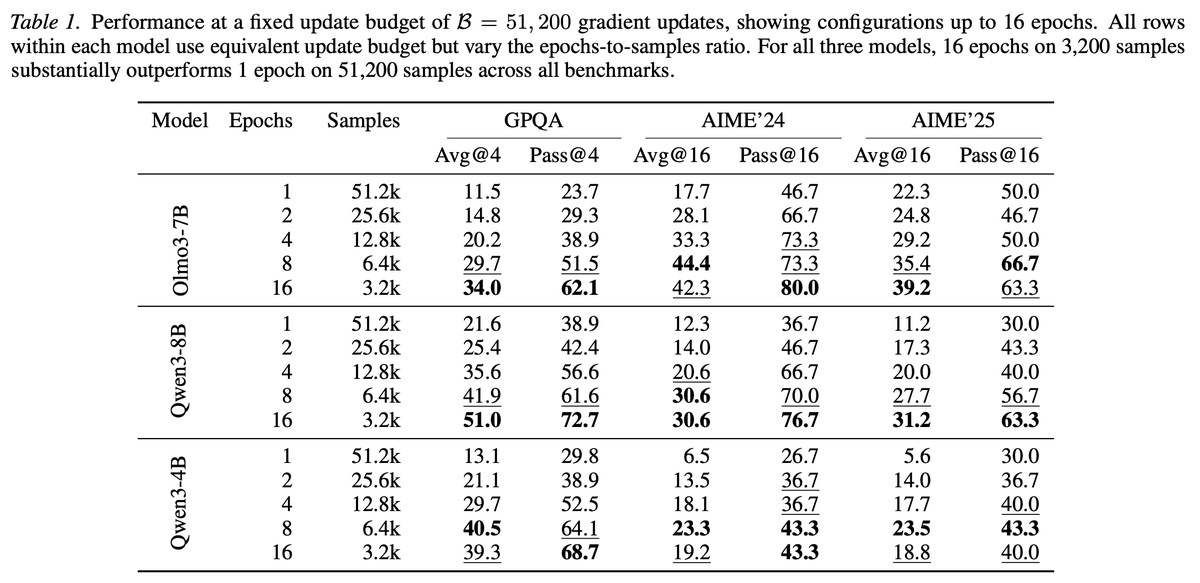
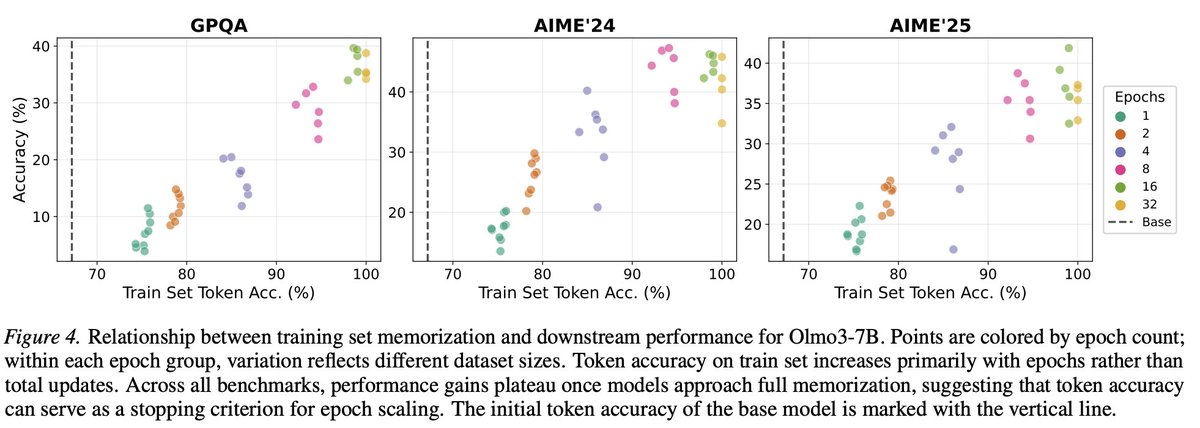
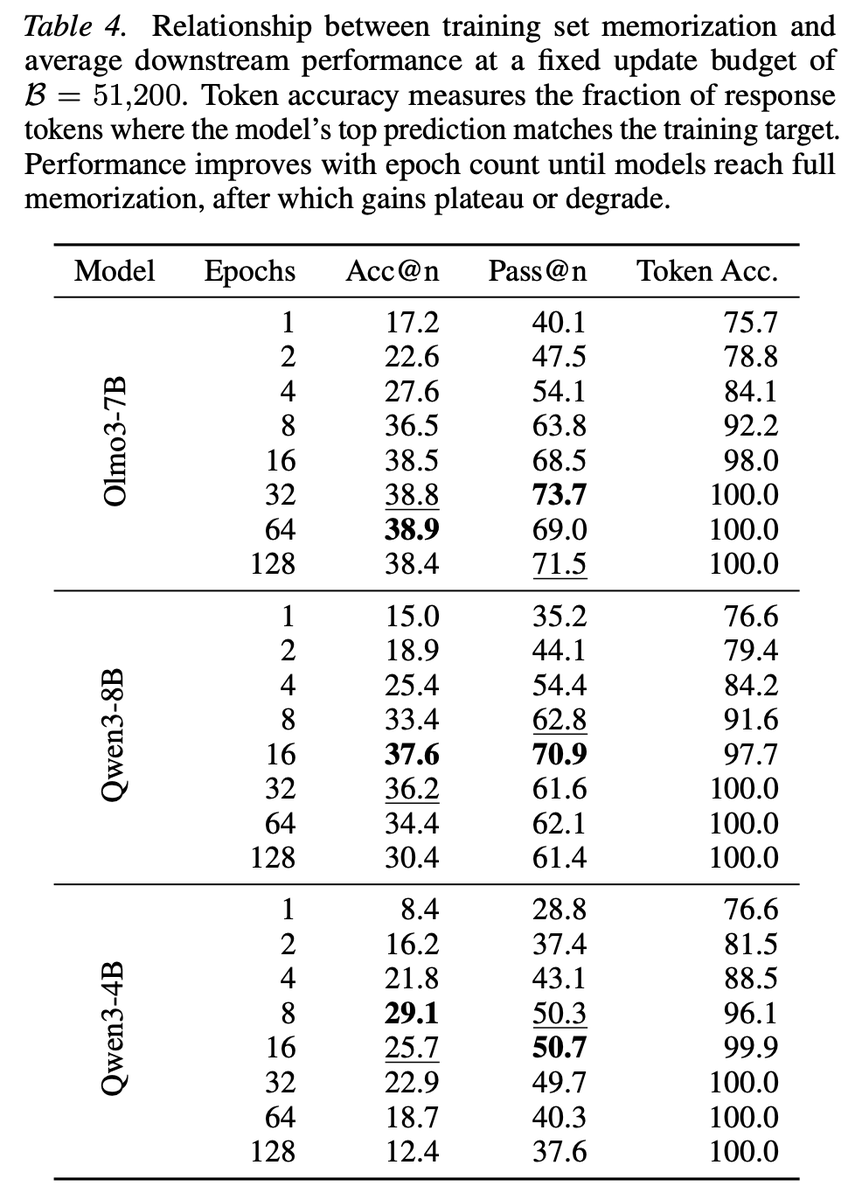
Sabitlenmiş Tweet

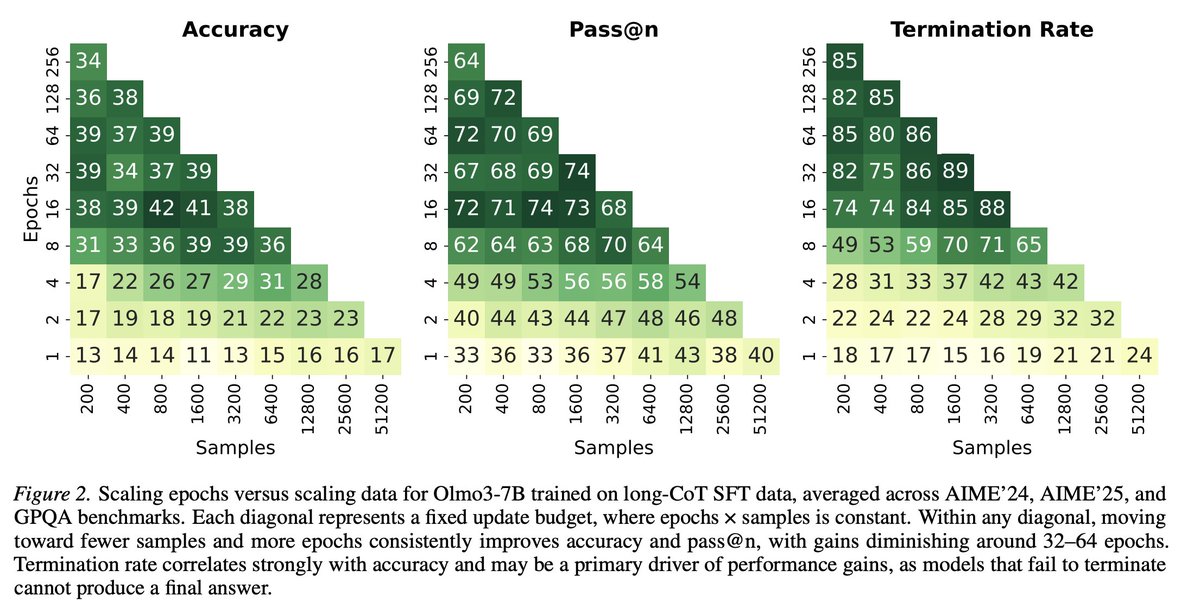
