
Will
1.1K posts


codegen is cheap now. performance isn’t: most generated kernels are kinda mid.
iteration and feedback are missing for both the agent and RL env layers.
so we're open-sourcing Apex: an end-to-end agent using Claude Code + Codex to effectively optimize AMD kernels, instead of one-shotting them
github.com/AMD-AGI/Apex
English

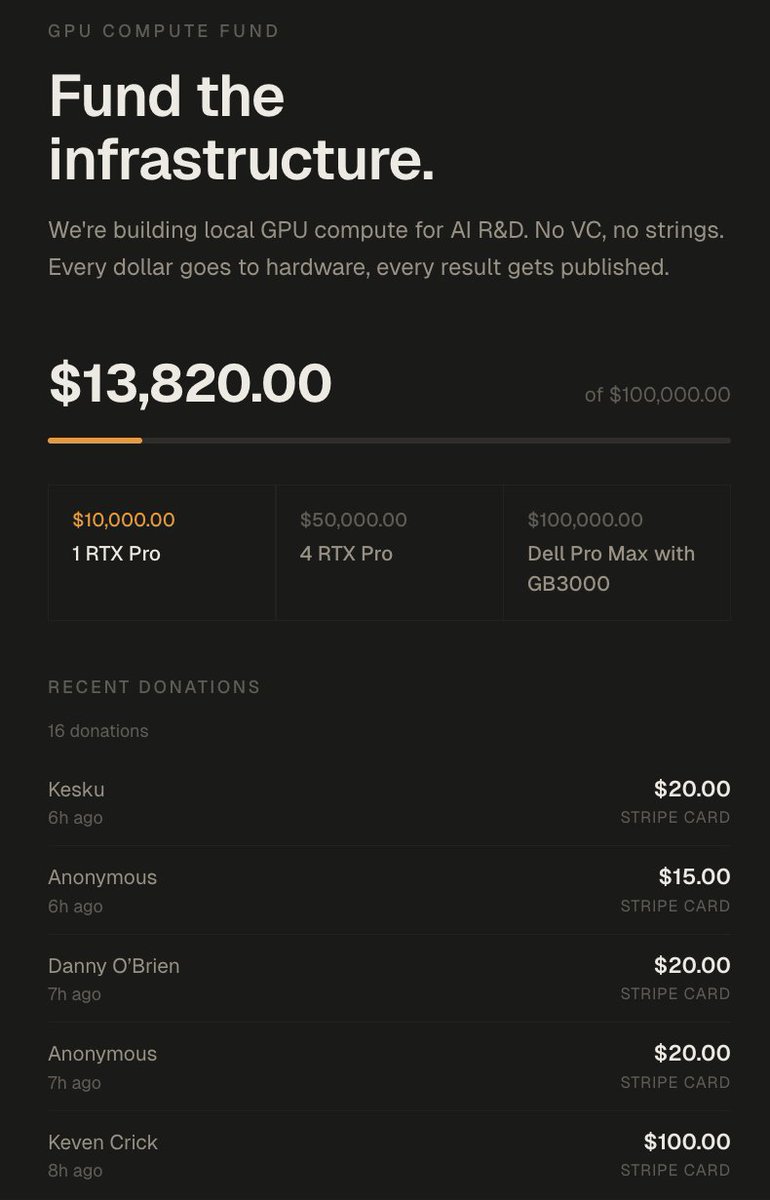
In 72 hours I got over 100k of value
1. Lambda gave me 5000$ credits in compute
2. Nvidia offered me 8x H100s on the cloud (20$/h) idk for how long but assuming 2 weeks that'd be 5000$~
3. TNG technology offered me 2 weeks of B200s which is something like 12000$ in compute
4. A kind person offered me 100k in GCP credits (enough to train a 27B if you do it right)
5. Framework offered to mail me a desktop computer
6. We got 14,000$ in donations which will go to buying 2x RTX Pro 6000s (bringing me up to 384GB VRAM)
7. I got over 6M impressions which based on my RPM would be 1500$ over my 500$~ usual per pay period
8. I have gained 17,000~ followers, over doubling my follower count
9. 17 subscribers on X + 700 on youtube.
The total value of all this approaches at minimum 50,000$~ and closer to 150,000$ if I leverage it all.
---------------------
What I'll be doing with all this:
Eric is an incredibly driven researcher I have been bouncing ideas off of over the last month.
Him and I have been tackling the idea of getting massive models to fit on relatively cheap memory.
The idea is taking advantage of different forms of memory, in combination with expert saliency scoring, to offload specific expert groupings to different memory tiers.
For the MoEs I've tested over my entire AI session history about 37.5% of the model is responsible for 95% of token routing.
So we can offload 62.5% of an LLM onto SSD/NVMe/CPU/Cheap VRAM this should theoretically result in minimal latency added if we can select the right experts.
We can combine this with paged swapping to further accelerate the prompt processing, if done right we are looking at very very decent performance for massive unquantisation & unpruned LLMs.
You can get DeepSeek-v3.2-speciale at full intelligence with decent tokens/s as long as you have enough vram to host the core 20-40% of the model and enough ram or SSD to host the rest.
Add quantisation to the mix and you can basically have decent speeds and intelligence with just 5-10% of the model's size in vram (+ you need some for context)
The funds will be used to push this to it's limits.
-----------------
There's also tons of research that you can quantise a model drastically, then distill from the original BF16 or make a LoRA to align it back to the original mostly.
This will be added to the pipeline too.
------------------
All this will be built out here: github.com/0xSero/moe-com… you will be able to take any MoE and shove it in here, and with only 24GB and enough RAM/NVMe to compress it down. it'll be slow as hell but it will work with little tinkering.
------------------
Lastly I will be looking into either a full training run from scratch -> or just post-training on an open AMERICAN base model
- a research model
- an openclaw/nanoclaw/hermes model
- a browser-use model
To prove that this can be done.
--------------------
I will be bad at all of it, and doubt I will get beyond the best small models from 6 months ago, but I want to prove it's no boogeyman impossible task to everyone who says otherwise.
--------------------
By the end of the year:
1. I will have 1 model I trained in some capacity be on the top 5 at either pinchbench, browseruse, or research.
2. My github will have a master repo which combines all my work into reusable generalised scripts to help you do that same.
3. The largest public comparative dataset for all MoE quantisations, prunes, benchmarks, costs, hardware requirements.
--------------------------
A lot of this will be lead by Eric, who I will tag in the next post.
I want to say thank you to everyone who has supported me, I have gotten a lot of comments stating:
1. I'm crazy, stupid, or both
2. I'm wasting my time, no one cares about this
3. This is not a real issue
I believe the amount of interest and support I've received says it all.
donate.sybilsolutions.ai
English

