Angehefteter Tweet
Weiting (Steven) Tan
77 posts


Weiting (Steven) Tan
@weiting_nlp
Ph.D. Candidate at @jhuclsp, Student Researcher @Bytedance Seed | Prev @AIatMeta @Amazon Alexa AI
USA Beigetreten Temmuz 2021
311 Folgt213 Follower


I’m super thrilled and honored to be named an Amazon AI PhD Fellow 💫
Huge thanks to @AmazonScience for generously supporting our research at JHU! We’ll be advancing AI alignment in collaboration with folks at Amazon.
Rohit Prasad@RohitPrasadAI
Excited to announce @amazon's new AI PhD Fellowship Program supporting 100+ students across 9 universities like Carnegie Mellon, MIT & Stanford. Fellows will be paired with senior scientists working in related fields, plus receive financial support and AWS credits for research. Learn more: amazon.science/news/amazon-la…
English
Weiting (Steven) Tan retweetet

Exploration is fundamental to RL. Yet policy gradient methods often collapse: during training they fail to explore broadly, and converge into narrow, easily exploitable behaviors. The result is poor generalization, limited gains from test-time scaling, and brittleness on tasks where strategic exploration is necessary. We introduce a framework for training a policy over sets of generations and use it to induce exploration.
Work with @ifdita_hasan (co-lead), @ellenjxu_ , @chelseabfinn and @DorsaSadigh at Stanford 🧵

English
Weiting (Steven) Tan retweetet

Most RL for LLMs today is single-step optimization on a given state (e.g., an instruction), which is essentially a bandit setup. But to learn a meta-policy that can solve various bandit problems via in-context trial and error, you need true multi-turn RL over a long horizon. So, can RL & SFT teach LLMs a meta-bandit policy to explore in-context? 🤔
The regret-based benchmarks screamed YES! But … real story is more complex. We discovered a surprising phenomenon “When Greedy Wins.”
(1/5) 🧵

