
Chris
65 posts


Hermes Agent v0.11.0 - “The Interface Release”
Full changelog below ↓
English
New subscription tiers are live on Nous Portal
→ Plus ($20)
→ Super ($100)
→ Ultra ($200)
Bonus credits on signups, upgrades, and renewals: +$2 on Plus / +$10 on Super / +$20 on Ultra
All tiers include access to:
→ 300+ models
→ Bundled tool usage
portal.nousresearch.com/manage-subscri…
English
@Dimillian Do you think the $20/mo plan could do something similar with a 2d platformer I’ve been vibe coding with my son at night? We’ve got the core game already created. Just need to add a few more worlds. Think cowboy western style super Mario. Building in godot.
English

So this game is real now, fully built with GPT-5.5. I told Codex to use the imagegen skill to generate a reference UI and sprites, and used the Build macOS Apps plugin to build the app for a native retro fantasy labyrinth game!
Adjusted the UI in a few prompts and here we are!
Thomas Ricouard@Dimillian
BRB building this
English
Chris 리트윗함

Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
English

Giving away 5 more Codex Pro plans for folks to try out multi-agent workflows with Codex and Codex Spark
Each person will get 3 months of free Codex Pro (highest tier).
Winners will be selected from comments in 48 hours, comment below why you want it.
Sarah Chieng@MilksandMatcha
English
@dhruvtwt_ @nvidia What are each of these models best at? I want to scale this with Hermes and spin up agents for each based on what they are best at.
English

Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: build.nvidia.com/models
– base_url = "integrate.api.nvidia.com/v1"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.

English
@ollama @Thorarnejo When my Claude subscription expires I’m going ollama
English

100,000 Stars, #1 Trending Repo this Month
This is just the beginning. Stay tuned.

Teknium 🪽@Teknium
Hermes Agent just hit 100,000 stars on GitHub!!! Thank you everyone!!
English

What am I supposed to do when I can’t trade on Saturday??
English

People who grew up without internet, how did you deal with boredom at home?
English


2-bit Qwen3.6-35B-A3B did a complete repo bug hunt with evidence, repro, fixes, tests and a PR writeup. 🔥
Run it locally in Unsloth Studio with just 13GB RAM.
2-bit Qwen3.6 GGUF made 30+ tool calls, searched 20 sites and executed Python code.
GitHub: github.com/unslothai/unsl…
English
@KyleHessling1 Also it was able to pump out a working python tic tac toe game in about 10mins
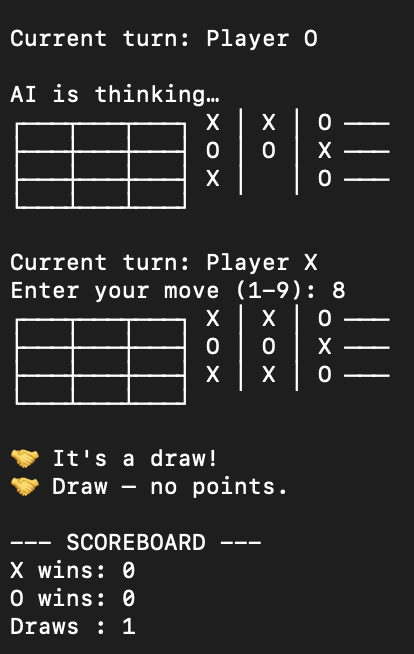
English
@KyleHessling1 Results (ollama)
"Is the earth flat?"
total duration: 2m32.872036334s
load duration: 111.422542ms
prompt eval count: 15 token(s)
prompt eval duration: 5.013375917s
prompt eval rate: 2.99 tokens/s
eval count: 874 token(s)
eval duration: 2m27.100843493s
eval rate: 5.94 tokens/s
English

