고정된 트윗

NobodyExistsOnTheInternet
465 posts
@nullvaluetensor
Human Large Language model. Skills: Distill data. Training LLMs. Test and Evaluate. Rinse and repeat as required. Based in SEA.

No, an 8GB of ram laptop is not “only for web browsing” you can code with it you can do graphic design you can do video editing you can run photoshop you can multitask Tech bros are subject to a massive bias where not a single one of them has tried an 8 GB of RAM computer in the last 5 to 10 years because they all default to thinking they’re unusable when they’re actually perfectly fine. it’s fine. mostly.

How to spot a Claude:

I've launched 12 sessions of GPT 5.4 pro on puzzles and will report in a few hours if it's any better than 5.2. Maybe enough time to finish a run in Slay the Spire 2.

Apple has introduced the M5 Pro and M5 Max, built on a new Fusion Architecture that merges two 3nm dies into a single SoC. Unlocking up to 30% faster CPU performance and over 4x peak GPU compute for AI versus the previous generation. With an 18-core CPU (6 “super cores”), up to a 40-core GPU featuring Neural Accelerators, and unified memory bandwidth reaching 614GB/s.




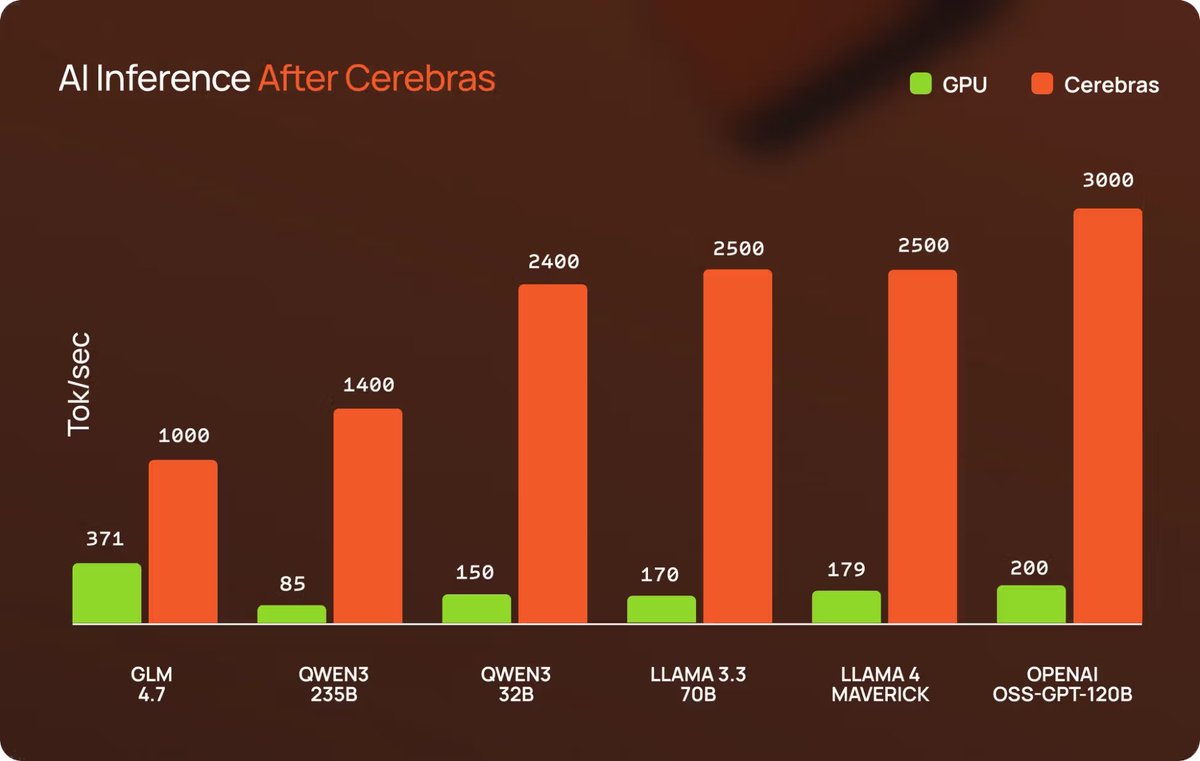
GPT-5.3-Codex spark delivers more than 1000 tokens per second running on Cerebras hardware It is available as a research preview to ChatGPT Pro users







suspiciously precise floats, or, how I got Claude's real limits link below

overnight run was a complete success, all 67 spawn templates are ported correctly. i switched from gpt-5.2-codex xhigh to gpt-5.2 xhigh. still trying to figure out the differences, but it seems like the 5.2 model is more thorough, it takes significantly longer.