تغريدة مثبتة
NVIDIA AI
12.8K posts


NVIDIA AI
@NVIDIAAI
Teaching your AI new tricks.
Santa Clara, CA انضم Haziran 2016
879 يتبع301.7K المتابعون



Great to work with @NVIDIAAI on running @StepFun_ai's Step-3.7-Flash with vLLM on the DGX Station.🤝
Run it locally, or in production as an @NVIDIA NIM container, both powered by vLLM! Serve it now 🚀
🔗 build.nvidia.com/station/vllm
NVIDIA AI@NVIDIAAI
You can read more about running Step 3.7 Flash on NVIDIA GPUs here: developer.nvidia.com/blog/run-step-…
English
NVIDIA AI أُعيد تغريده

What if you could take three completely different model families… and distill them into one tiny model? 🤯
📜 Paper: arxiv.org/pdf/2605.21699
MOPD (Multi-Teacher On-Policy Distillation) has become a standard procedure in post-training. We already distill multiple specialized variants of the same model into a single set of weights.
But what if we could go further - and distill models from entirely different families? Turns out, it is possible.
Today we’re releasing a paper on cross-tokenizer distillation - our first steps in this exciting direction. 📄
We distilled Qwen3-4B, Phi-4-Mini, and Llama-3B into Llama-3.2-1B.
MMLU jumped from 32.05 → 46.32 when using multiple teachers. 📈
The team is now working on Nemo-RL integration so the community can try this method in their own settings. Plus, we are scaling experiments up. 🚀
English

Pavlo is an account you should probably be following you’re in the ML/Local LLM space 🤩
Insane post below on distilling 3 models into 1 👀⬇️

Pavlo Molchanov@PavloMolchanov
What if you could take three completely different model families… and distill them into one tiny model? 🤯 📜 Paper: arxiv.org/pdf/2605.21699 MOPD (Multi-Teacher On-Policy Distillation) has become a standard procedure in post-training. We already distill multiple specialized variants of the same model into a single set of weights. But what if we could go further - and distill models from entirely different families? Turns out, it is possible. Today we’re releasing a paper on cross-tokenizer distillation - our first steps in this exciting direction. 📄 We distilled Qwen3-4B, Phi-4-Mini, and Llama-3B into Llama-3.2-1B. MMLU jumped from 32.05 → 46.32 when using multiple teachers. 📈 The team is now working on Nemo-RL integration so the community can try this method in their own settings. Plus, we are scaling experiments up. 🚀
English

Scoop: First Windows PCs powered by Nvidia chips to debut next week axios.com/2026/05/30/nvi…
English

Nvidia, Microsoft, and Arm are all teasing Nvidia’s new N1X laptop processors theverge.com/news/940275/nv…
English

Day 2 of @poolsideai Research Hackathon, 60 minutes until submissions are due⏱️ 👨🏽💻👩🏼💻
Who will be the chosen team to take home the shiny @NVIDIAAI DGX Spark? 💚🪩




English


Hours of video, now searchable by your agent.
We just released a new set of agent skills and modular architecture for the Metropolis Blueprint for Video Search and Summarization, eliminating the need for manual configuration of multiple microservices.
Load the skills into a compatible coding agent and it deploys the stack, turning hours of footage into searchable, actionable intelligence through a chat interface. Ask in plain language and get back clips, summaries, and answers.

English
This is a great read on post-training and open models.
@harvey & @trajectorylabs post-trained Nemotron 3 Super on complex legal tasks with some very impressive initial results. All with auditable weights, real security, and clear provenance.
Harvey@harvey
We're partnering with @trajectorylabs to bring sovereign continual learning to legal AI with NVIDIA Nemotron models. Continual learning allows agents to improve over time from feedback on their work: every redline refines the next draft. Open-weight models offer full auditability and data sovereignty over legal agents. Using Trajectory's platform, we post-trained NVIDIA Nemotron 3 Super on our Legal Agent Benchmark (LAB), measuring performance on 1,200+ complex end-to-end legal tasks across 24 practice areas. Initial results show that a post-trained Nemotron 3 Super can match performance of closed-source frontier models. This is just the start: we'll keep pushing the frontier with the more powerful Nemotron 3 Ultra when available.
English

Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning.
Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey.
We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there.
Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark.
The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria +25%, all while beating the performance-vs-cost frontier. That's the power of our platform.
And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used.
Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents

English

Two themes are becoming increasingly important for agent deployments: continual learning and sovereign AI.
Continual learning lets agents improve over time from feedback, and to get it right for high-stakes work we’ll need agents to operate in secure environments, with full auditability, and data sovereignty.
We’re partnering with @rronak_ @QuantumArjun and the @trajectorylabs team on continual learning and are sharing initial results post-training @NVIDIAAI 's Nemotron 3 Super on Legal Agent Bench.
Trajectory@trajectorylabs
Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning. Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey. We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there. Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark. The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria +25%, all while beating the performance-vs-cost frontier. That's the power of our platform. And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used. Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents
English


