@Tech2Wild Here it is... ready to run docker compose file:
#aAwaBfG8tE2I8LRhAT-UKQ/dHKNUNrpSIUqbj2n8qDGNA" target="_blank" rel="nofollow noopener">send.bitwarden.com/#aAwaBfG8tE2I8…
Dear GitHub Copilot team,
I am happy to announce that I successfully burned all of my monthly tokens in under 3 days thanks to your garbage new pricing model.
I'd also like to inform you that I won't be renewing my subscription or adding more budget.
Best,
A former customer.
@danieltvela@The_Only_Signal It really is... but then what would we call Qwen3.6 35B A3B (called Qwen3.6 Flash by Alibaba) running at 160tps on a single rtx 3090 with 262k context in vLLM vs 37 tps 27B then?
@The_Only_Signal Qwen 3.6 27B is such a ridiculous outlier in our testing that we had to re-evaluate our whole methodology. Data holds up. Incredible amount of intelligence AND agentic tool progress packed into a small param count.
Data at gertlabs.com/rankings
@CarlosZarattini Deixa ver se eu entendi sua posição: então o dado que desmonta essa mentira de vez diz que menos de 3% dos beneficiários trabalham de carteira assinada... Puxa, 3% é realmente um desmonte...
Absurda e desinformada essa declaração contra o Bolsa Família. É inadmissível que ainda seja preciso repetir o óbvio.
O Bolsa Família é, sim, um estímulo à mobilidade social. O programa garante comida na mesa de quase 50 milhões de brasileiros e ajuda famílias inteiras a atravessarem a pobreza com dignidade.
Entre 2023 e 2024, 8,6 milhões de pessoas saíram da pobreza e 1,9 milhão deixou a extrema pobreza no Brasil.
E o dado que desmonta essa mentira de vez: em 2024, beneficiários do Bolsa Família ocuparam 1,2 milhão de postos formais de trabalho.
Quem diz que o Bolsa Família “acomoda” simplesmente despreza a realidade do povo brasileiro.
poder360.com.br/poder-economia…
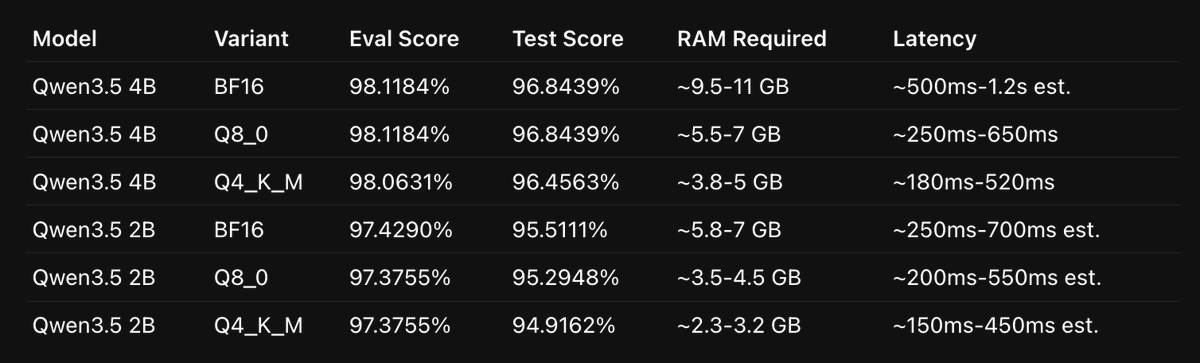
Qwen 3.5 has the best SLMs to fine-tune!
Its 4B model is really smart if you train it on a well structured dataset.
I fine-tuned the model on a 135M dataset generated by Codex 5.5 + DeepSeek v4 Pro.
I achieved 96%+ accurate results with Qwen 3.5 4B.
And 95% on Qwen 3.5 2B (that only requires 3.5GB RAM).
