고정된 트윗

Honored to share a major thread of my PhD research, out now in PNAS. We address a core issue with how models are used for scientific discovery.
Models are so important that they define the entire scientific process... 1/n
English
Caleb Ellington
575 posts

@probablybots
Scientist @genbioai | PhD @CMUCompBio | Creator/maintainer https://t.co/E3h3NJS6S7 | multi-task learning, graphical models, and personalized medicine




@probablybots Anyway, this is a good study. I just don't think it's great news for the current paradigm. Folks should take a good hard look at the results presented here and other recent work & think about where to invest efforts.
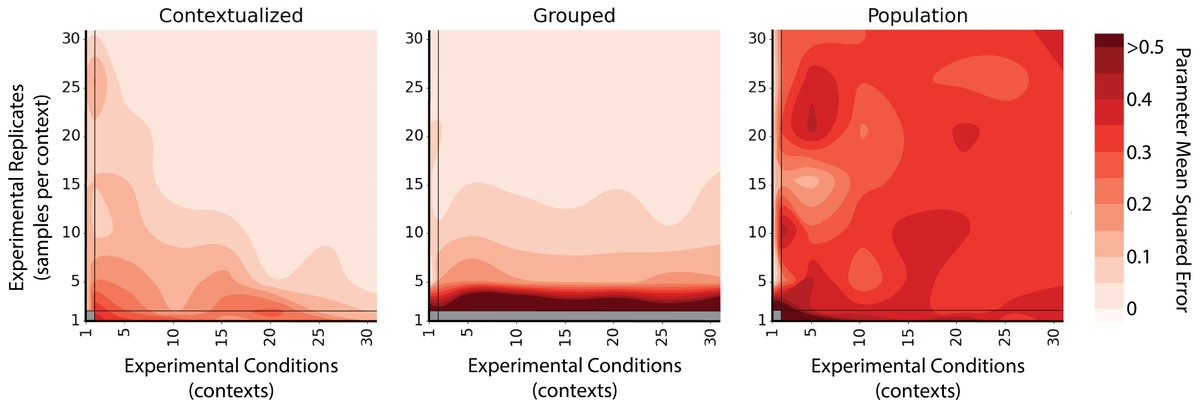
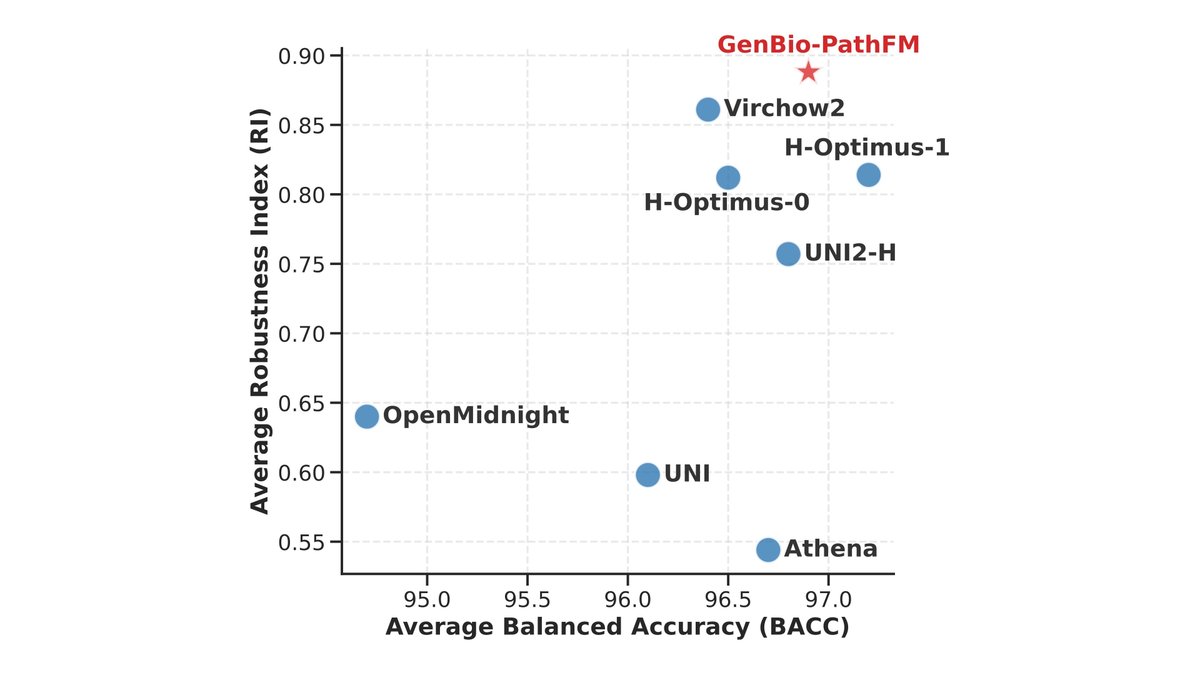
Predicting how cells respond to genetic or chemical changes is a fundamental challenge in drug discovery. While the potential of biological Foundation Models (FMs) has been widely discussed, their actual superiority over simple statistical baselines has remained a subject of significant debate in the field. In our latest preprint, we provide a definitive evaluation of FMs for perturbation prediction. By benchmarking over 600 model variants, we demonstrate that FMs, when trained on the right modalities and integrated effectively, provide a significant leap in predictive accuracy. Our findings confirm that FMs are not just a theoretical improvement, but a practical tool for building accurate, actionable simulations of cellular behavior. Preprint: biorxiv.org/content/10.648… Code and data: github.com/genbio-ai/foun… Blog post: genbio.ai/foundation-mod…




