
c. mcdonnell
125 posts






@torchcompiled absurdly sparse fails on quantizing for me but could be implementation error
English

At 16MB i feel like a winner would be absurdly sparse, thinking Fastfood Layers, pushing recurrence to the max, random projections which can be retrieved by storing seed, butterfly matrices, and exploiting ops like FFT.
Feels like anything else would be a marginal gain.
Vuk Rosić 武克@VukRosic99
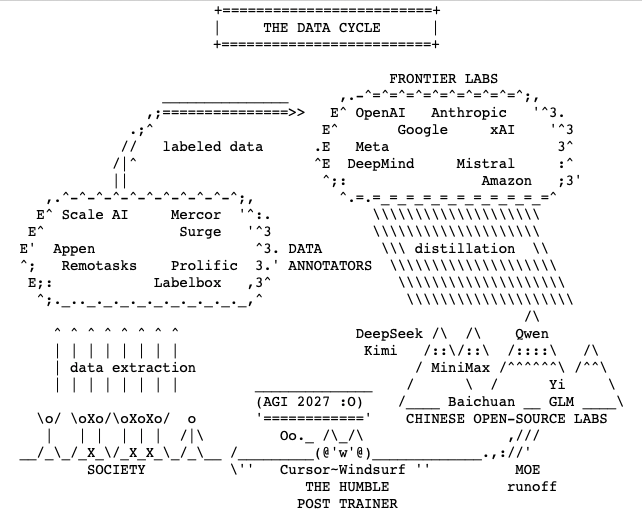
i did quick 71 experiments for 500 out of 13,000 steps for OpenAI's challenge 1. Mixture of Experts is absolute WINNER (very surprising as it shouldn't be for small LLMs) > Expert count matters most. 4 (best) > 3 >> 2. 2. UNTIED Embeddings work, tied are disaster 3. Depthwise Convolution - DEAD END Insights: 1. 4-expert MOE + leaky ReLU -> -0.048 BPB, clear winner 2. Untied factored embeddings (bn128) -> -0.031 BPB, worth combining with MOE 3. MOE + QAT combo -> preserves quantized quality for submission dead ends 1. Depthwise convolution -> every variant hurts, bigger kernels hurt more 2. Tied factored embeddings -> catastrophic, especially at small bottlenecks 3. Weight sharing -> not competitive with MOE for quality 4. Conv + anything combos — compounds the damage Next Steps 1. Validate MOE 4e + leaky at 2000-5000 steps, multiple seeds 2. Test MOE 4e + leaky + untied bn128 — the two biggest wins may stack 3. Full run (13780 steps) of best combo to see if it beats 1.2244 BPB leaderboard 71 experiments, 3 GPUs, ~500 steps each. Vuk Rosić 500 step training mainly helps us eliminate VERY BAD losers, winners need to be tested on longer training. Thank you @novita_labs for compute!
English
@hoverdesign hyper constrained ML! final model can't be bigger than 16mb and training time is capped at 10min
English

@cmcdnd @willdepue Super curious to know what you’re learning.
English

@bryan_caplan Expand your concept of self to include big things.
English

Don't believe in anything "bigger than yourself."
Instead, become big enough for you to believe in yourself.
English


@viemccoy It's almost like we don't even have capital S Science without the faith & magic. Autism is not a fair replacement, we really need Pascals again.
English


English

@CatOrman1 Imagine a 200 person 3 day weekend destination wedding @bankof_amERICA
English


everything 👏 is 👏 monocausal 👏 and 👏 specifically 👏 results 👏 from 👏 whatever 👏 shit 👏 I'm 👏 on 👏 about 👏 at 👏 any 👏 given 👏 time
English
@signulll They're annoying but zoom calls and panels are what we have left of French/English ritualized social theater. Cling on, we don't want them entirely gone.
English


So much AI hysteria is driven by the class envy and aspiration of public intellectuals:
Basically if it’s an existential threat like the nuclear bomb, it must be controlled by priests/intellectuals and their client managerial class.
But if it’s just a very powerful tool, it will simply increase the power of crass capitalists.
English
@doodlestein @IterIntellectus Inulin?? How is your system handling that without massive bloat
English

@IterIntellectus I just mix this into milk with my creatine and some vanilla syrup. Very painless and easy.
English

if you read enough fiber research you either start thinking you’re going insane or realize the entire nutrition industry has a financial incentive to keep you buying protein powder instead.
you need to eat your fiber and i’m not even trying to be nice about it.
95% of Americans are *deficient* while enough fiber alone reduces all-cause mortality by 30%, colorectal cancer by 26%, and your gut bacteria literally digest your own intestinal lining when you starve them of it.
fiber should be a bigger supplement category than protein but since it actually makes you healthier there’s no interest in selling it
Zero HP Lovecraft@0x49fa98
The more you look at actual nutrition and health science, the more fixated you become on fiber intake
English

@owroot not a completely fair comparison because it's regular vs. semilight (I don't have regular Times Now)
But look at the refreshed Times- so beautiful

English



this is why i wish the tech/sci fi film canon were wider. im tired of references to Her and Bladerunner and The Social Network etc. in 2026 you should be watching:
-Demonlover
-Until the End of the World
-Videodrome
-World on a Wire
-Solaris
-The 10th Victim
-Megalopolis
-Stalker
-Run, Lola, Run
-Seconds
-and so many more…




scott belsky@scottbelsky
films set the ideas and narratives that kick-off passions and careers
English