For context, on the same pipeline:
> Sonnet 4.6 achieved 89%
> GPT 5.4 Mini achieved 85%
> Haiku 4.5 achieved 72%
I don't trust evals, so I ran a 7000+ row hard-boundary test, and the results of Qwen 3.5 were consistent.
A 4B fine-tuned model beating a 20x bigger model in accuracy and latency is no joke.
It cost me $173 in total to generate the dataset and cover the cloud GPU cost to fine-tune both models.
I said this before, and I'll say it again: not everything requires a 1T-parameter LLM. We need ELMs (Expert Language Models) that are specialized for one domain only.
ELMs > LLMs.
I'll be writing more about how SLM fine-tuning works. So stay tuned.
@TeksEdge While anyone with a much cheaper RTX 3090 can run Intel/Qwen3.6-35B-A3B-int4-mixed-AutoRound with vLLM at 150t/s without MTP with fp8 kv cache and 128k context.
🤯 Unsloth released the fastest Qwen3.6-27B MTP GGUF I've tested. Time to upgrade.
Compared to the previous GGUF, Q4/Q6 XL versions are 👀 ~55% faster!
On a single RTX 5090:
✅ 114 tok/s — UD-IQ2_M (MTP)
✅ 93 tok/s — UD-Q4_K_XL (MTP)
✅ 75 tok/s — UD-Q6_K_XL (MTP)
💨Fastest MTP quant is 3.3x faster than the old Q8_0 baseline (35 tps)
262K context + tool calling. All on one 5090.
* compiled from the MTP PR branch ('am17an:mtp-clean', build b9117-ebe4fca4b)
@loktar00 27B quality with 35B tps would be a dream with 3090. But all those inflated numbers with 27B and 3090 are unreal and quality compromised... 35B with vLLM is so stable that I stopped searching for a better alternative with a single 3090.
@malikwas1f@largePrawn I did... Several times, since day-0 and also today. No more then 60 tps with 2x3090. Much better tps with single gpu and qwen3.6 35B (130 tps) without even spec dec.
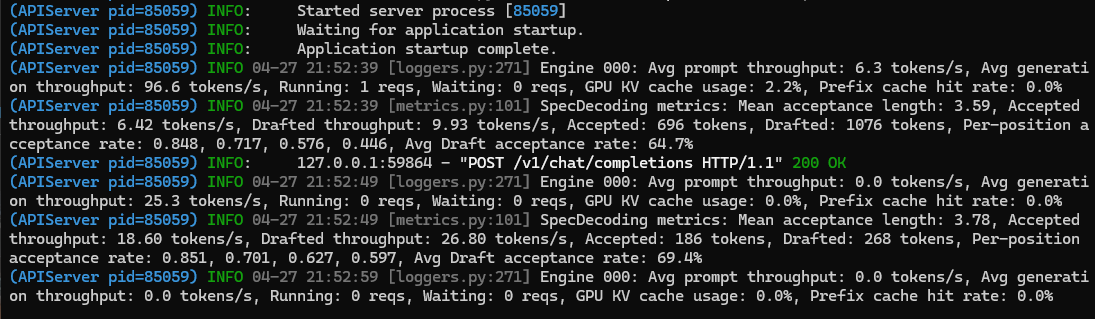
Hitting 140 tok/s on Qwen 3.6 27B
running vLLM with 2x 3090s using the following @malikwas1f's repo
github.com/noonghunna/clu…
Literally just pointed claude at it and walked away. Came back to a 2.5x speed bump 🤯🤯🤯
@rafaon3@luksamuk A3B tá lento, tenta o Intel/Qwen3.6 35B AutoRound com vLLM, consigo 130 tok/s com ele e 60 tok/s com o Qwen3.6 27B, mas não uso pq esses modelos pensam d+ e 60 tps fica extremamente lento para codar com 128k tokens.
Até agora, o coding champion aqui, numa RTX 3050 com 6GB de VRAM foi o Qwen 3.6 35B-A3B.
Quantização: UD-Q3_K_L. Arquitetura MoE ajuda com velocidade; qualidade inigualável; bom tradeoff com velocidade.