English
This research was made possible by my fantastic collaborators and mentors at @jhuclsp and Bytedance Seed Speech: @XinghuaQu, @tuming628, Meng Ge, Andy T. Liu, Philipp Koehn, Lu Lu.
Paper: arxiv.org/pdf/2509.14480
Code and data will be released shortly.
English
We also explored several other strategies, such as entropy-related changes in the loss function, forcing self-reflection during rollout, and more fine-grained reward assignment with PPO. However, they do not work well as intended. Please check our analysis section for details.
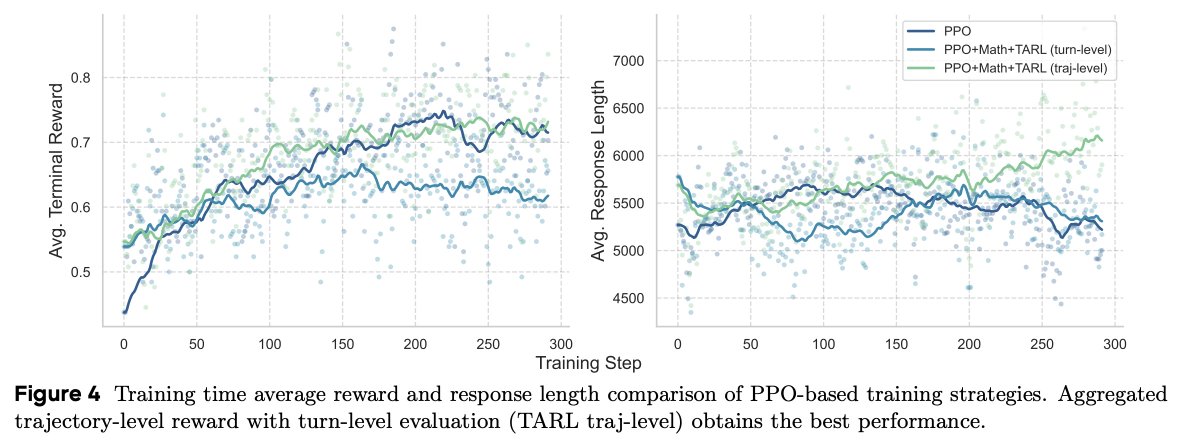
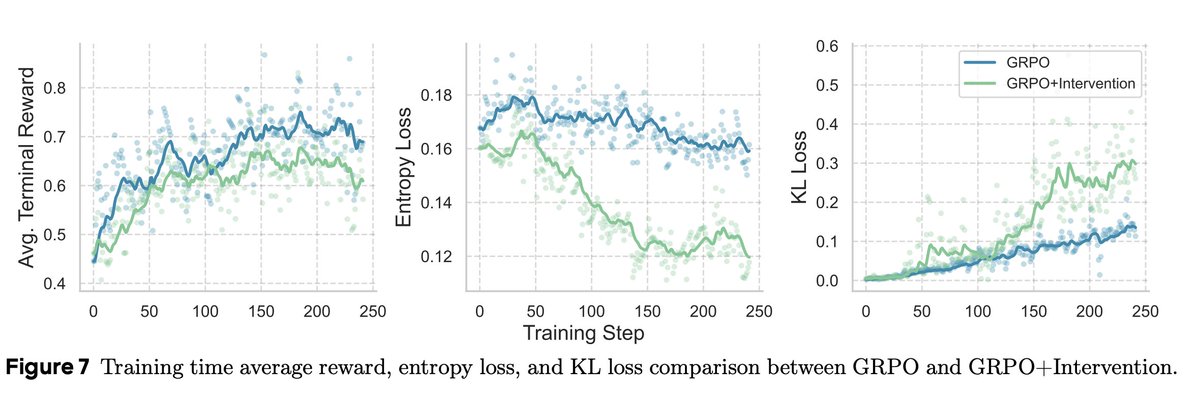
English
Training multimodal voice agents is even tougher. To get them up to speed, we designed a two-part strategy:
1️⃣ A "warm-up" curriculum on simplified tasks to build core tool-calling skills.
2️⃣ Mixed-modality training with interleaved speech-text rollouts
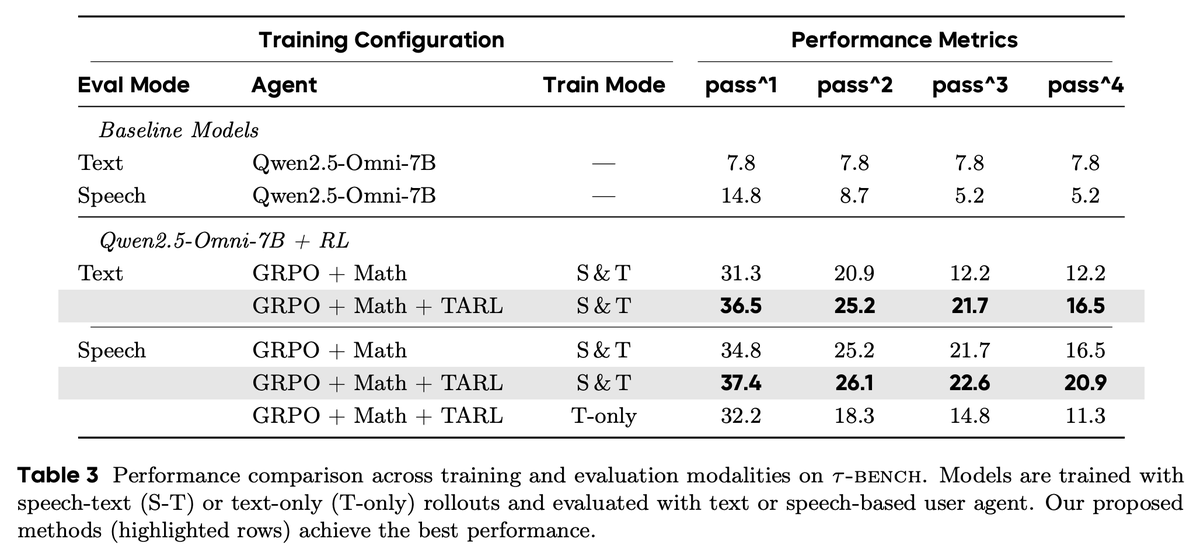
English
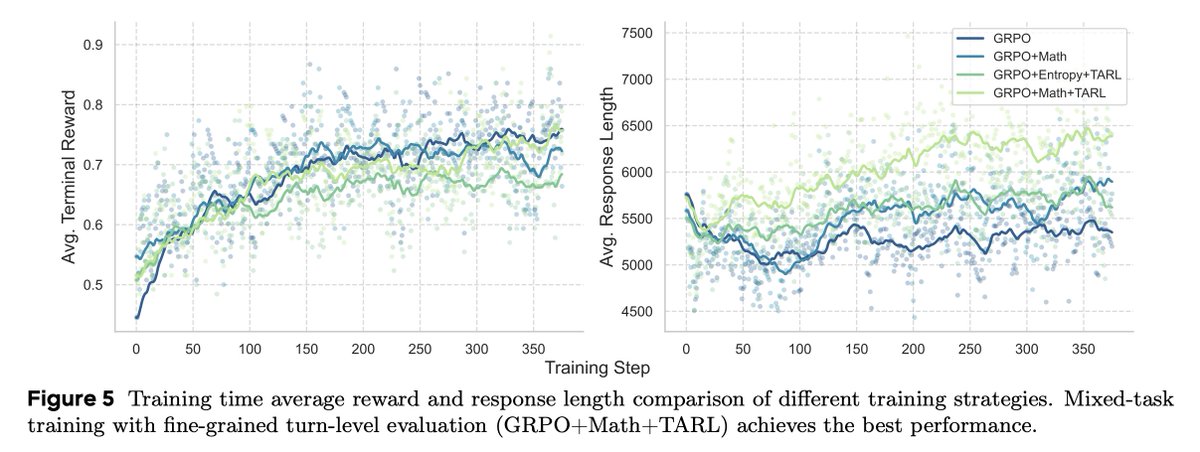
Vanilla RL struggles with exploration & credit assignment. We tackle this with:
1️⃣ Mixed-task training (w/ math) to keep the agent curious.
2️⃣ Turn-level Adjudicated RL (TARL), which uses an LLM-judge for precise turn-level feedback.

