@seti_park @yunta_tsai Visual-based automatic wipers are indeed more difficult to solve than visual-based autonomous driving.😆😆😆
English
Ryan Wang 🇹🇼
6K posts

@ryanwang
An individual Investor from Taiwan who focus on Tech, AI, autonomy, and robotics.

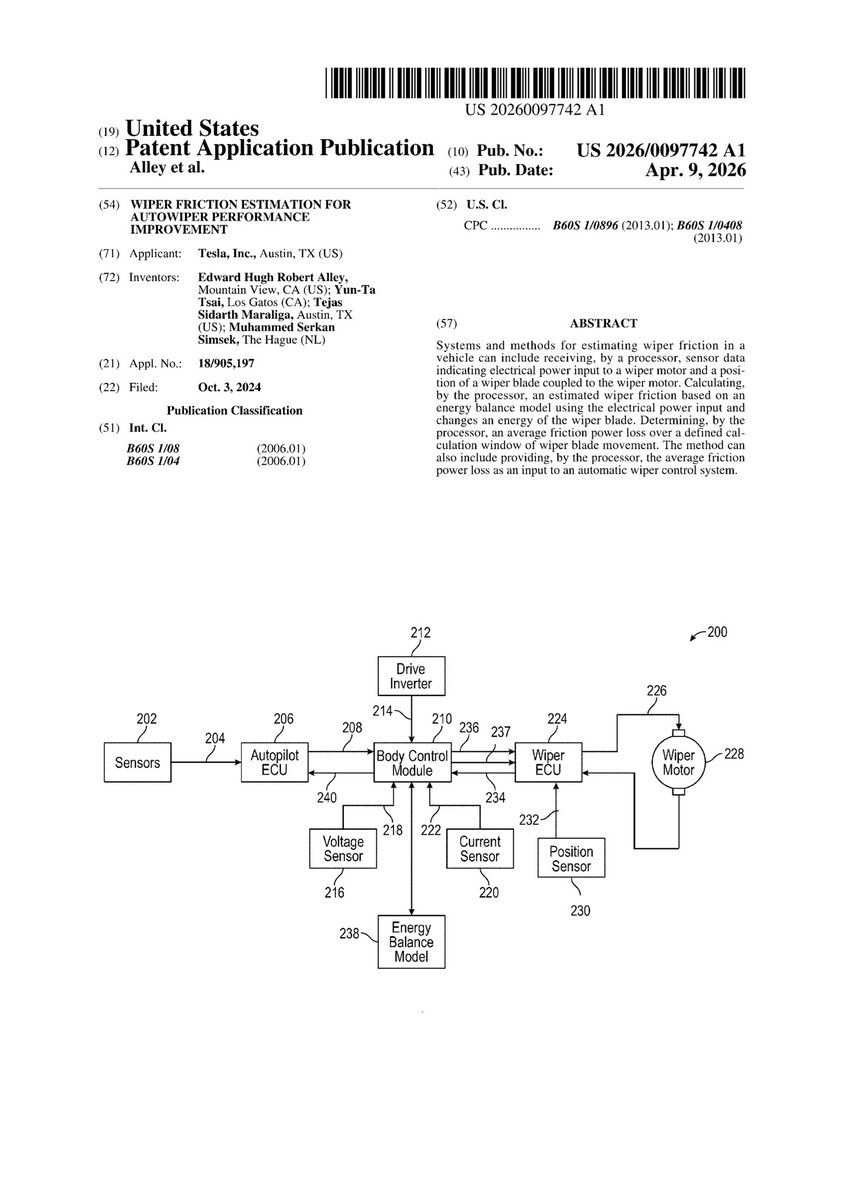
제일 해결안되는 FSD 엣지케이스 : Auto Wiper



@Chansoo Our rate of advancement with the small model has been so fast that the large model has not yet caught up. V15 will be the large model.




Tesla V14.3 self-driving review. The point releases will bring polish. V15 will far exceed human levels of safety, even in completely unsupervised and complex situations.