GUYS IM SO HYPED!
This was all theoretical, made it just for fun; I did not know if a merge of two different fine tunes would be usable let alone an improvement! But the final seam-healed 18B merge is genuinely awesome! And a real improvement over either 9B alone (at least I think make your own conclusions and let me know)
TLDR: I’ve merged 2 of Jackrongs excellent fine tunes into one really awesome 18B model, sitting nicely between the 9B and 27B using only 10GB of VRAM!
It one shotted a bunch of web dashboards AND A SNAKE GAME THAT WORKS and looks nice too! All in the video below you can also check them in the repo!
Uploading the healed model now, unfortunately T-Mobile internet is throttling me to 1MB/second upload so it will be 30 minutes or so before it’s done but it will be live at the repo in the comments! And I will post again when it’s live!
In the meantime, you can open the html examples in the repo to check them out! I also have included a full documentation of the merge and healing process!
WERE GONNA MAKE SO MUCH COOL STUFF WITH THIS METHOD!
English
Honored to announce we are partnering with Jim Liu to port over his wildly popular skills for infographics and design to work best in Hermes Agent using our native tooling!
The first skill ported today, the Infographic Skill, is available after updating hermes.
Just start a new chat and type `/baoyu-infographic ` to get started! Recommended image generation model is Nano Banana.
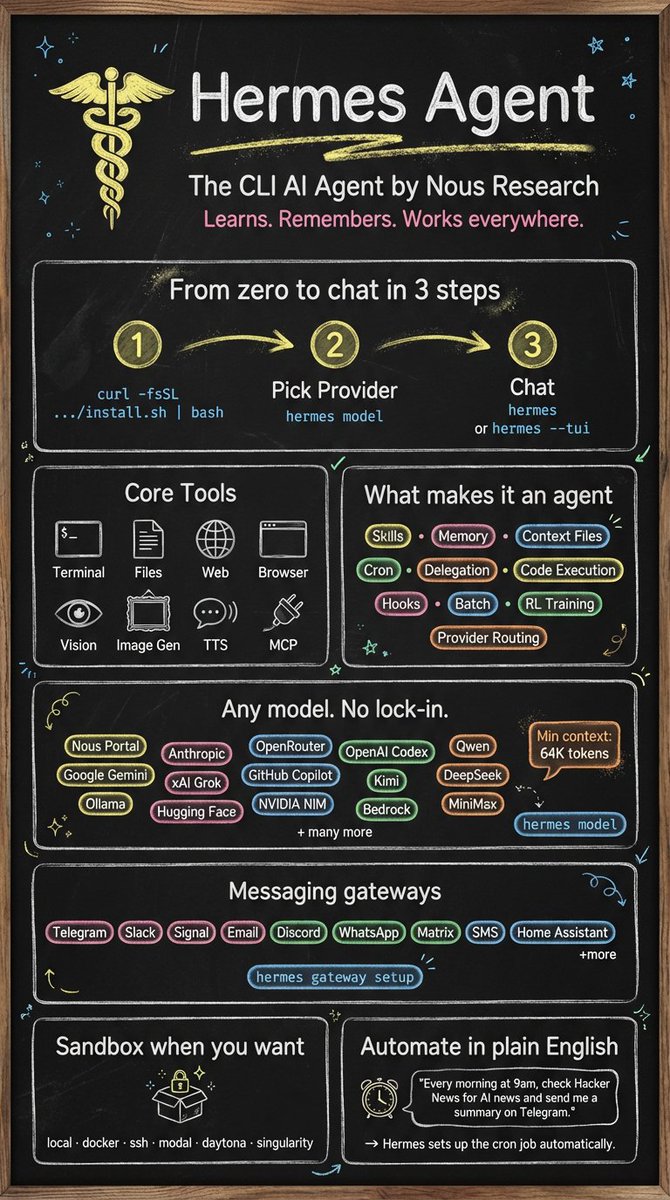
宝玉@dotey
Truly honored! My project has gained significant traction with 14k+ stars on GitHub. Specifically, my skills for technical infographic generation and social media (Little Red Book style) visual content are extremely popular in the Chinese developer community. They bridge the gap between LLM reasoning and aesthetic visual output. Would love to see them integrated as built-in options for Hermes! Repo: github.com/jimliu/baoyu-s…
English
@ChrisLikesAI @UnslothAI Yes, unfortunately running directly from the SSD will reduce its lifespan to some extent.
But I ran some other tests using Qwen3.6-35B-A3B-UD-IQ2_XXS.gguf.
That one fits entirely in memory with 32k context and runs at around 25 tk/s on average.
English
@rukasufall @UnslothAI Just saw your reply. Gave you a follow. Thanks for responding. Does running from the SSD hurt the SSD or shorten its lifespan?
English
@ChrisLikesAI @UnslothAI Yes, you can run it.
Download the UD-IQ3_XXS. Run it on llama.cpp using --mmap.
It should run at around 13 tk/s directly from the SSD.
English
ollama launch hermes
Ollama 0.21 includes supports Hermes Agent, the self-improving AI agent built by @NousResearch.

English