@turbo_xo_ post training is sufficient.
pre-training / mid-training is necessary in the long run for very powerful systems and naturally make better decisions
English


MiMo-V2-Pro & Omni & TTS is out. Our first full-stack model family built truly for the Agent era.
I call this a quiet ambush — not because we planned it, but because the shift from Chat to Agent paradigm happened so fast, even we barely believed it. Somewhere in between was a process that was thrilling, painful, and fascinating all at once.
The 1T base model started training months ago. The original goal was long-context reasoning efficiency. Hybrid Attention carries real innovation, without overreaching — and it turns out to be exactly the right foundation for the Agent era. 1M context window. MTP inference for ultra-low latency and cost. These architectural decisions weren't trendy. They were a structural advantage we built before we needed it.
What changed everything was experiencing a complex agentic scaffold — what I'd call orchestrated Context — for the first time. I was shocked on day one. I tried to convince the team to use it. That didn't work. So I gave a hard mandate: anyone on MiMo Team with fewer than 100 conversations tomorrow can quit. It worked. Once the team's imagination was ignited by what agentic systems could do, that imagination converted directly into research velocity.
People ask why we move so fast. I saw it firsthand building DeepSeek R1. My honest summary:
— Backbone and Infra research has long cycles. You need strategic conviction a year before it pays off.
— Posttrain agility is a different muscle: product intuition driving evaluation, iteration cycles compressed, paradigm shifts caught early.
— And the constant: curiosity, sharp technical instinct, decisive execution, full commitment — and something that's easy to underestimate: a genuine love for the world you're building for.
We will open-source — when the models are stable enough to deserve it.
From Beijing, very late, not quite awake.
English