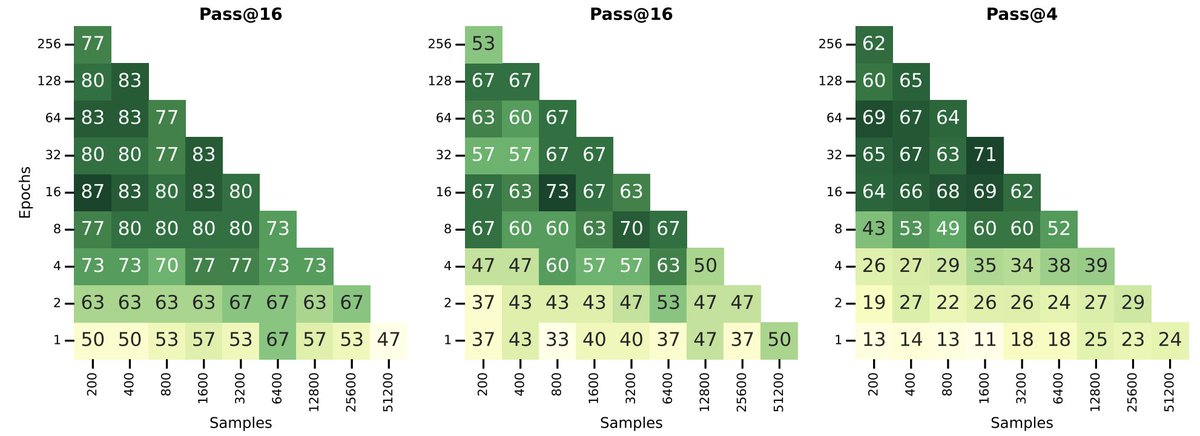
Why repetition works so well is still an open question. There's a lot to uncover about training dynamics of SFT, and we hope this is a useful data point.
Joint work with co-authors @Sagar_Vaze @TiRune @y_m_asano
Paper: arxiv.org/abs/2602.11149
Code: github.com/dkopi/data-rep…
English