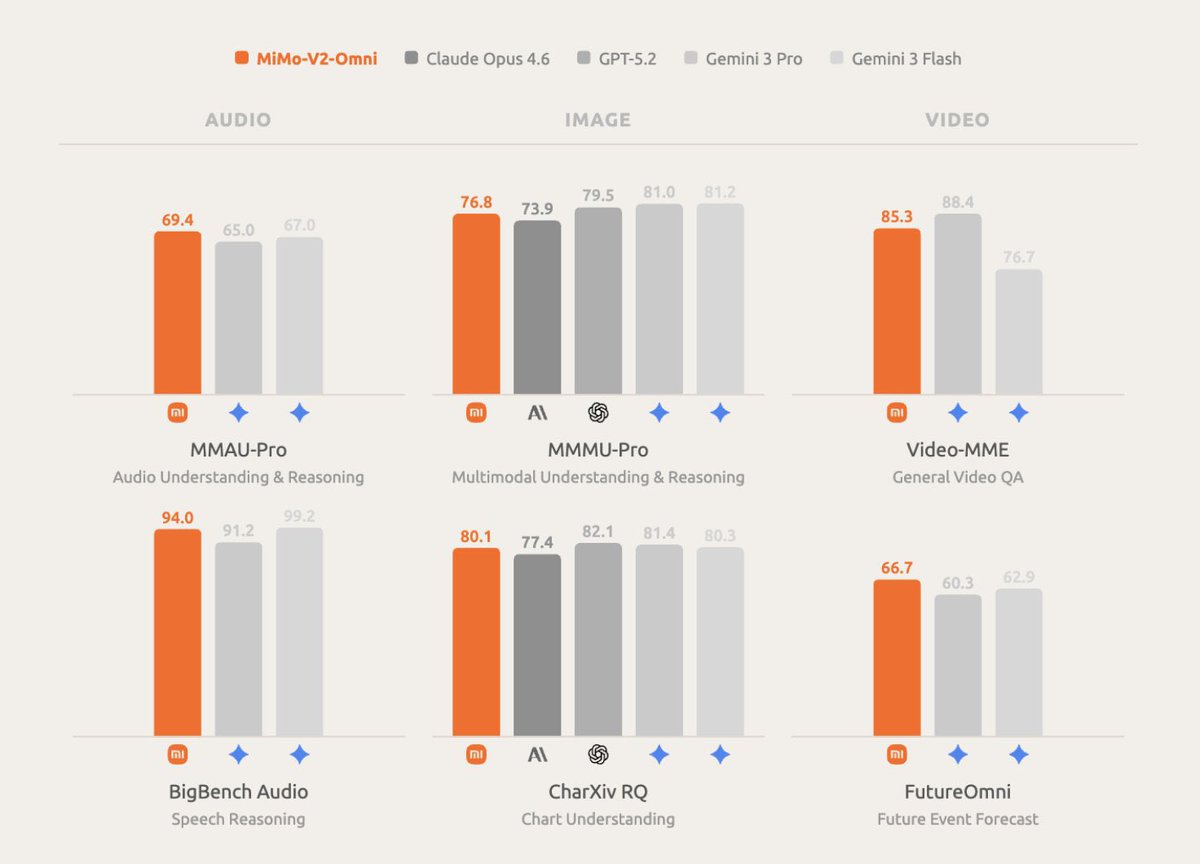
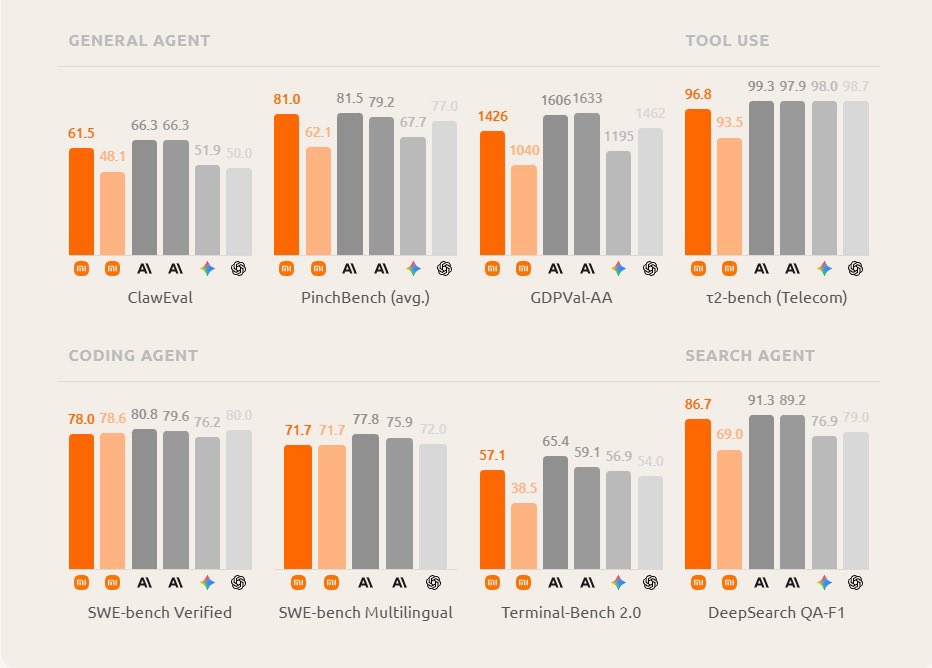
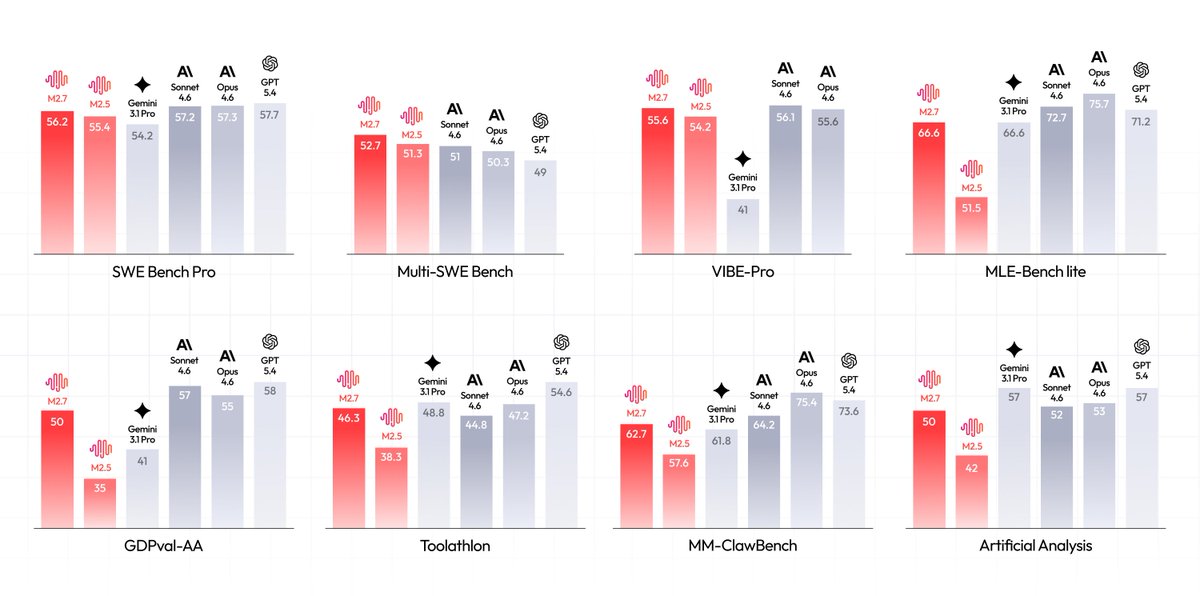
