
AboveSpec
284 posts

AboveSpec
@above_spec
Love 3d printing, playing with local llms and learning Claude Code
Ontario, Canada انضم Aralık 2017
174 يتبع1K المتابعون

つまり、DeepSeek-V4-Flash-IQ2XXSをRTXPro6KでドライブしKVキャッシュはSSDに持たせる
Sonnet4.6くらいの戦闘力をもつClaudeCodeをコンテキスト長さ1Mかつまともな速度でローカルで使える道がついたということです
帯域スペック的に40token/s くらいは行くと思うんだよな。いやもっとか
都乃健🇯🇵文明航海士©|とのけん3@Tono_Ken3
DS4=DwarfStar4 OpencodeのDS-4VFによればIQ2モデルで単騎推論とすればRTXPro6K対応可能とのことで早速コンパイル完了 モデルをDLする。素晴らしい展開 github.com/antirez/ds4
日本語
@witcheer Here is my setup for 4060 ti 8gb, I can fit whole 262k and get 49-55 tok/s with ik_llama.cpp:
x.com/i/status/20522…
AboveSpec@above_spec
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵
English

I ran Hermes agent (v0.13.0) with qwen3.6-35B-A3B on my RTX 4060 Ti 8GB for the first time today. full local agent stack.
my question was: can a local 3B-active MoE model actually drive an agent harness end-to-end?
quickly, my setup:
>WSL2 Ubuntu 26.04 → CUDA 13.2 → llama.cpp (b9049) → llama-server → Hermes Agent
>model: qwen3.6-35B-A3B-UD-Q4_K_M
>config: -ngl 999 -ncmoe 30 -c 32768 --cache-type-k q8_0 --cache-type-v q8_0
>baseline decode: 35.36 tok/s (from prior -ncmoe sweep)
I tested 4 rounds, easy to hard:
1. single tool call (list files) - pass, 31.4 tok/s
2. 5 chained tool calls (mkdir → venv → pip → write script → run) - pass, self-corrected a path error
3. read 10 files from windows via /mnt/c/ - pass when scoped, fail when hermes read full files
4. write a 95-line python CLI with argparse, then run it - pass, genuinely usable code
my biggest issue: the context.
hermes system prompt eats ~13.5K tokens. out of 32K, that leaves ~18.5K usable. a multi-step task fills that in 3-4 exchanges.
when I pushed it, hermes tried to compress via the same qwen model → slot contention → timeout → retry storm → ctrl+c.
and also, hermes has a 64K minimum context gate - needs a config override to run with 32K
my conclusion:
hermes + qwen3.6-35B-A3B is a capable local agent for short automated tasks, code gen, file ops, cron jobs. 4-5 tool calls per session, but not viable for long multi-turn sessions. context fills too fast, compression self-destructs, VRAM cliff halves speed before you hit the wall.
----
I am curious if anyone's running hermes agent with a local model on similar hardware (8-12 GB VRAM). what model are you pairing it with? how do you handle the context ceiling?
I am especially interested in setups that solve the compression-model problem (separate lightweight model for context compression).
witcheer ☯︎@witcheer
now testing real results with Hermes on WSL2
English
@FStrongpaw So nice! Which proart motherboard is that? I have B650 Proart as daily driver right now and looks like I could do similar.
English

holy crap! the symmetry..the symmetry.. what a difference mached gpu's makes!
AAAHHH!!!! now i have to redownload all the models i deleted and retest Everyhting i've rejected for the last 4 months!
oh shit... what if all my ai's actually... *gasp* work? 😱
i'm screwed 😅

English

卧槽无敌,秒杀 RTX Pro 6000
AMD@AMD
Don’t just scale AI. Scale ROI. AMD Instinct MI350P PCIe cards deliver 144 GB of HBM3E memory and up to 2299 teraFLOPS (at MXFP4) in a drop-in, air-cooled card built for standard servers. That’s how you scale AI at maximum ROI without redesigning your data center. Interested in drop-in AMD Instinct MI350P PCIe cards? See the specs at the link: bit.ly/4exiAg2
中文
@sudoingX Or run 35b a3b with cpu offload then even 8gb can be decent at 50-55t/s with full 262k context at q4: x.com/i/status/20522…
AboveSpec@above_spec
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵
English

it's so easy to get started in local ai actually. the only real wall is vram math.
practical heuristic for a single gpu:
> 24gb = 27B Q4_K_M at 262k context (qwen 3.6, carnice-v2)
> 16gb = 13B Q5_K_M at 32k or 9B Q8_0 at 64k
> 12gb = 8B Q5_K_M at 16k
> 8gb = 4B Q4_K_M at 8k
quantization rule of thumb: Q4_K_M ≈ 0.6 gb per billion params. kv cache scales with context. add 1 gb activation buffer. that's the math.
every other piece (llama.cpp build, hermes agent setup, prompt config) is one good day setup. the math is the only ongoing constraint.
once you can eyeball this for your gpu, you can pick any model + context combo with confidence. stop being intimidated by the stack.
English

