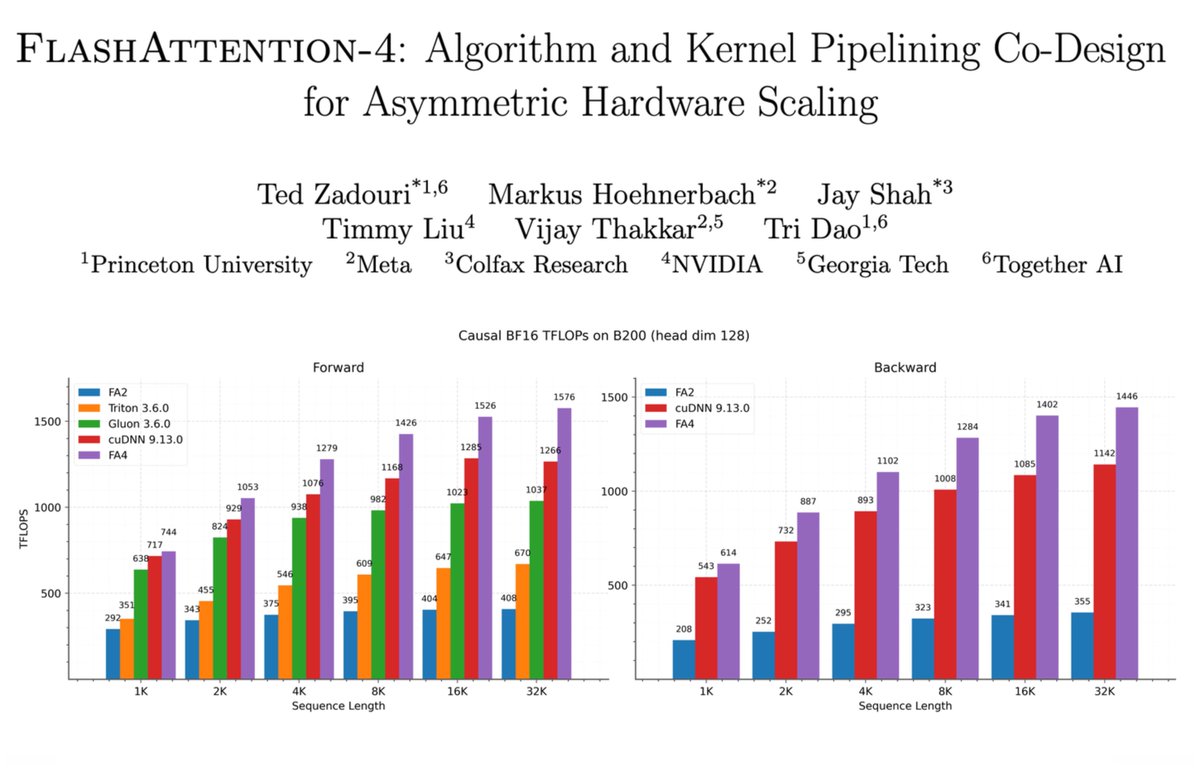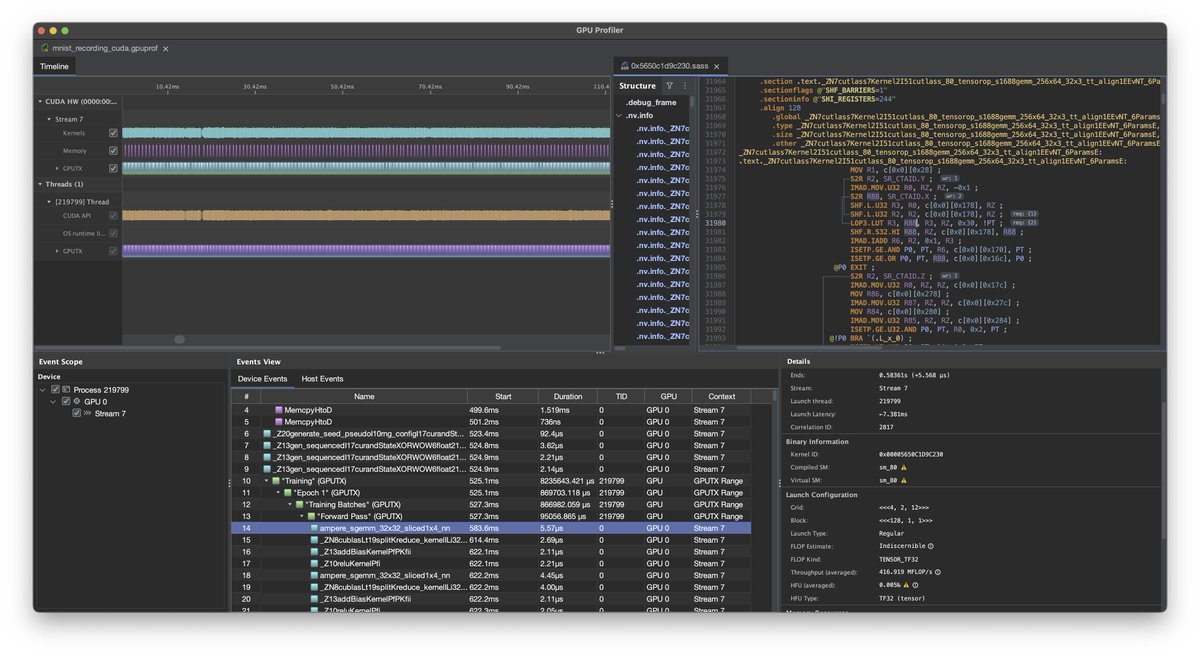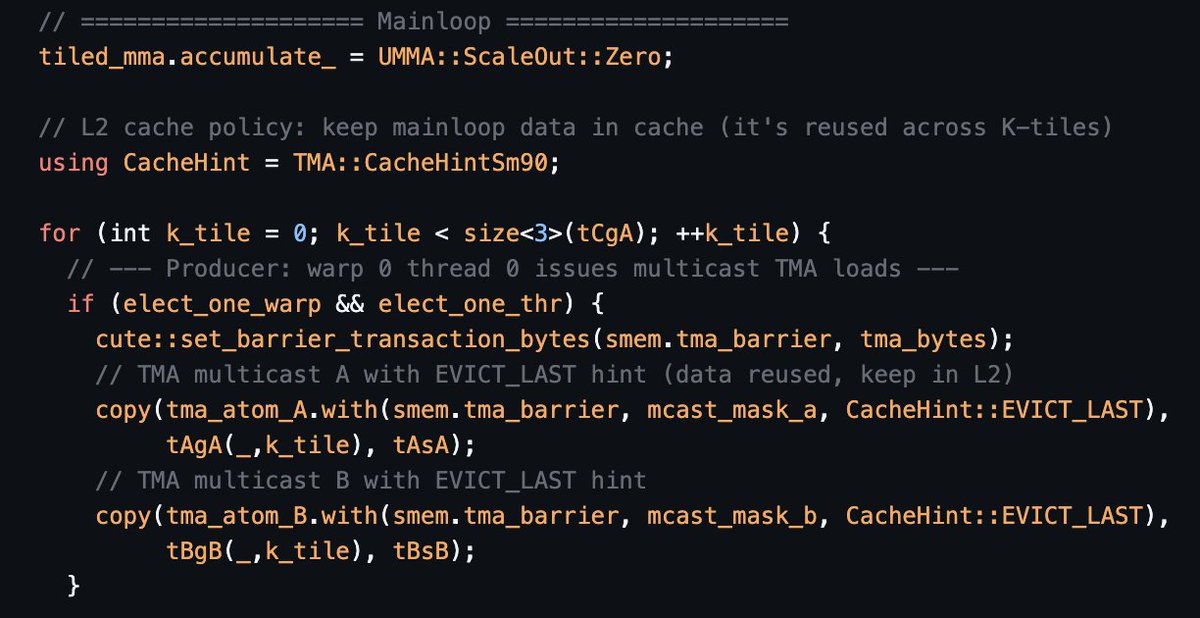
고정된 트윗
As of last week, I am no longer at NVIDIA 🧵
Leaving the CUTLASS team was extremely hard. I will dearly miss my incredible colleagues and the extremely compelling mission statement of creating the world's best accelerator programming model w/ hardware software codesign 💚

English