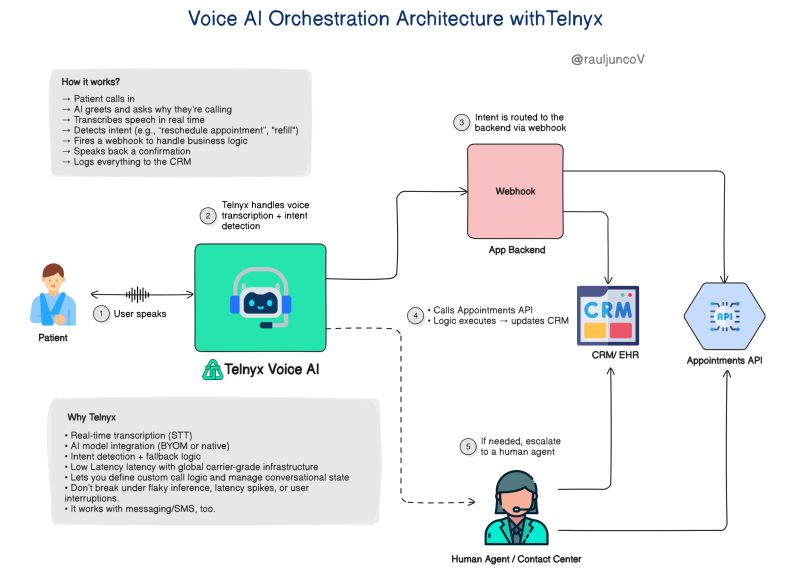
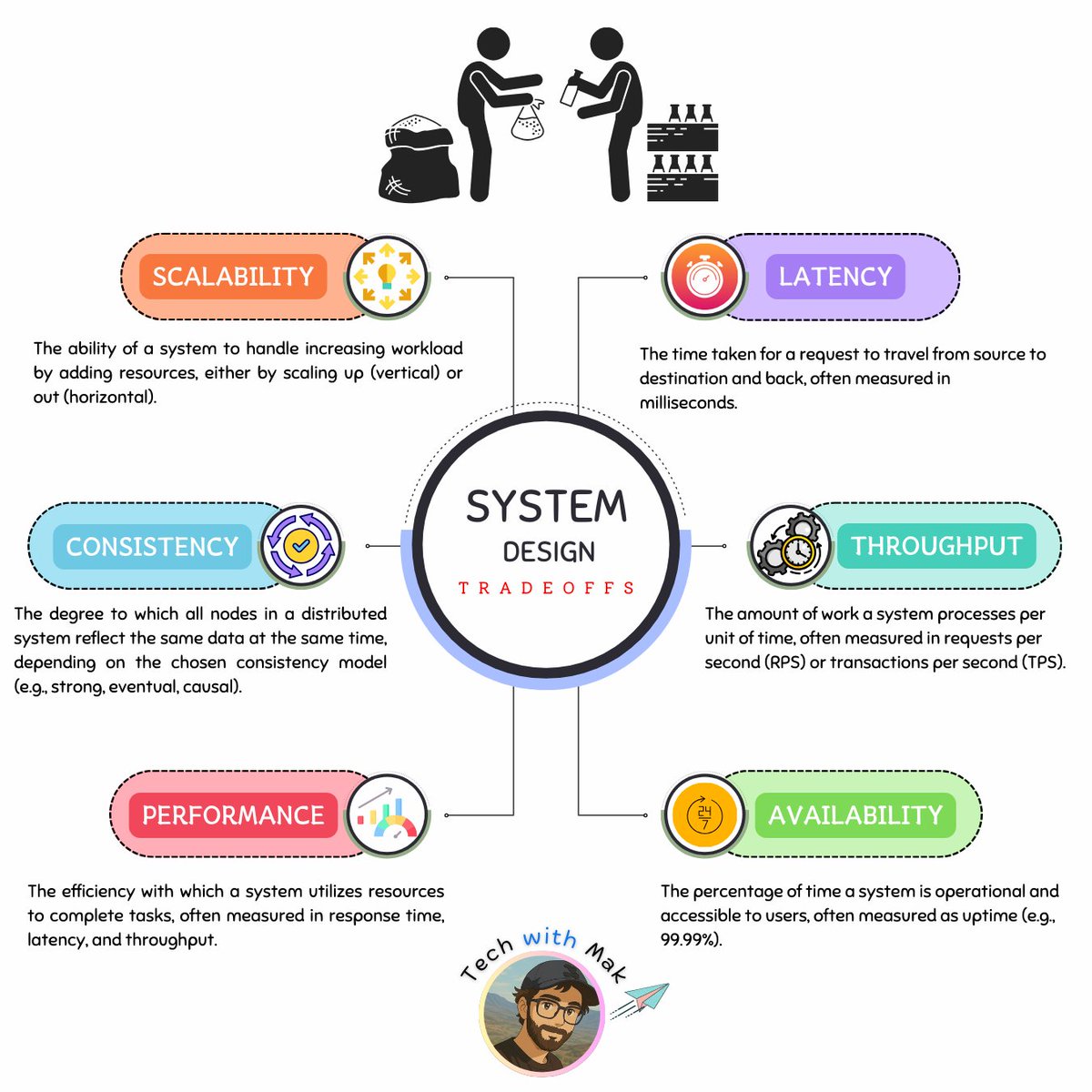
Some databases are powering AI agents,
And AI agents are powering other databases.
GIF
English
Deepak Bhardwaj
809 posts

@techdataguru
Building https://t.co/cLEFCRaAKI | 35K+ Readers on LinkedIn | Simplifying Data, AI & MLOps Through Clear, Actionable Insights