@above_spec I'm on a 2080 , and being able to squeeze it a little bit longer sounds great as right now upgrading does not sound worth it vs cloud models
English
Quick update on the 35B / 8GB setup.
Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context.
And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵

AboveSpec@above_spec
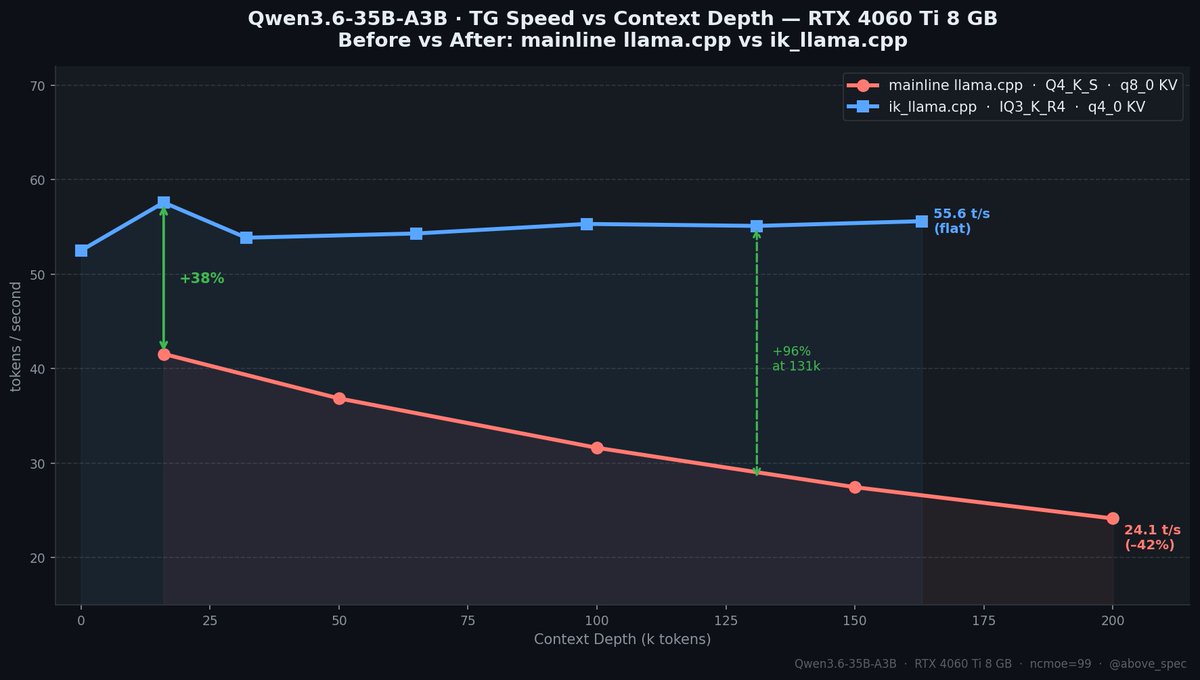
Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU. No, this isn't a server card. It's an RTX 4060 Ti 8GB. Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster. And now the speed doesn't drop with context depth at all. New benchmarks + what changed 🧵
English
@ItsmeAjayKV @ahoenecke You can always have more, I wish I had enough to run Deepseek V4 Pro, lol!
English


