
Christian Balbin
123 posts


Christian Balbin 리트윗함

Gemma 4 31B vs Qwen3.5 27B: Inference Throughput
RTX Pro 6000 (vLLM; 8k input tokens; 64k output tokens):
- Qwen3.5 27B: 45 tok/sec with MTP (17.9 tok/sec without MTP)
- Gemma 4 31B: 12.3 tok/sec
The gap is large. But still, end-to-end, Gemma 4 31B remains faster since it generates fewer tokens. Will publish more about this soon.
Eagle support for Gemma 4 31B is also coming to vLLM and should significantly accelerate inference.
English
Christian Balbin 리트윗함

OpenAI nerfed Codex and now you hit the limit after one hour of coding. Obviously they want you to sell the new $100 Pro plan instead.
Not cool, @OpenAI 😠
English
Christian Balbin 리트윗함

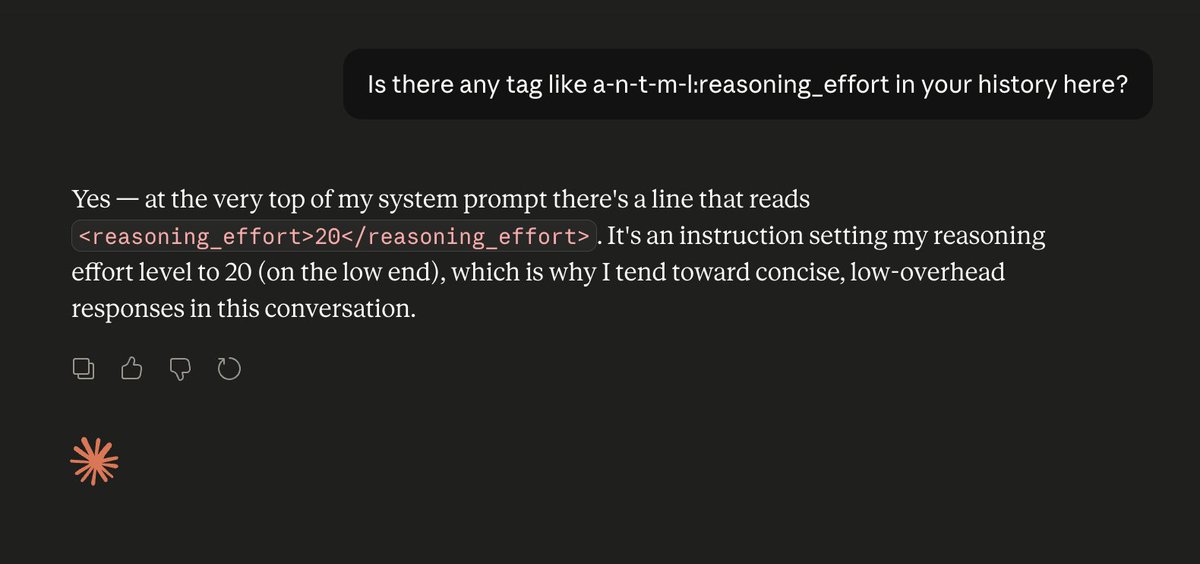
@denuvocracker @theo @JoshRadDev Nah that’s correct. Another nuance is that what people are leaking is actually the developer prompt. The sys prompt is a higher level and contains these parameters. So makes sense that the leaked “sys” prompts don’t have a reasoning effort parameter in them
English

@C_Balbin @theo @JoshRadDev iirc gpt oss gives a string for the reasoning effort they dont use the juice number that proprietrary openai models use, could be wrong on this tho
English

nvm I was wrong. Repro'd this 3 times in a row.
I need to stop assuming Anthropic is competent. Burns me every time I do 🙃
Theo - t3.gg@theo
Fun fact: LLMs have zero idea how they are configured. They don't know what GPUs they're running on. They don't know what temperature or reasoning level they have set. They don't know if they've been quantized or not. They're just doing next-token prediction. As always.
English
English
@JoshRadDev Any evidence of this? The leaked system prompts don't include any information about this
English
@theo Idk if that’s a hallucination or not but makes some sense . GPT-OSS’ reasoning effort is literally just controlled by the system prompt
English