English
Weiting (Steven) Tan retweetet

Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n

English
Weiting (Steven) Tan retweetet

🚀 Excited to finally share our paper on VerlTool, released today after months of work since the initial release in late May!
VerlTool is a high-efficiency, easy-to-use framework for Agentic RL with Tool use (ARLT), built on top of VeRL. It currently supports a wide range of tools (including multimodal ones) such as code interpreter, FAISS retriever, Google Search, Bash terminal, SQL executor, image processing, SWE, and more. For each tool, we provide training recipes and detailed analysis, with all code designed to be reproducible and runnable on a single node.
A key design choice is the separation of the RL workflow and the tool server. Every trajectory sends tool calls via a well-designed API interface after encountering an action stop token. The tool server handles requests with either multi-threading or Ray, ensuring high concurrency and stable resource management—for example, our math experiments run stably past 1k steps.
Our goal with VerlTool is to make it easy for the community to add new tools in ARLT training. Developers only need to inherit from BaseTool and adapt minimal code. In fact, you could even give the BaseTool file to GPT/Claude and get almost plug-and-play code.
We also explored important technical issues in Agentic RL, such as how much async rollouts can actually speed things up, or how tool response tokenization may cause off-policy drift. We hope these insights, while modest, can be useful for the community.
📄 HuggingFace Daily Paper: huggingface.co/papers/2509.01…
🛠️Github: github.com/TIGER-AI-Lab/v…
More details: (0/5)👇

Dongfu Jiang@DongfuJiang
Introducing VerlTool - a unified and easy-to-extend tool agent training framework based on verl. Recently, there's been a growing trend toward training tool agents with reinforcement learning algorithms like GRPO and PPO. Representative works include SearchR1, ToRL, ReTool, and ToolRL. While these achieve impressive performance, their training codes are either not fully open-sourced or too difficult to modify and customize with new tools, creating unexpectedly high engineering costs for the community when exploring new ideas. To address these issues and reduce engineering overhead, we propose verl-tool. Key Features: 1. 🔧 Complete decoupling of actor rollout and environment interaction - We use verl as a submodule to benefit from ongoing verl repo updates. All tool calling is integrated via a unified API, allowing you to easily add new tools by simply adding a Python file and testing independently. 2. 🌍 Tool-as-environment paradigm - Each tool interaction can modify the environment state. We store and reload environment states for each trajectory. For each training, you can launch 3. ⚡ Native RL framework for tool-calling agents - verl-tool natively supports multi-turn interactive loops between agents and their tool environments. 4. 📊 User-friendly evaluation suite - Launch your trained model with OpenAI API alongside the tool server. Simply send questions and get final outputs with all interactions handled internally. We've successfully reproduced ToRL results using our verl-tool framework, demonstrating its correctness and demonstrating comparable performance on mathematical benchmarks. VerlTool is an active ongoing project! We aim to incorporate more tools covering a wide range of use cases and expect they can be trained together in a single framework. Suggestions and contributions are highly welcomed! Check out our GitHub: github.com/TIGER-AI-Lab/v… More details: 👇 (0/4)
English
Weiting (Steven) Tan retweetet

🌀Diversity Aware RL (DARLING)🌀
📝: arxiv.org/abs/2509.02534
- Jointly optimizes for quality & diversity using a learned partition function
- Outperforms standard RL in quality AND diversity metrics, e.g. higher pass@1/p@k
- Works for both non-verifiable & verifiable tasks
🧵1/5