Thanks for sharing our newest work @_akhaliq !
Classic algorithms like K-Means deserve to be revisited in the era of massive datasets and GPUs. Flash-KMeans rethinks the algorithm from a systems perspective to make exact K-Means fast and memory-efficient on modern hardware.
AK@_akhaliq
Flash-KMeans Fast and Memory-Efficient Exact K-Means paper: huggingface.co/papers/2603.09…
English
Will retweeté



Will retweeté

Boomer management doesn't understand that better models lead to more DAU.
It's over for Alibaba AI ambitions. They should focus on being like Oracle or Amazon and just sell compute.
"Alibaba Cloud has changed the Qwen team's performance evaluation method, using metrics like daily active users (DAU) typical of consumer-grade apps to assess the foundational model team."
外汇交易员@fxtrader
3月3日,阿里巴巴集团和蚂蚁集团的核心管理层罕见地全员聚齐,出现在杭州云谷学校。马云与阿里巴巴集团主席蔡崇信、CEO吴泳铭、风险委员会主席邵晓锋、电商事业群CEO蒋凡,蚂蚁集团董事长井贤栋和CEO韩歆毅悉数到场。
English

icymi: this guy has been blowing up on american social media / among the educated elites re: radical theories. he's 'famous' for predicting that trump would win and that US would go to war with iran.
here's an unfettered analysis on his claims what's unfolded, and how he aligns with global political agenda... in case you were curious:
perplexity.ai/computer/a/dos…
KJ Crypto@koreanjewcrypto
At the end of the interview this professor goes completely off script and names the illuminati and other secret societies in running the world and pushing for the war in Iran Absolutely wild I think it took the interviewers completely off guard
English

Will coding skills still be relevant in 10-20 years?
What useful things are you all building with your slave agent codex army?
I had a cracked friend from MIT who coded a bot that analyses data and makes value bets on 3rd division college basketball.
He lost money.
Haven't heard of anything else he built.
Btw, he quit our friendship after I showed him my X account, so I haven't shown my X to anyone since then.
English
Will retweeté

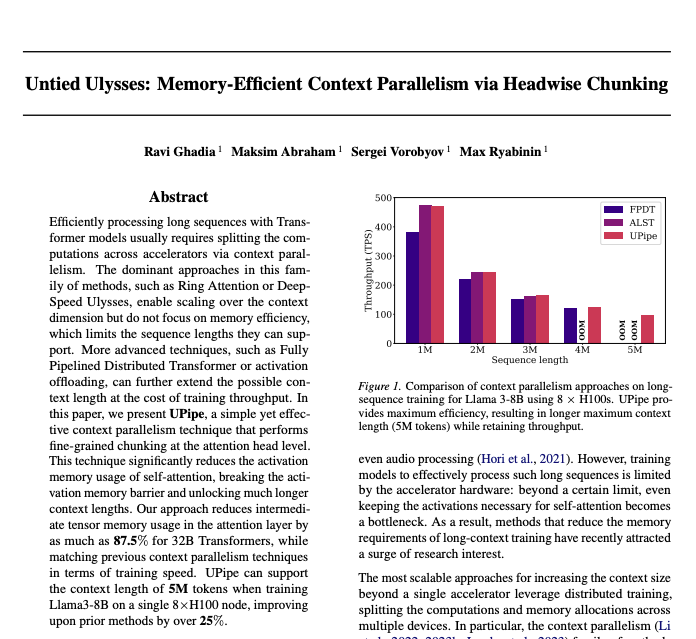
WTF you can now train a 5 million context window 8b model on a single node of 8xH100s ????
Most people don't realize that even on long context pretrained frontier models, most RL post-training is only done on a small fraction of that context.
Why? Long context RL is notoriously memory hungry, and requires a sharding strategy called Context Parallelism that takes up an inordinate amount of GPUs.
This paper for Together flew under the radar, combines the best of Context Parallelism + Sequence Parallel-style head chunking, to get memory efficient long context.
The gains are insane, cutting attention memory footprint up to 87%
Authors: @m_ryabinin , @sereghik , Maksim Abraham, @ghadiaravi13
English