@aijoey @GM @ToyotaMotorCorp @Ford @NissanMotor @BMWGroup @Honda @MercedesBenz @ycombinator Next is a price negotiating agent
English

car dealership websites are still way too painful to search.
bad filters, slow pages, weird inventory pages, and half the time you can’t get clean data out of anything.
so i built a free vehicle inventory cli.
search real u.s. dealer listings from the terminal, save searches, track price history, or let an agent use it through json and mcp.
built on the auto.dev vehicle listings api
shoutout @mvanhorn and @ppressdev
github.com/joeynyc/nation…

English



Biggest W in the world. Like, skyscraper height
NVIDIA AI@NVIDIAAI
We're adopting the Linux Foundation’s OpenMDW framework across our open model families. This helps make open model licensing simpler and more consistent at scale. A single legal framework across models, code, documentation, and data helps reduce friction for developers and enterprises building with open source.
English

Just tried out NVIDIA's latest vision language detection model.
Tried with 2 images. As you can see, the first image is where I asked to detect only lentils, and in the other one, I tried to find more than one thing.
Worked really well. I tried it in Hugging Face Spaces.
NVIDIA just dropped LocateAnything-3B, which is new vision-language model that could be a major step forward for embodied AI and robotics.
Instead of generating bounding box coordinates one token at a time, it introduces Parallel Box Decoding, allowing AI systems to locate objects much faster while improving accuracy.
The model was trained on over 138 million language queries and 785 million bounding boxes, enabling everything from object detection and GUI understanding to robotics and autonomous systems
NVIDIA claims up to 2.5x higher throughput, making AI agents faster at seeing, understanding, and interacting with the real world.
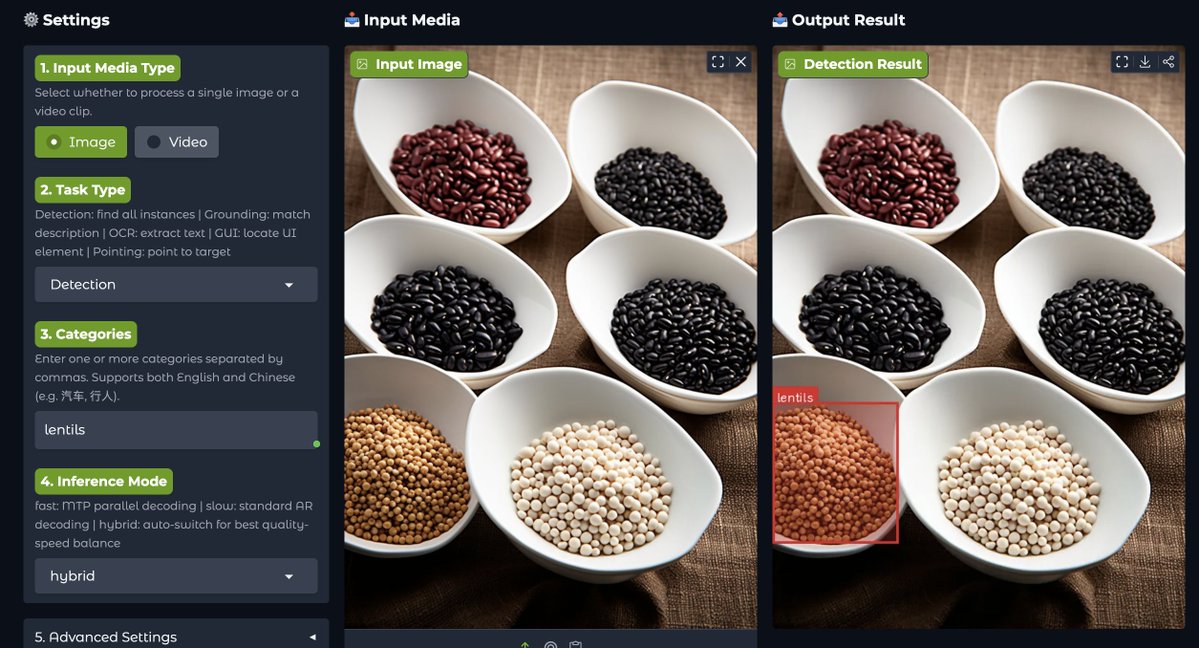

NVIDIA AI@NVIDIAAI
This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗 Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act. Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection. Project page: nvda.ws/4dKSohb
English