Alex Dimakis@AlexGDimakis
The multiple answers mystery is the most surprising thing we stumbled on from OpenThoughts:
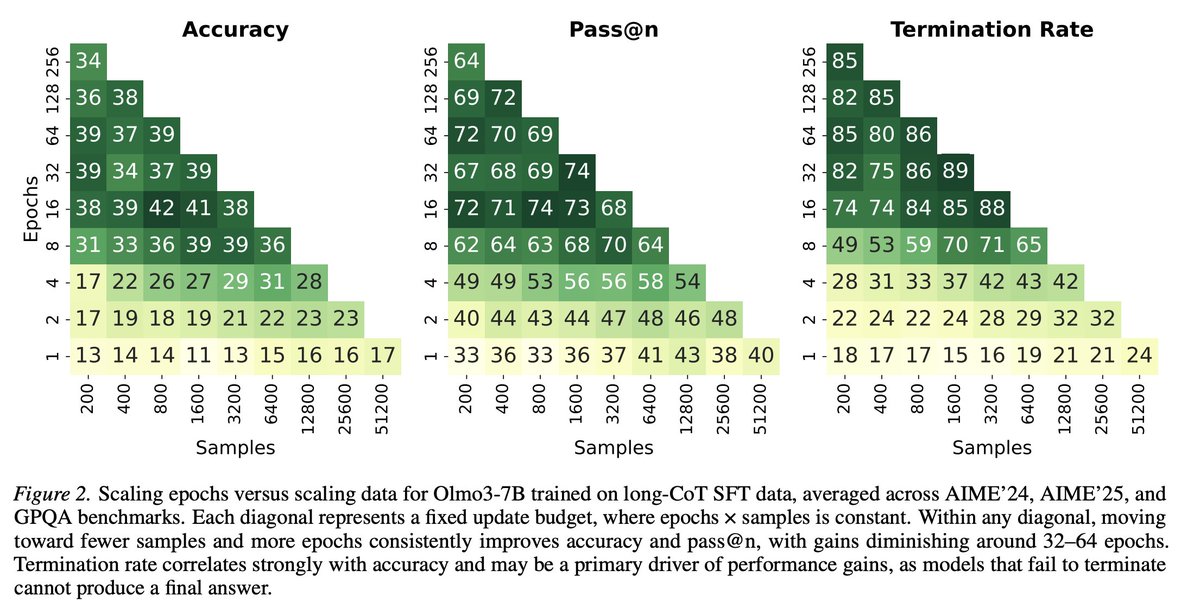
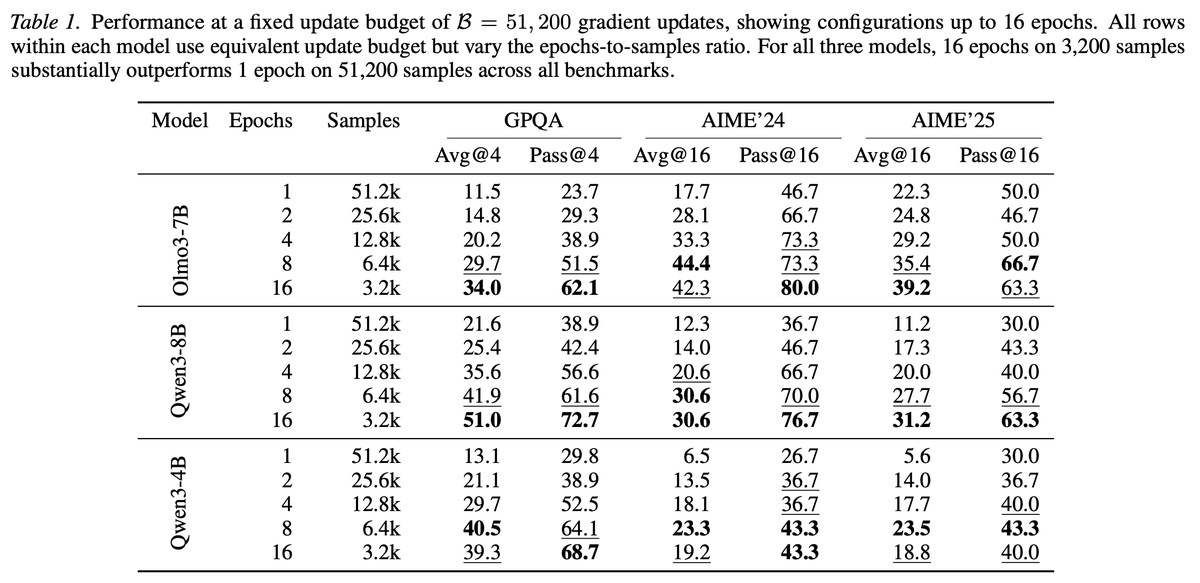
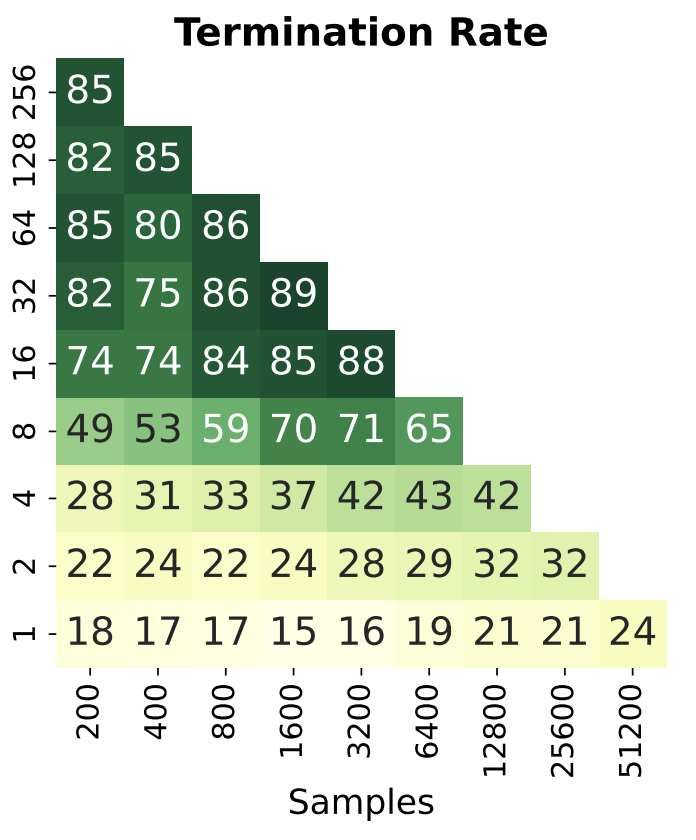
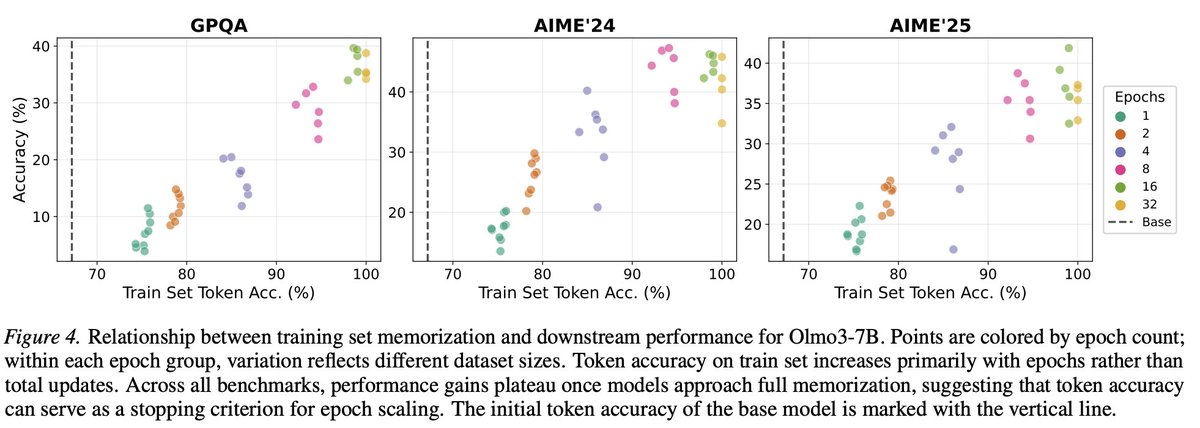
Sampling multiple answers for the same question is better than having more questions, each answered once.
To explain: Say you are creating a dataset of questions and answers to SFT a reasoning llm.
You can take 1000 questions (eg from stackexchange) and answer them with deepseekR1.
Or you can take 500 questions (from the same distribution) and answer each question *twice* independently with deepseekR1.
Which one is a better dataset? Surprisingly, if you re-answer the same questions , it’s a better dataset for distillation (at the same size) and this was a robust finding from OpenThoughts across models and data sources.
We have no theoretical understanding why, and no way to predict how many times to repeat. Clearly it must stop at some point (take one question and answer it 1000 times won’t be a good SFT dataset) but we don’t know how to predict this, beyond empirically trying.