
Asmir
441 posts




@HarshithLucky3 i dug into what they said and it's not looking good:
x.com/asmirkn/status…
Asmir@asmirkn
i spent $3,700 on claude code in 44 days and didn't know until tonight everyone's complaining about claude limits draining and anthropic saying they fixed it i wanted to actually check so i built something. ran it on my data run 'npx cchubber' if you wanna see yours github.com/azkhh/cchubber
English

Anthropic what is going on
Anthropic's official response to the Claude limit drain is basically "you are holding it wrong"
We pay for Pro for Opus models, but their official advice is:
> Do not use Opus on Pro
> Do not use the 1M context window
> Do not resume a heavy session after an hour
> You were not overcharged, you just hit peak limits faster
> Zero quota resets for affected users
Telling power users to stop using the exact specs they pay for....
Lydia Hallie ✨@lydiahallie
Thank you to everyone who spent time sending us feedback and reports. We've investigated and we're sorry this has been a bad experience. Here's what we found:
English
if there is no cache issues in claude code
then what is this about?
why does it say it dropped after the 17th of March?
Lydia Hallie ✨@lydiahallie
Digging into reports, most of the fastest burn came down to a few token-heavy patterns. Some tips: • Sonnet 4.6 is the better default on Pro. Opus burns roughly twice as fast. Switch at session start. • Lower the effort level or turn off extended thinking when you don't need deep reasoning. Switch at session start. • Start fresh instead of resuming large sessions that have been idle ~1h • Cap your context window, long sessions cost more CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 We're rolling out more efficiency improvements, make sure you're on the latest version. If a small session is still eating a huge chunk of your limit in a way that seems unreasonable, run /feedback and we'll investigate
English
@mchulet here's what's going on:
x.com/asmirkn/status…
Asmir@asmirkn
i spent $3,700 on claude code in 44 days and didn't know until tonight everyone's complaining about claude limits draining and anthropic saying they fixed it i wanted to actually check so i built something. ran it on my data run 'npx cchubber' if you wanna see yours github.com/azkhh/cchubber
English

I'm on a MAX plan, and now I'm hitting my limit every couple of hours.
What's going on?
Honestly, this makes Claude unusable. I've had to sign up for ChatGPT again just because of this.
English
@codyplof its a bug look:
x.com/asmirkn/status…
Asmir@asmirkn
i spent $3,700 on claude code in 44 days and didn't know until tonight everyone's complaining about claude limits draining and anthropic saying they fixed it i wanted to actually check so i built something. ran it on my data run 'npx cchubber' if you wanna see yours github.com/azkhh/cchubber
English

So is this truly a Claude bug or is this just the new normal?
Praying it’s a bug but am worried
English
i spent $3,700 on claude code in 44 days and didn't know until tonight
everyone's complaining about claude limits draining and anthropic saying they fixed it
i wanted to actually check so i built something. ran it on my data
run 'npx cchubber' if you wanna see yours
github.com/azkhh/cchubber
English


@andrezorteg @anothercohen i ended up putting something together, run npx cchubber and you'll get stats with a card like this
English

Are those tokens consumed per day? There's an important usage difference per day. Also it doesn't show associated cost.
It's interesting, could you post the full table?
Imagine creating an open-source project where thousands of users share many details of their usage data and ask Claude to infer the criteria Anthropic uses to count tokens.
English

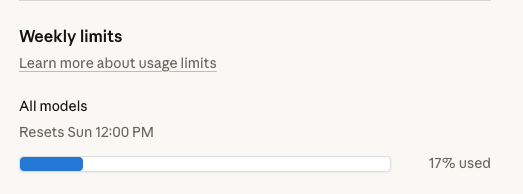
Have not once hit a weekly limit with Claude and the Max plan and somehow in the last two days I'm hitting both daily and weekly limits.
What is going on?
English

i haven't had the need for another vault tbh, i am a firm believer in the 1 vault system, let me explain
this is what i do right now, i have a system (moveros.dev), i go about my day working with claude code it uses those sessions and my conversations with it as raw input, i then have automated workflows that take those sessions and then filter out the noise to capture the decisions i made, how i was feeling , roadblockers, how i overcame them etc and they store those in another folder in my vault
if it is anything to do outside of working with claude code i simply just write that in my daily note and that also gets processed by ai to connect to everything else that is in my vault. no need to vault switch i allow Ai to write to my vault because i have constrained the outputs it can store in there, low signal stuff never makes it through.
the benefit of this is that everything is in one main folder (the vault), i don't need to think about two vaults or what goes where because i have removed the bottleneck of low signal stuff in the first place.
now the Ai not only helps me learn external stuff but it is actively aiding me with understanding myself, keeping me locked in on the most highest leverage tasks and not repeating the patterns that hinder me etc.
the knowledge i curate is also internal knowledge that i have learnt through working on projects and overcoming roadblocks and those get logged automatically as well etc.
all in 1 vault interconnected where Ai can exist at the same time as well due to it's superior pattern recognition
English