English
Many thanks to my collaborators @LianJiachen , @HirofumiInaguma , Paden Tomasello, Philipp Koehn, @xutai_ma
For details, please refer to the artifacts below:
📄 Paper: arxiv.org/pdf/2508.16188
🔗 Code: github.com/steventan0110/…
This work was done at @jhuclsp and @AIatMeta
English
Can a model "see" emotion to "speak" with emotion? Yes! 🗣️
Our new work on Audio-Visual LMs shows that adding a visual stream makes generated speech more expressive. Check out our #EMNLP2025 Findings paper to see how we did it.
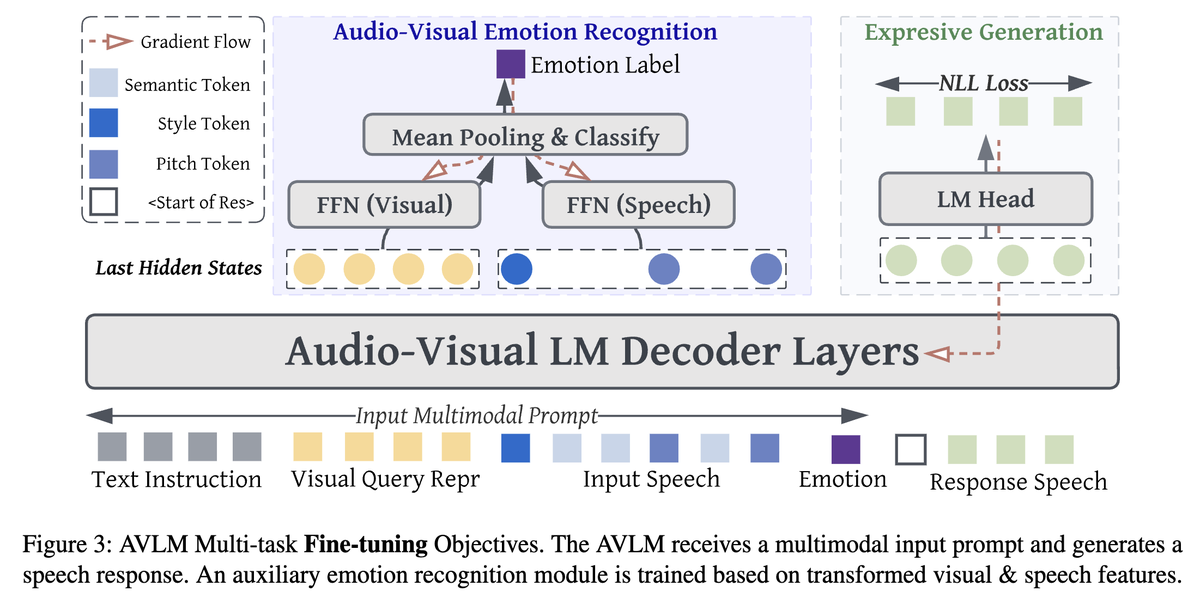
English
Weiting (Steven) Tan retweetet

Our latest on compressed representations: Key-Value Distillation (KVD). Query-independen transformer compression, with offline supervised distillation.

English
Weiting (Steven) Tan retweetet

🛠️ DeepSeek-R1: Technical Highlights
📈 Large-scale RL in post-training
🏆 Significant performance boost with minimal labeled data
🔢 Math, code, and reasoning tasks on par with OpenAI-o1
📄 More details: github.com/deepseek-ai/De…
🐋 4/n

English
Weiting (Steven) Tan retweetet

Congratulations to Prof. Philipp Koehn on being named a Fellow of the @aclmeeting! cs.jhu.edu/news/philipp-k…
English
@FeitengLi Thanks for your interests! We will open-source it once the paper is accepted somewhere and pass the internal legal review (as this work is done within Meta)
English

Looking for a better way to fuse speech and text modality with pre-trained large language models?
Check out our paper: SSR: Alignment-Aware Modality Connector for Speech Language Models 💡
🔗 arxiv.org/abs/2410.00168
#SpeechLM #ModalityFusion

English
I had a great time helping host MASC-SLL at Hopkins last year. MASC-SLL is a great opportunity to connect with fellow AI/NLP/Speech researchers.
If your organization is in the Mid-Atlantic region and is interested in hosting the event, please reach out!
MASC-ALL Conference@MASC_Conference
📢 Want to host MASC 2025? The 12th Mid-Atlantic Student Colloquium is a one day event bringing together students, faculty and researchers from universities/industry in the Mid-Atlantic. Please submit this very short form if you are interested in hosting! Deadline January 6th
English
Weiting (Steven) Tan retweetet

I have written a blogpost offering an explanation of why both the chosen and the rejected log-probability decreases during DPO, and more interestingly, why it is a desired phenomenon to some extent.
Link: tianjianl.github.io/blog/2024/dpo/
English
Weiting (Steven) Tan retweetet

Very happy to hear that GANs are getting the test of time award at NeurIPS 2024.
The NeurIPS test of time awards are given to papers which have stood the test of the time for a decade.
I took some time to reminisce how GANs came about and how AI has evolve in the last decade.
English