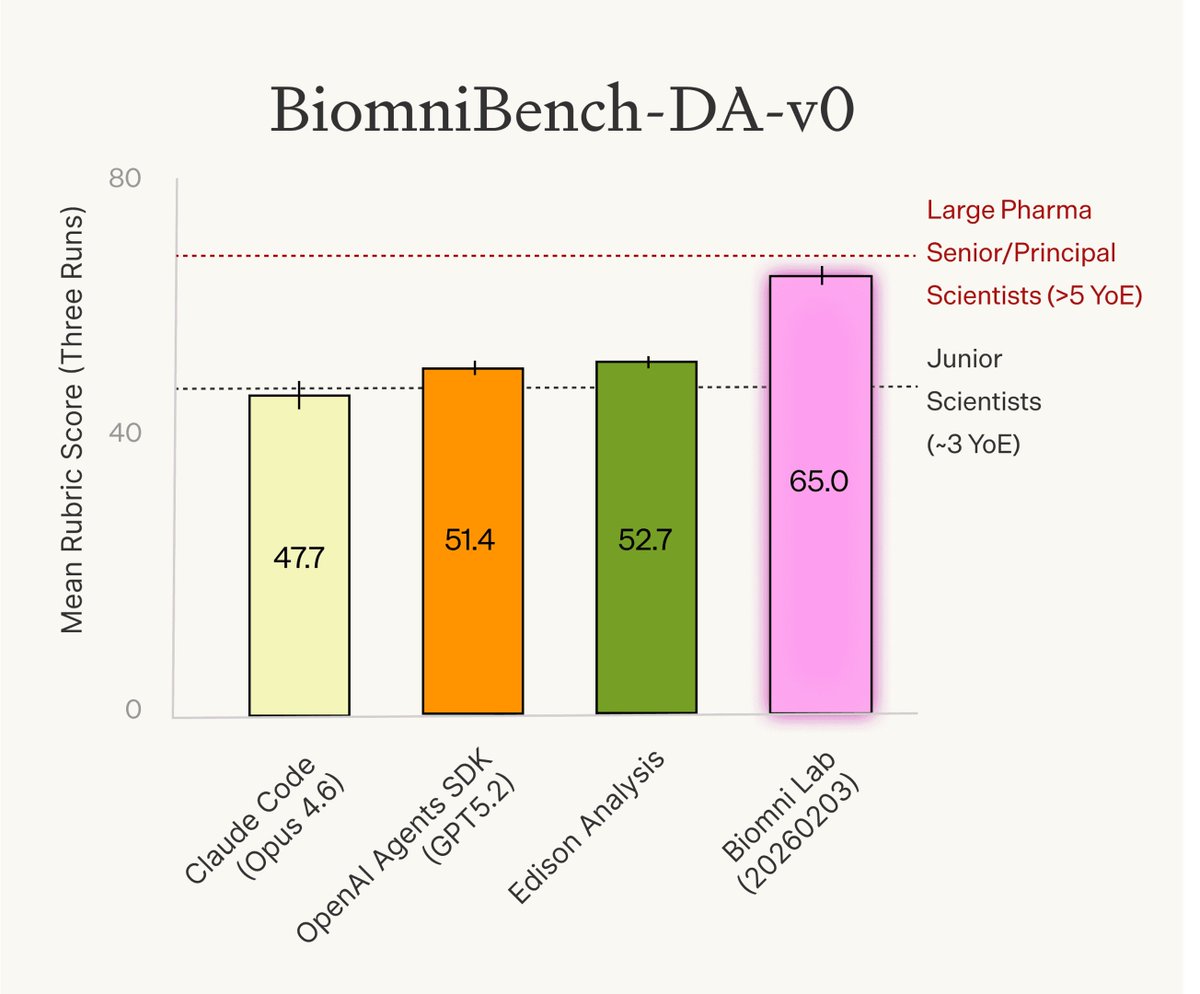
Biomni retweetledi

I’ve spent the past decade building bio AI models—until now, training them meant years, huge cost, and teams spanning AI, biology, and infra.
Not anymore.
Introducing a new capability at Biomni Lab: now any scientist can create, fine-tune, pre-train, and optimize bio foundation models on their own datasets, just by describing what they want.
This is powered by a new feature called GPU-as-a-tool where we let AI agents launch and orchestrate GPU sandboxes.
In the video, we show that you can use prompt to:
- Fine-tune Borzoi for MPRA regulatory activity prediction
- Fine-tune scGPT on a H1 hESC perturb-seq data
- Fine-tune ESM2 for protein subcellular localization prediction
- Pre-train a protein language model from scratch on UniRef
- Build a novel multi-task ADMET model across 22 endpoints
Another big challenge once you’ve trained or have access to a model is actually using it productively. As it is embedded within Biomni Lab, it bridges that gap, letting you “ask the model” to identify and prioritize relevant biological insights directly.
Another exciting direction is lab-in-the-loop: scientists can design models, generate predictions, interpret results, and send them to the wet lab—all within one integrated biology environment.
This is a preview capability and we’re looking for beta testers. Sign up here for early access: forms.gle/1yhCP6Vrc12DaS…
Learn more about opportunities and limitations in our blog: phylo.bio/blog/ai-agents…
@phylo_bio
English