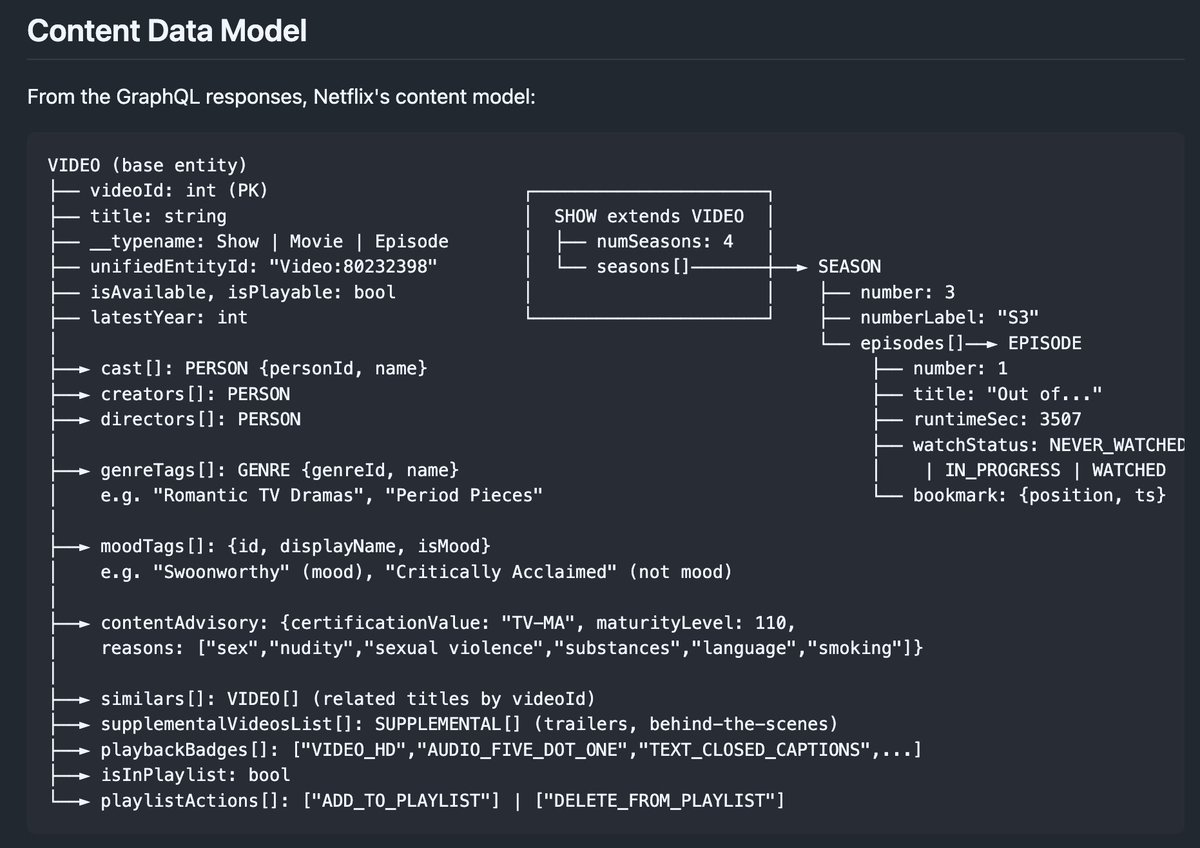
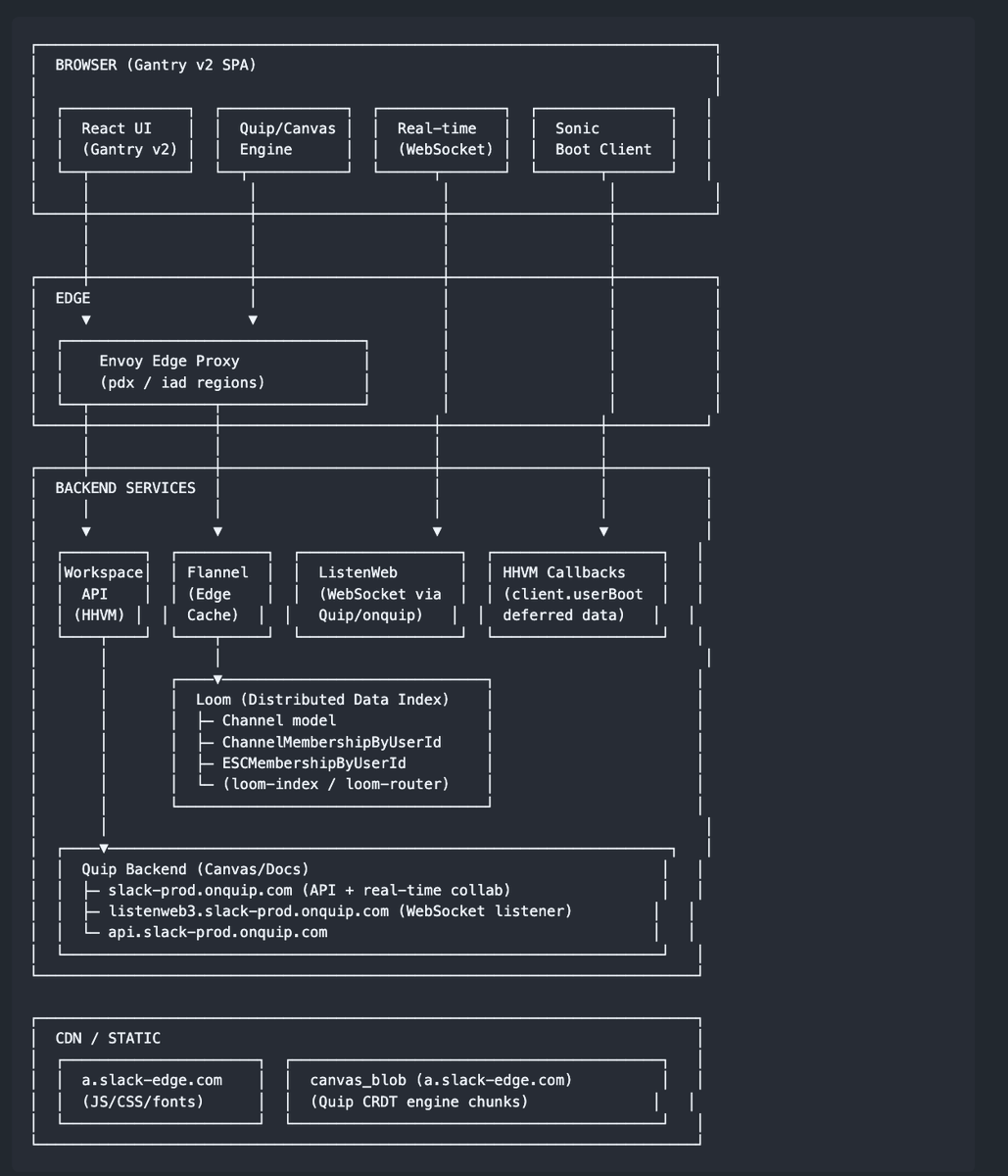
ok decompiling things with opus is actually very addicting
here's apparently how netflix and slack work
- gist.github.com/sshh12/dda3a89…
- gist.github.com/sshh12/4cca8d6…
idk maybe wont be that hard to vibe code these after all
> use chrome dev tools to explore and provided a grounded tear down analysis of how the site works
English