I like @karpathy's Obsidian setup as a way to mitigate contamination risks. Keep your personal vault clean and create a messy vault for your agents.
I prefer my personal Obsidian vault to be high signal:noise, and for all the content to have known origins.
Keeping a separation between your personally-created artifacts and agent-created artifacts prevents contaminating your primary vault with ideas you can't source.
If you let the two mix too much it will likely make Obsidian harder to use as a representation of *your* thoughts. Search, bases, quick switcher, backlinks, graph, etc, will no longer be scoped to your knowledge.
Only once your agent-facing workflow produces useful artifacts would I bring those into the primary vault.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
bro am i retarded, why aren't we doing this for our personal lives?
right now i have a very aligned system (moveros.dev) that takes data from my daily life, all actions i do, every project i work on, what i eat, sleep, how i perform, etc and it creates files within obsidian that are basically my entire conscious life
now using those conscious details it extracts what's hidden due to its pattern recognition, and give some underlying patterns about myself, i have had more self reflection through this then doing any other thing in life
an even better part about this is that because it knows my downsides, it can help me overcome them when i use it on a day to day basis and generally just allow me to perform better in life, it's quite cool
English

i have been doing this on steriods for the last 6 months, i feel like people are going to feel very stupid for not curating their own knowledge bases once we reach a point where LLMs have higher context and they run locally.
right now i have a very aligned system (moveros.dev) that takes data from my daily life, all actions i do, every project i work on, what i eat, sleep, how i perform, all my failures etc and it creates files within obsidian that are basically my entire conscious life
now using those conscious details it extracts what's hidden due to its pattern recognition, and give some underlying patterns about myself, corrects my behaviour etc. I have had more self reflection through this then doing any other thing in life
an even better part about this is that because it knows my downsides, it can help me overcome them when i use it on a day to day basis and generally just allow me to perform better in life, it's quite cool
English

karpathy is showing one of the simplest AI architectures that actually works..
dump research into a folder, let the model organise it into a wiki, ask questions, then file the answers back in.
the real insight is the loop...every query makes the wiki better. it compounds.. now thats a second brain building itself.
i think this is so good for agents if applied right
instead of pulling from shared memory every session, they build a living knowledge base that stays.
your coordinator is not just coordinating tasks anymore.. it is maintaining institutional knowledge so every execution adds something back to the base.
the bigger implication is crazy tho.
agents that own their own knowledge layer do not need infinite context windows, they need good file organisation and the ability to read their own indexes.
way cheaper, way more scalable, and way more inspectable than stuffing everything into one giant prompt.

Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
man its insane to me that i have been doing this for the last 6 months and you just tweet about it, i feel like people are going to feel very stupid for not curating their own knowledge bases once we reach a point where LLMs have higher context and they run locally.
right now i have a very aligned system (moveros.dev) that takes data from my daily life, all actions i do, every project i work on, what i eat, sleep, how i perform, etc and it creates files within obsidian that are basically my entire conscious life
now using those conscious details it extracts what's hidden due to its pattern recognition, and give some underlying patterns about myself, i have had more self reflection through this then doing any other thing in life
an even better part about this is that because it knows my downsides, it can help me overcome them when i use it on a day to day basis and generally just allow me to perform better in life, it's quite cool.
English