Não duvido que o 27B faça coisa melhor, mas é lento que dói (limitação minha)
@EnioViterbo Que moral ele tem pra falar assim? Mundo louco esse, ministro do STF fingindo que embolsar +80 milhões e tá tudo bem, vida que segue. Só no Brasil.
Pelo amor de Deus.
Se controla, Alexandre.
O ministro Alexandre de Moraes aproveitou o julgamento de um processo do deputado Gustavo Gayer contra um outro deputado e simplesmente começou a mandar indiretas para o Romeu Zema.
Um completo desvio de finalidade.
Um desrespeito com o dinheiro público.
Um desrespeito com o Direito e com o processo penal.
Um desrespeito com o STF.
Os ministros Alexandre de Moraes e Gilmar Mendes têm que aprender que não é porque tem um microfone ali na mesa que eles podem falar qualquer coisa.
A sessão de julgamento dos processos é DOS PROCESSOS.
Não é pra cantar.
Não é pra recitar poesia.
Não é pra mandar recados políticos.
Se quiserem um microfone e uma bancada para dar recados políticos, candidatem-se ao Congresso.
@MemoryReboot_ I'm getting 130-160 tok/s with one RTX 3090 and Intel AutoRound Qwen3.6 35B A3B without any spec dec. So you certainly have a regression in speed here.
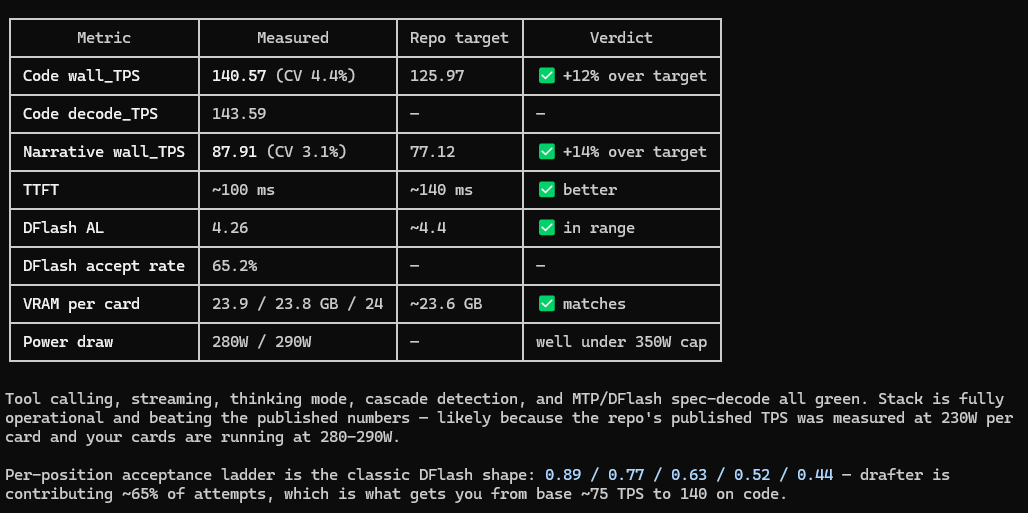
DFlash benchmarks on dual RTX 3090
Qwen3.6-35B-A3B AWQ-INT4 + DFlash drafter on vLLM nightly, TP=2
Tried different num_speculative_tokens to find what works:
- n=4: 96.6 tok/s
- n=8: 96.0 tok/s
- n=15 (z-lab's recommended): 20-40 tok/s
n=4 is a sweet spot
For comparison, Qwen3.6-35B-A3B Q6 on llama.cpp gives me 102 tok/s on the same hardware ☹️
What am I doing wrong?
@spiritbuun Still slower... forgot to mention that gguf model used is: lmstudio-community/Qwen3.6-27B-GGUF
cmake -B build --fresh \
-DGGML_CUDA=ON \
-DGGML_NATIVE=ON \
-DGGML_CUDA_FA=ON \
-DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES=86