I'm getting 120 tok/s on a 3090!
AboveSpec@above_spec
Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU. No, this isn't a server card. It's an RTX 4060 Ti 8GB. Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster. And now the speed doesn't drop with context depth at all. New benchmarks + what changed 🧵
English
Here is the iq4_k_r4 model for this recipe, so you don't have to quantize yourself: huggingface.co/abovespec/Qwen…
English
@witcheer Here is how to get ~50 t/s while having full 262k context with your setup -- 4060 ti 8gb, AM5, DDR5. 50t/s flat across all context. x.com/i/status/20522…
AboveSpec@above_spec
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵
English
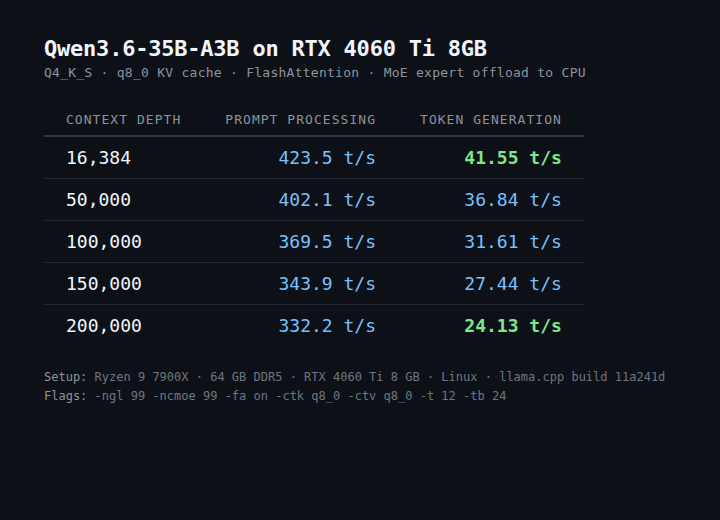
ran tests with Qwen3.6-35B-A3B-UD-Q4_K_M as main local model for Hermes:
>Hardware: RTX 4060 Ti 8GB VRAM, Ryzen 5 7600X, 32GB DDR5-6000
> Model: unsloth/Qwen3.6-35B-A3B-UD-Q4_K_M (22.1 GB on disk, 20.60 GiB GGUF)
>Runtime: llama.cpp llama-server (build b9049-2496f9c14, ggml 0.11.0)
>OS: WSL2 Ubuntu 26.04 on Windows 11
>CUDA: 13.2.1, compute capability 8.9
for Hermes daily use, the optimal config is:
```
-ngl 999 -ncmoe 30 -fa on --cache-type-k q8_0 --cache-type-v q8_0 -c 32768 -t 6
```

witcheer ☯︎@witcheer
study @Teknium: >me asking him the best way to host Hermes on windows >him explaining that WSL2 is the preferred way right now >him sending a previous NousResearch documentation about the set up >him deciding that it is too sparse and reworking the documentation >1 hour later him coming back to me with a very comprehensive tutoral on how tu run Hermes on WSL2 Hermes agent is #1 and there is no second best. for those who are interested in the documentation: hermes-agent.nousresearch.com/docs/user-guid…
English

@mindinpanic Tough to get good performance with 4gb, but you can try your best. Use ik_llama.cpp as it's best for cpu offload.
English

@above_spec sir im poormaxxing can I run something similar on AMD Radeon Pro 5300M with 4GB VRAM and Intel Core i9 and 32bg ram?
English
Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU.
No, this isn't a server card. It's an RTX 4060 Ti 8GB.
Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster.
And now the speed doesn't drop with context depth at all.
New benchmarks + what changed 🧵
English

@above_spec @above_spec that's amazing, what are the rest of the spec's on your rig? CPU / Memory, etc...
English
RTX 5060 Ti 16GB. $429 GPU.
Last night I got 128 t/s on Qwen3.6-35B using ik_llama.cpp's R4 quant format. Crushing performance. Faster than the 5070 Ti on mainline llama.cpp. Performance stays consistent from 0 to 139k context and no speculative decoding used!🤯
Special thanks to @MakJoris for sharing ik_llama.cpp with us!
Today I wanted to know if it's actually *useful* at that speed. So I gave it a coding agent and 4 creative challenges.
Here's what it built. 🧵

English


@above_spec Im trying to find the exact setup llama.cpp repo , settings etc. is there any link to i can read
English
@doktor_DeFi You should get much faster speeds than me, esp if you have dd5
English

Thanks for sharing this stuff. I'm really curious to try it on my 4060ti 16gb. Only 32gb ram and you know I have a zillion tabs open.
Speed looks great but practical assesment and use, how is that holding up? Any trade offs, hallucinations, loops, sub-par results? Are you testing agentic stuff or tool use? Very interested to know.
English
@doktor_DeFi Yeah with 16gb you can offload much less layers to the cpu, test different numbers but ncmoe=20 will work with full context and room to spare. You can probably go down to 10, but need to see how much room for context will be left. Just be sure to use q4 for context.
English

@above_spec NVIDIA GeForce RTX 3080
VRAM: 10 GB
RAM: 32 GB
CPU AMD 9900X
Model Name: Qwen3.6-35B-A3B-i1-Q4_K_S
llama.cpp CUDA cu12.0
GPU Offload: 41 / 41 layers
Context Length: 10240 tokens
KV Cache: q8_0
CPU Threads: 12
Flash Attention: Enabled
Generation Speed: 70.77 tokens/s
English

Qwen 3.6 35B A3B compared to Qwopus 3.6 35B A3B for web design, pretty neck and neck. Some overall good designs.
All one shot, both Q8, 4 designs.
rtx 6000 product page
Transformers 1986
Real estate
Tesla Dashboard
Curious what others think. Will be doing 35B vs 27B next.
English