고정된 트윗

Here is a Citrini critique from a Macro-AI lens.
Citrini's "2028 Intelligence Crisis" direction of labor market impact is sensible. The velocity is wrong. His scenario timeline is off by ~ 5 years + because his AI capability assumptions are anecdotal, not grounded in the math of how models actually improve.
His core assumptions:
1) The AI feedback loop is sustained by "AI Investment Increases & AI Capabilities Improve" — implying that as long as you throw money at compute, you get better models that unlock capabilities replacing humans at a given task
2) He extrapolates from what he's observed anecdotally about AI agents to "smooth sailing" toward autonomous multi-week agents by 2027. This is a guess, not an informed view
Let's rigorize his feedback loop with some Macro-AI:
scaling laws → capabilities → task automation → displacement
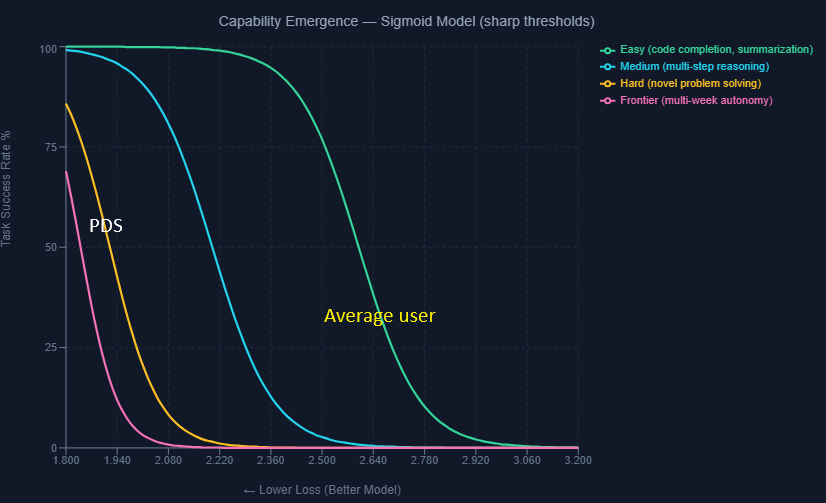
The relationship between scaling laws and capabilities is determined by a "Capability Transfer" function. This relationship is non-linear and task-dependent. Capabilities don't emerge linearly from loss improvements — they phase-transition at specific thresholds (I model this with a sigmoid in pic below). Du et al. (2024) validates pre-training loss as the sufficient proxy for capability emergence below task-specific thresholds.
The hard tasks Citrini envisions — autonomous multi-week work by 2028 — likely have thresholds near the irreducible loss floor (E ≈ 1.82 nats). But here's the deeper issue: next-token prediction is a proxy objective. A model can approach E without acquiring the causal reasoning, goal persistence, and calibrated uncertainty that autonomous work demands. The frontier labs' pivot to post-training (RLHF, inference-time compute, tool use) is an implicit admission of this gap. All this to say, some hard tasks may not be solvable by scaling compute alone - which is what Citrini assumes.
If we know the capability transfer thresholds and map them to loss levels (and thus compute), we can estimate when complex tasks become feasible. (yup -> we can actually model this)
Using 0.40 OOM/year in compute growth and 0.30 OOM/year in algorithmic efficiency gains, I model that professional replacement (defined workflows: customer service, routine legal, basic analysis) starts mid-2026 — but cognitive displacement (multi-week autonomy, novel problem solving) only arrives ~2031. Citrini's crisis requires cognitive displacement. So his timeline starts at 2031 at earliest.
**AND** we haven't even addressed two more constraints that push it further: agent reliability decays exponentially with task complexity and the training data wall.
If I can vibe code myself into a web dev, I'll upload the interactive model at pdsmacro.com for you to stress-test the assumptions yourself.
English