Paper: nature.com/articles/s4158…
Code: github.com/snap-stanford/…
Thanks so much to the team @YanayRosen @yusufroohani @StephenQuake!
English
Jure Leskovec
1.5K posts
@jure
Professor of #computerscience @Stanford; Co-founder at https://t.co/hhm1j5wP0f #machinelearning #graphs.







Relational Foundation Models face a scaling problem: diverse training datasets are rarely public due to privacy constraints 🔒. 🚀 We are excited to introduce "PluRel": a framework that synthesizes diverse multi-table relational databases from scratch, unlocking scaling laws for RFMs. 🧵 Kudos to the amazing collaborators at @StanfordAILab @Kumo_ai_team , and @SAP : @_rishabhranjan_ @VHudovernik @vijaypradwi @johanneshoffart @guestrin @jure

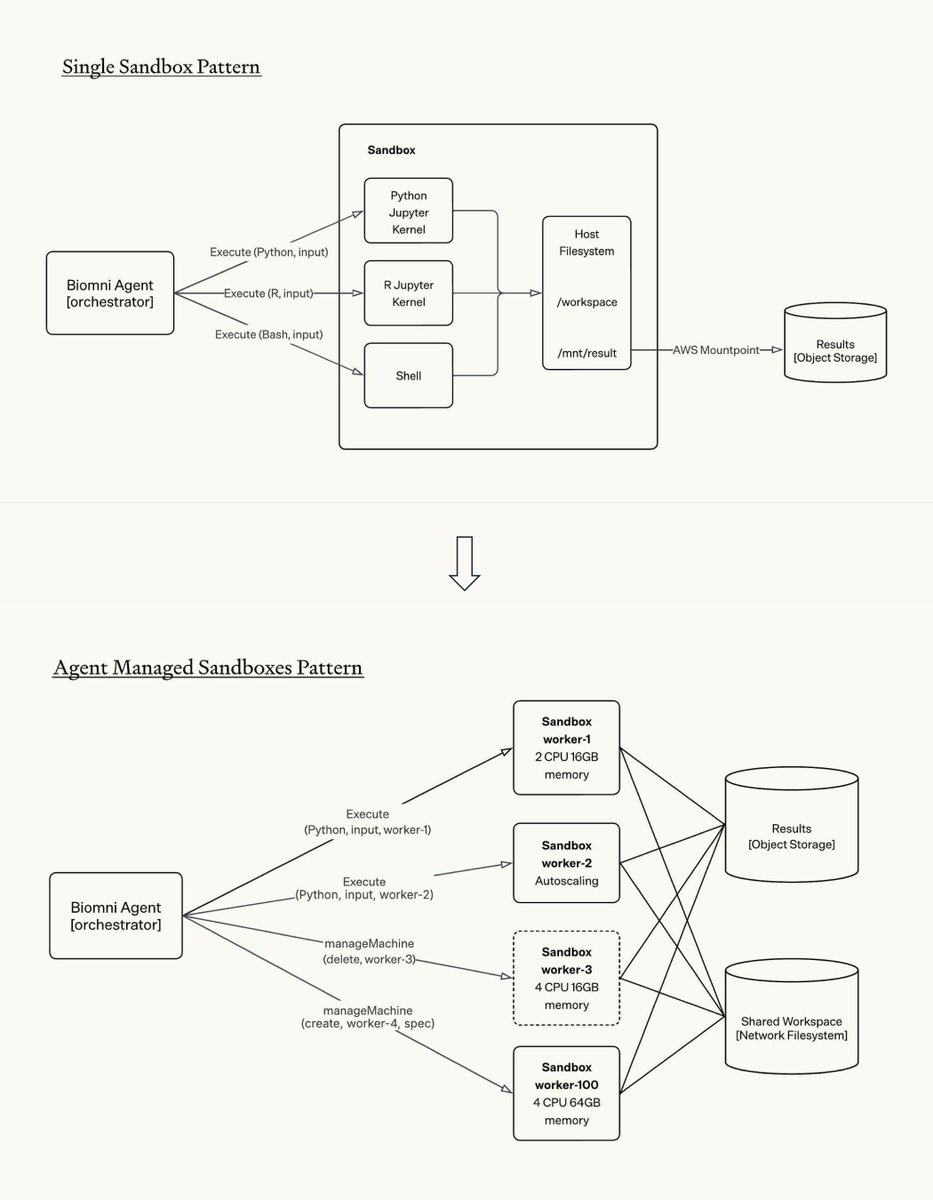
We get this question a lot: "Which model is best for drug discovery?" Our new benchmark announced today with @ScaleAILabs, DrugDiscoveryBench (82 tasks from working drug discovery scientists, run on Biomni Open Source Environment), has a clear answer: the model matters far less than what you build around it. 🧵3 key takeaways →


Can coding agents do research? We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵


Introducing the Genetic Target Hypothesis skill, co-developed with Prof. Manuel Rivas at Stanford, which transforms rare-variant burden statistics from UK Biobank into ranked therapeutic target hypotheses in minutes. In a BMI/obesity case study, the system rediscovered canonical biology such as MC4R with the correct inhibit/activate direction, while surfacing novel candidate targets for follow-up. Learn more in the blog post: phylo.bio/blog/turning-u…