LLM Knowledge Bases
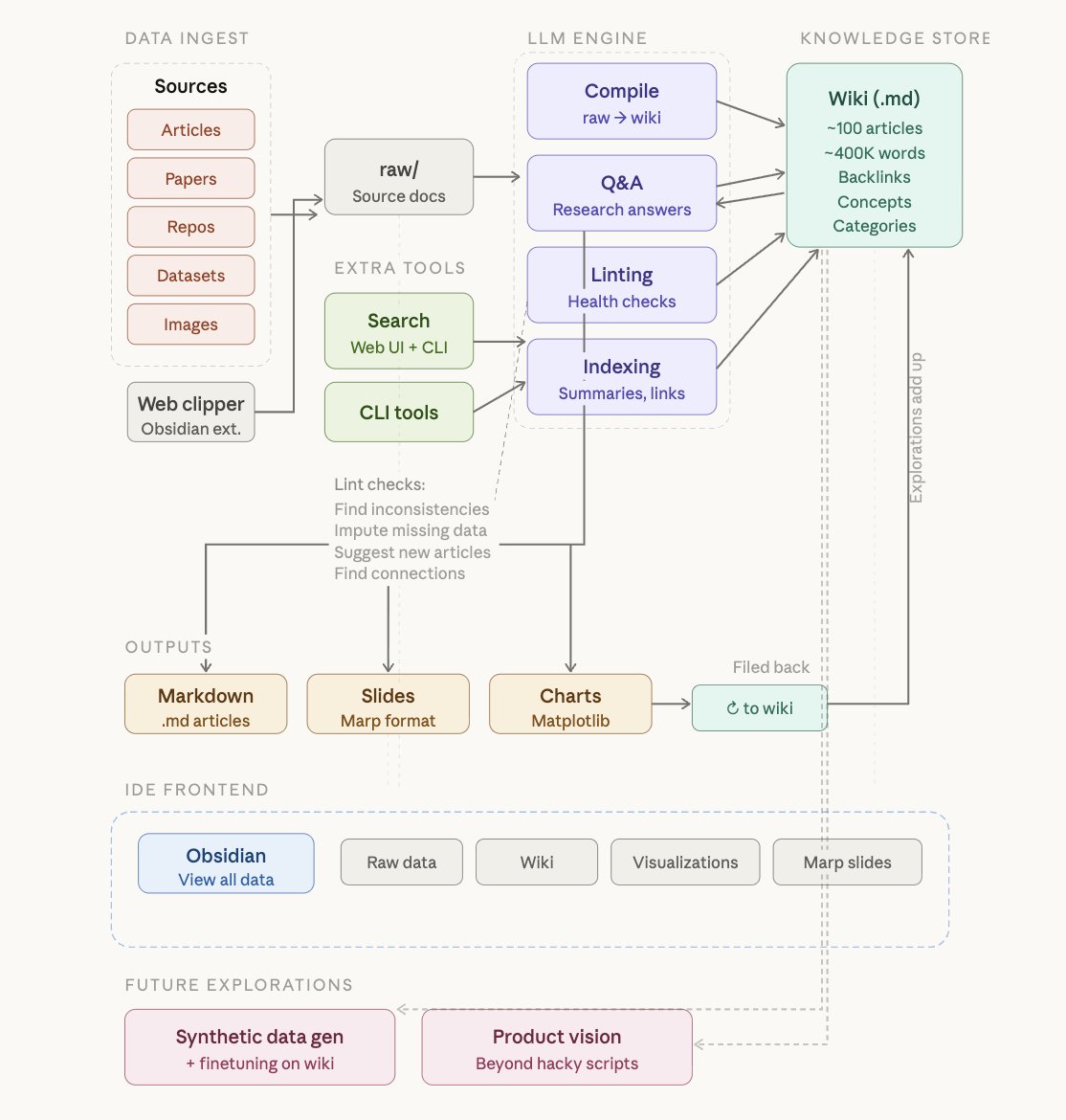
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@ashen_one @karpathy yo bro imma put you on, use moveros.dev, been building it for the last 6 months and have smoothed out all the downsides. try it!
English

genuinely if you are not curating your local knowledge bases, you are going to feel so stupid when the models get local and have higher context windows, that's why i have a system (moveros.dev) that extracts knowledge from my daily life and the projects i do and stores them, it then uses that knowledge to establish patterns and looks for blindspots helping me make better decisions everyday. literally like jarvis
English

Building a personal knowledge base for my agents is increasingly where I spend my time these days.
Like @karpathy, I also use Obsidian for my MD vaults.
What's different in my approach is that I curate research papers on a daily basis and have actually tuned a Skill for months to find high-signal, relevant papers.
I was reviewing and curating papers manually for some time, but now it's all automated as it has gotten so good at capturing what I consider the best of the best. There are so many papers these days, so this is a big deal.
You all get to benefit from that with the papers I feature in my timeline and on @dair_ai.
The papers are indexed using @tobi qmd cli tool (all of it in markdown files along with useful metadata). So good for semantic search and surfacing insights, unlike anything out there.
I am a visual person, so I then started to experiment with how to leverage this personal knowledge base of research papers inside my new interactive artifact generator (mcp tools inside my agent orchestrator system). The result is what you see in the clip.
100s of papers with all sorts of insights visualized. I keep track of research papers daily, so believe me when I tell you that this system is absolutely insane at surfacing insights. This is the result of months of tinkering on how to index research and leverage agent automations for wikification and robust documentation.
But this is just the beginning. The visual artifact (which is interactive too) can be changed dynamically as I please. I can prompt my agent to throw any data at it. I can add different views to the data. Different interactions. I feel like this is the most personalized research system I have ever built and used, and it's not even close.
The knowledge that the agents are able to surface from this basic setup is already extremely useful as I experiment with new agentic engineering concepts. I feel like this knowledge layer and the higher-level ones I am working on will allow me to maximize other automation tools like autoresearch. The research is only as good as the research questions. And the research questions are only as good as the insights the agents have access to.
Where I am spending time now is on how to make this more actionable. I am obsessed about the search problem here. The automations, autoresearch, ralph research loop (I built one months ago) are easier to build but are only as good as what you feed them.
Work in progress. More updates soon. Back to building.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@itsolelehmann honestly, the most reliable way i have found is using moveros.dev
English

@TTrimoreau you can just do things/ everything around you was made by people no smarter than you
English