Today is my last day at Apple.
Building MLX with our amazing team and community has been an absolute pleasure.
It's still early days for AI on Apple silicon. Apple makes the best consumer hardware on the planet. There's so much potential for it to be the leading platform for AI. And I'm confident MLX will continue to have a big role in that.
To the future: MLX remains in the exceptionally capable hands of our team including @angeloskath, @zcbenz, @DiganiJagrit, @NasFilippova, @trebolloc (and others not on X). Follow them or @shshnkp for future updates.

English
literally the most useful update
Boris Cherny@bcherny
Claude Code Remote is rolling out now for Pro users
English

@garrytan We crave AI companions not because we want artificial relationships. Because reliable human attention became scarce.
English

This is not the happy demo path, Apple or Google would never make this one of their launch videos... it's not what you will hear about in a TED talk, but it's real
AI: Doesn't get tired, doesn't ghost
A lot to think about in this one
Avi@AviSchiffmann
User Interview #3
English

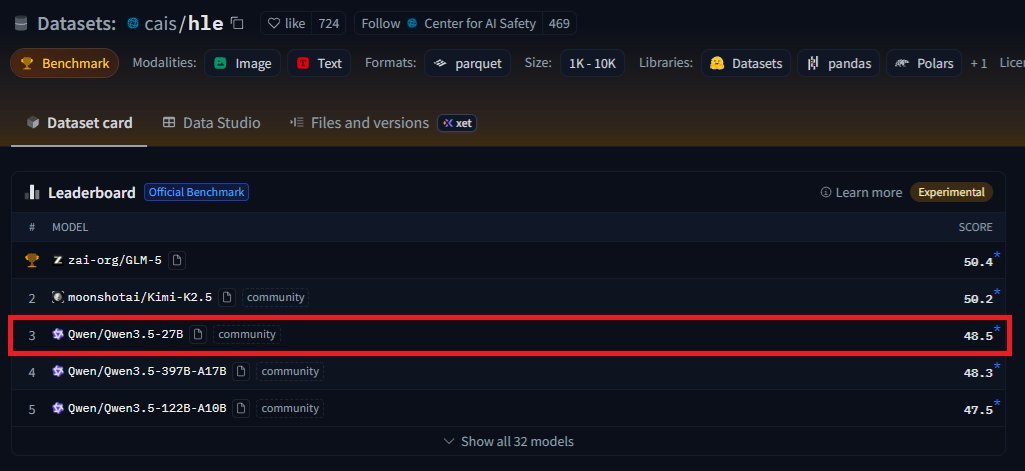
Not only does Qwen3.5-35B-A3B decode @ 30tps on DGX-Spark, but the smaller flavor 27B scores near SOTA level on Humanity's Last Exam! Imagine running on a small portable PC!

David Hendrickson@TeksEdge
The latest DGX-Spark leaderboard shows Qwen3.5-35B-A3B 🏆 decode at 30 tps (unquantized), which beats GPT-OSS-120B across all benchmarks and nearly all of Sonnet 4.5 & GPT5-Mini. Run this at home on your DGX-Spark or Spark Clone. 🦞 Clawdbot Friendly
English

Agents can one shot mobile apps, but testing is still the bottleneck.
So we built a CLI that gives Claude Code the one thing it was missing - eyes and hands
The best part? t's fully vision-based:
- No scripts, no selectors, no element IDs
- It interacts with the app exactly like a human would
Claude now writes code → tests it on the app → sees what broke → fixes it
Spawn a cloud agent, go to sleep, and wake up knowing it actually worked.
English
Been using it non stop since sat
Got 10 codex, 10 Claude code, and 5 Browser tabs open rn
These guys are cracked!
Lawrence Chen@lawrencecchen
Introducing cmux: the open-source terminal built for coding agents. - Vertical tabs - Blue rings around panes that need attention - Built-in browser - Based on Ghostty When Claude Code needs you, the pane glows blue and the sidebar tells you why. No Electron/Tauri. Just Swift/Appkit.
English