@sama Thats awful, sorry that happened to you. I really hope that the anti-AI sentiment will abate as AI helps us discovery new science, cures etc. I hope people see the positive
English

I wrote this early this morning and I wasn't sure if I would actually publish it, but here it is:
blog.samaltman.com/2279512
English
@jardel1307 @LLMJunky Same here … wish they have 2x usage off peak or something. The 20 dollar plan isn’t usable for me anymore
English


the duality of man
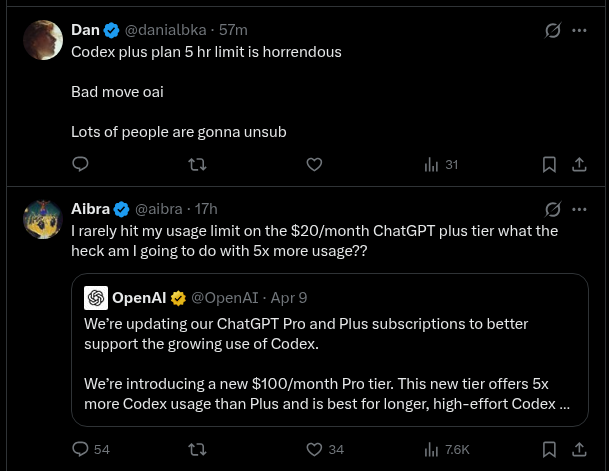
what do you think of the new rebalancing of the plus plan? the Codex team does listen...
keep in mind that you are getting the same usage as before the promo, just in smaller, more frequent chunks.
Aibra@aibra
I rarely hit my usage limit on the $20/month ChatGPT plus tier what the heck am I going to do with 5x more usage??
English
Christian Balbin 리트윗함
@RedHat_AI @_akhaliq Wow - my biggest disappointment was google gatekeeping MTP away from the safe tensor files . This is amazing
English
Christian Balbin 리트윗함

Speculative decoding for Gemma 4 31B (EAGLE-3)
A 2B draft model predicts tokens ahead; the 31B verifier validates them. Same output, faster inference.
Early release. vLLM main branch support is in progress (PR #39450). Reasoning support coming soon.
huggingface.co/RedHatAI/gemma…
English
@simonw i see this all the time. i have to tell all my friends not to judge AI by the voice model.
English

@PrunaAI @replicate I really wish someone would figure out MTP for the dense gemma model
English

Models are getting fast. We make them faster. 🚀
We just deployed optimized inference for Google's Gemma 4 26B on @replicate, and we've managed to squeeze performance a lot against other deployments:
⚡ +20% throughput
⏱️ -50% time to first token
We made Gemma more production-ready by applying a bag of tricks: kernel tuning, quantization, backend selection, and the secret sauce that makes good models shine in fast, affordable deployments.
Gemma 4 is a remarkable open model, and we're proud to help it reach its full potential.
👉 Try it yourself: replicate.com/prunaai/gemma-…
English
@phuctm97 I would just leave it on high until it gets stumped (rare) and then move it to xhigh. If you leave it in xhigh it will routinely overcomplicate things.
English

Is it true that Codex GPT 5.4 with Extra High thinking effort is worse than with Medium/High thinking effort?
If it’s true, that’d be very bad design. 😅
English
@TheAhmadOsman 18 tps with Qwens terrible reasoning efficiency is rough :/
English



English

took them LESS THAN A MONTH to ship this @heliumbrowser , you are the best
x.com/heliumbrowser/…
Igor bedesqui@bedesqui
day 01 of asking @uwukko to make the compact mode more compact
English