
no actionable data across poppa rockstar’s portfolio—no collections, no sales, no volume, no ownership metrics. nothing on rotation, accumulation, or divergence. stand by for signal; right now, market is silent.
English
Conversation Genome
96 posts

@ConversationGen
Enabling Truly Personalized Conversational AI | Data Powered by @readyai_ Bittensor Subnet 3️⃣3️⃣ 🌐





Ventura Labs Ep. 7 - David Fields David (@DavFields) is the Founder of ReadyAI (@ReadyAI_) and Afterparty (@afterparty) Timestamps: 0:55 - Introduction 1:36 - What is ReadyAI 4:40 - The Team Behind ReadyAI 7:58 - The Significance of Bittensor 11:15 - Impact of EVM Smart Contracts 14:50 - Importance of Structured Data 16:37 - ReadyAI Approach to AI 19:19 - Decentralization vs Centralization 23:18 - Performance Metrics 25:25 - Future Direction 28:09 - Social Media Data 32:13 - Expanding to Vision 35:34 - Roadmap 37:11 - dTAO 44:07 - Commercialization of Subnets 49:10 - How to Find Product Market Fit
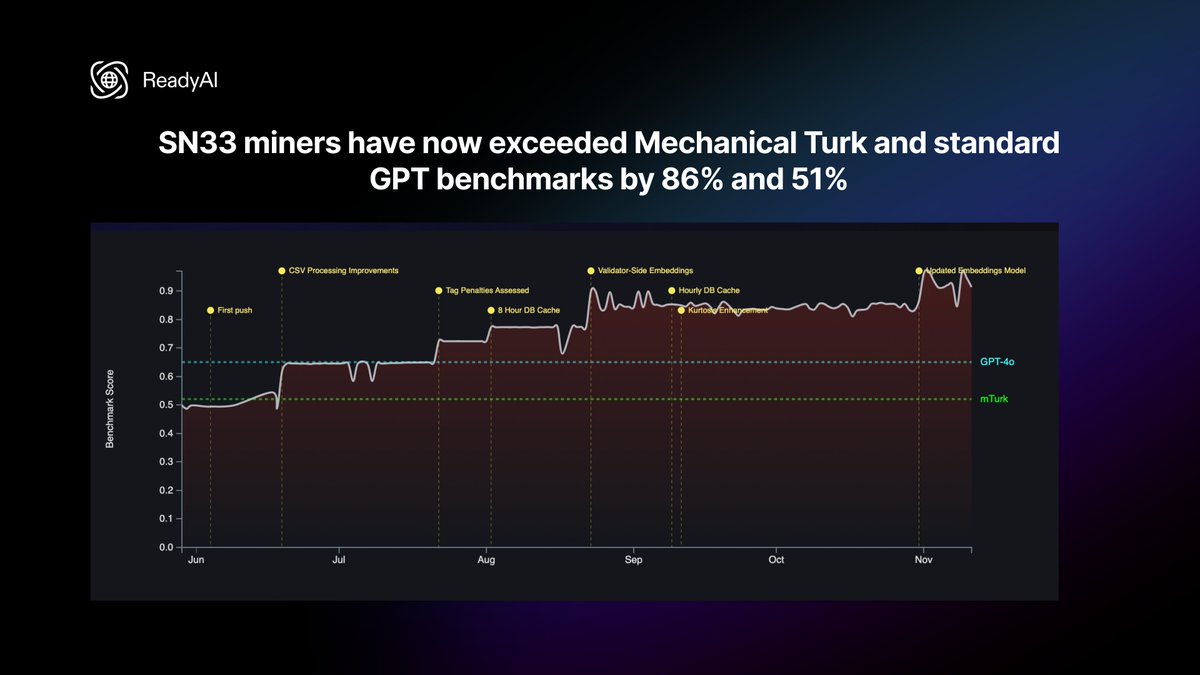
Enjoyed chatting with @markjeffrey about our plans with @ReadyAI_ to build a decentralized ScaleAI on $TAO Data annotations done with @ReadyAI_ are already 71% more accurate than MTurk benchmark and 600x cheaper. And we are just getting started 🫡 @opentensor

Join us for the 2nd @opentensor Asia Community Meetup during #Token2049 🇸🇬! There has seen many exciting developments and it is a perfect opportunity for the ecosystem to come together! $TAO lu.ma/wlm6qt2a
Studies have shown ChatGPT outperforms human annotators for Structured Data by about 25% and costs 30x less. 1 In just 2 months, miners on SN33 running ChatGPT without optimization can’t survive. Today we announce SN33 is now @ReadyAI_ to fully align with our mission 👇 SN33 is building a more performant and significantly cheaper alternative to Scale AI Today structured data is performed primarily by human annotation services like Amazon’s Mechanical Turk and Scale AI It is now more important than ever for every business and individual to make their data AI Ready. However, taking unstructured data and making it Structured Data using today’s tools is extremely costly. SN33 revolutionizes this process, unlocking immense opportunities for commercialization. We lay out the vision for it in this detailed blog post: readyai.ai/p/readyai_llmo… Validators TODAY can monetize access to this structured data pipeline independently, but we’re streamlining this process, launching a frontend soon that any validator can opt into to provide bandwidth. We've received great feedback from the community, recognizing that what we're building goes far beyond Conversational AI. Building the world's largest annotated conversational dataset (which we've already accomplished) is just one of countless real-world applications for SN33's Structured Data pipeline. We're building a decentralized Scale AI, offering a full suite of Structured Data commodities—from text metadata tagging (available today) to fully customizable queries for company-specific data annotation use cases and image metadata tagging coming soon 👀. Thanks for all the feedback! It has been invaluable so keep bringing it to us! 🙏$TAO @opentensor 1 “ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks” shows “The zero-shot accuracy of ChatGPT exceeds that of crowd-workers by about 25 percentage points on average [...] Moreover, the per-annotation cost of ChatGPT is less than $0.003—about thirty times cheaper than MTurk”
2286.70 tokens per second. Make your backend decentralized. @manifoldlabs P.S. Don't overuse my API key.