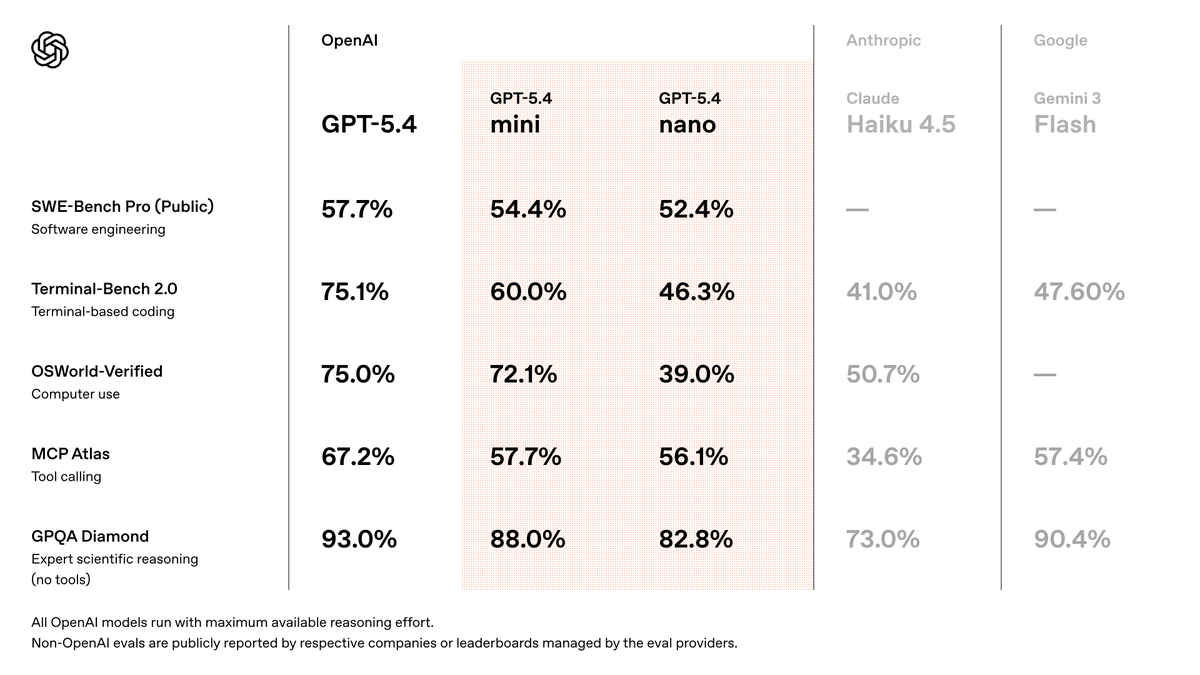
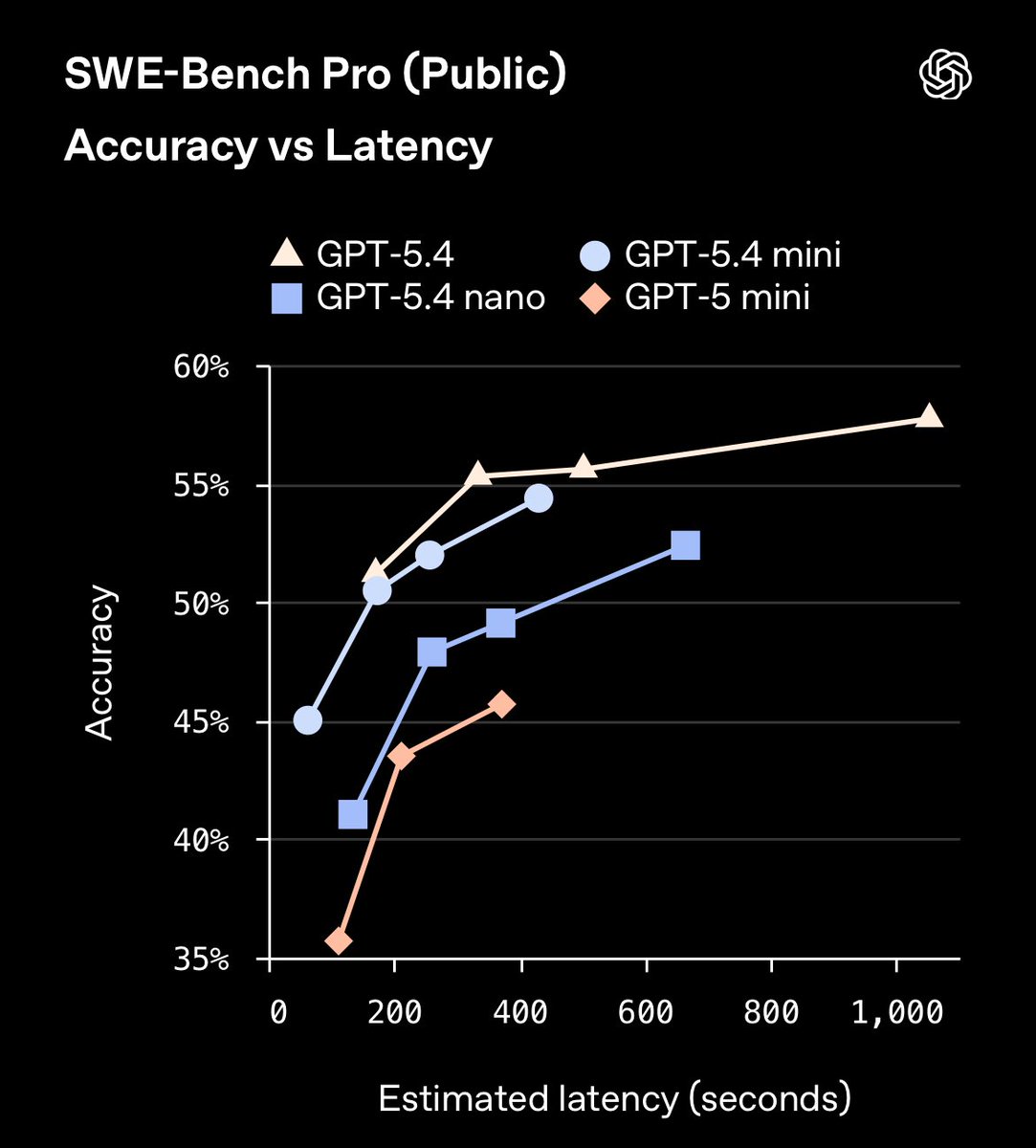
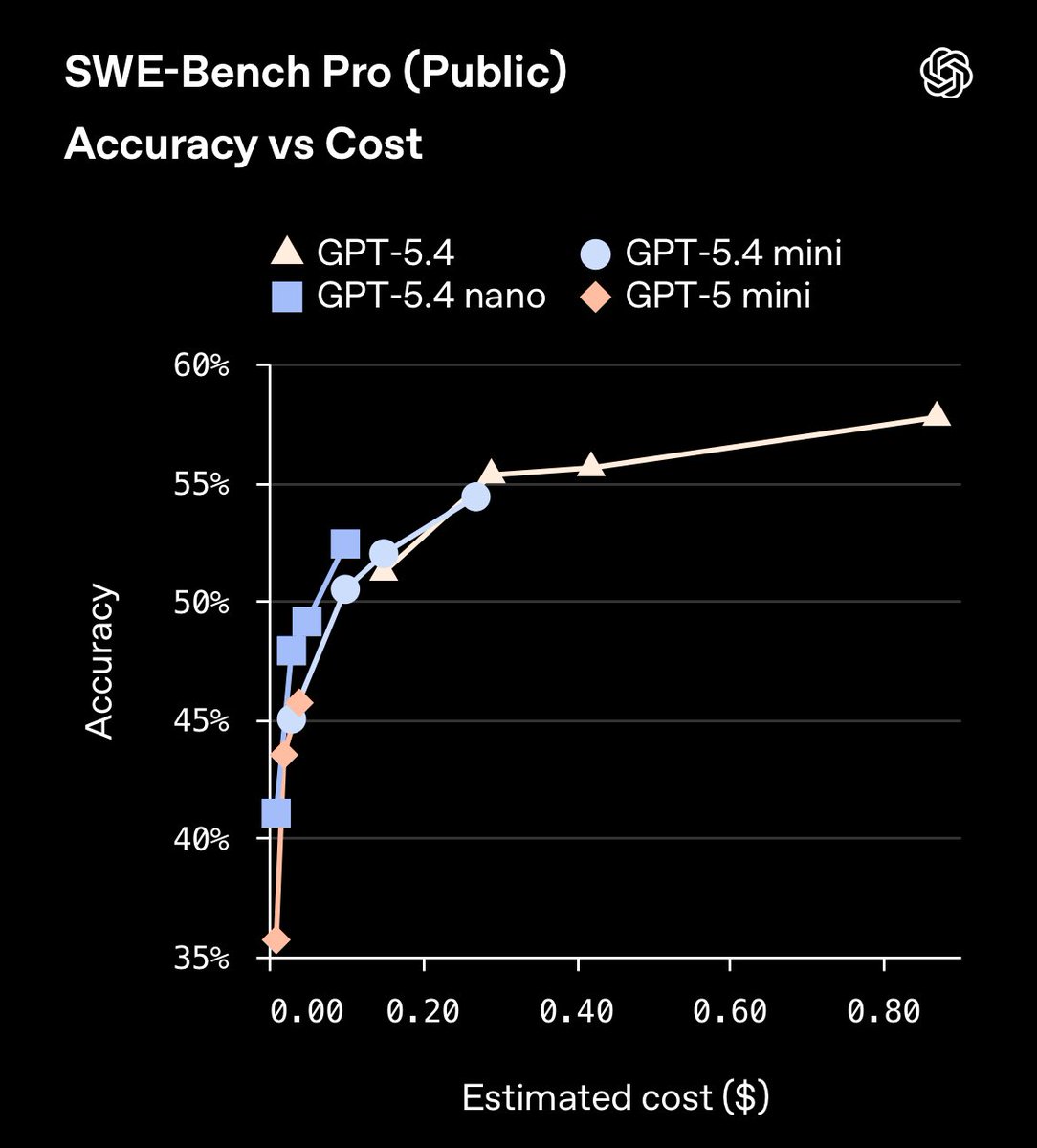
Pinned Tweet

⬜️⬜️⬜️ ⬜️
⬜️ ⬜️
⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️
⬜️ ⬜️ ⬜️ ⬜️ ⬜️ ⬜️
⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️ ⬜️ ⬜️⬜️⬜️ ◻️◻️
./ training mode on… @Gradient_HQ
English