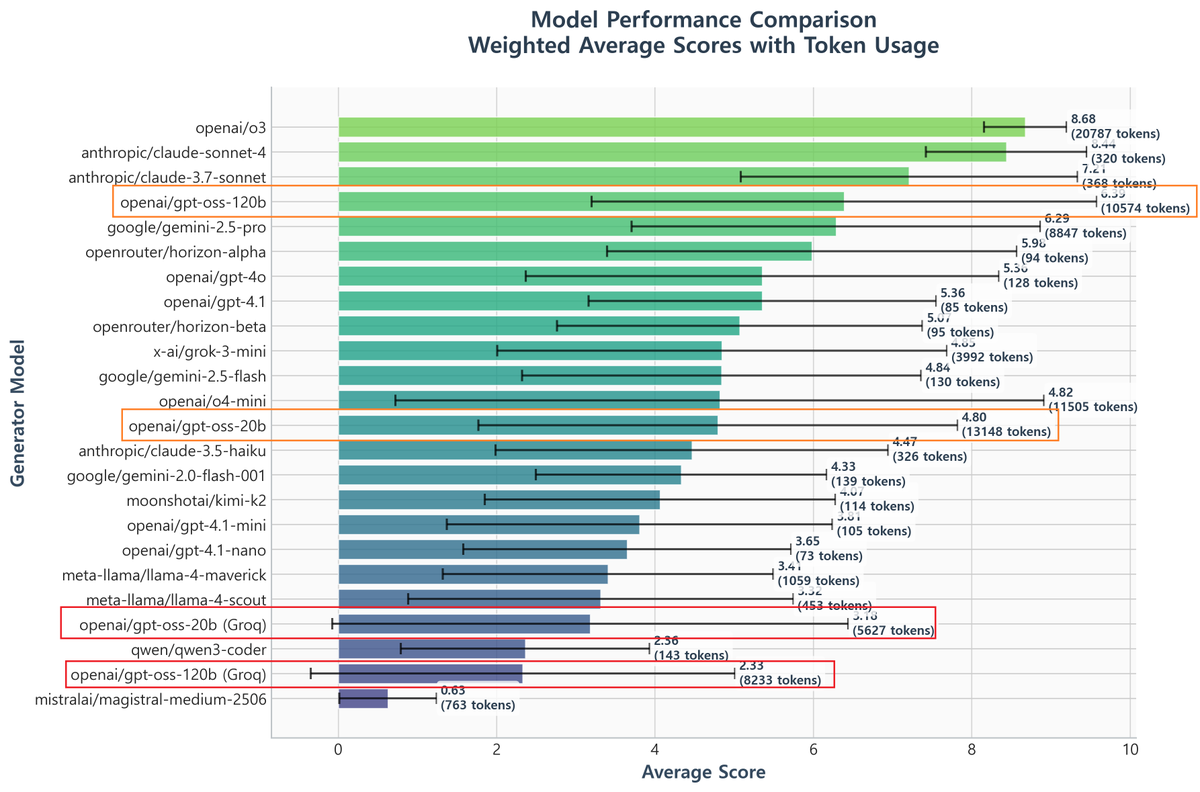
GPT 5.4 has a much better ability to delegate work to sub-agents compared to GPT 5.3.
Even within OpenCode, which has not been tuned for subagents as much as Codex has (now), GPT 5.4 is able to delegate work even at the planning stage! This is sometihng GPT 5.3 would never do.
English