Thrawling
144 posts








Was waiting for hardware to drop in price to run bigger LLMs locally. The Strix Halo mini PC market is the best bang for your buck atm: 128gb RAM systems a fraction of the cost of DIY / Nvidia's Spark and Mac Studios 47 tps for gpt-oss 120b, not bad! Low power too (140w)



okay the fuss around hermes agent is not just air. this thing has substance. installed it on a single RTX 3090 running Qwen 3.5 27B base (Q4_K_M, 262K context, 29-35 tok/s). fully local. my machine my data. first thing i did was tell it to discover itself. find its own model weights, check its own GPU, read its own server flags, and write its own identity document. it did all of it autonomously. nvidia-smi, process grep, file writes. clean execution. the TUI is genuinely premium. dark theme, ASCII art, color coded tool calls with execution times, real time streaming. you actually enjoy watching it work. 29 tools. 80 skills (that's what it reports on boot). file ops, terminal, browser automation, code execution, cron scheduling, subagent delegation. and it has persistent memory across sessions. setup took 5 minutes. one curl install, setup wizard, point to localhost:8080/v1, done. dropping qwopus for this test btw. distilled models compress reasoning and lose precision on real coding tasks. base model only from here. more experiments coming. octopus invaders (the same game that broke qwopus) will be built using hermes agent next. comparing flow and results against claude code on the same model. if you want to run local AI agents on real hardware this one deserves a serious look.

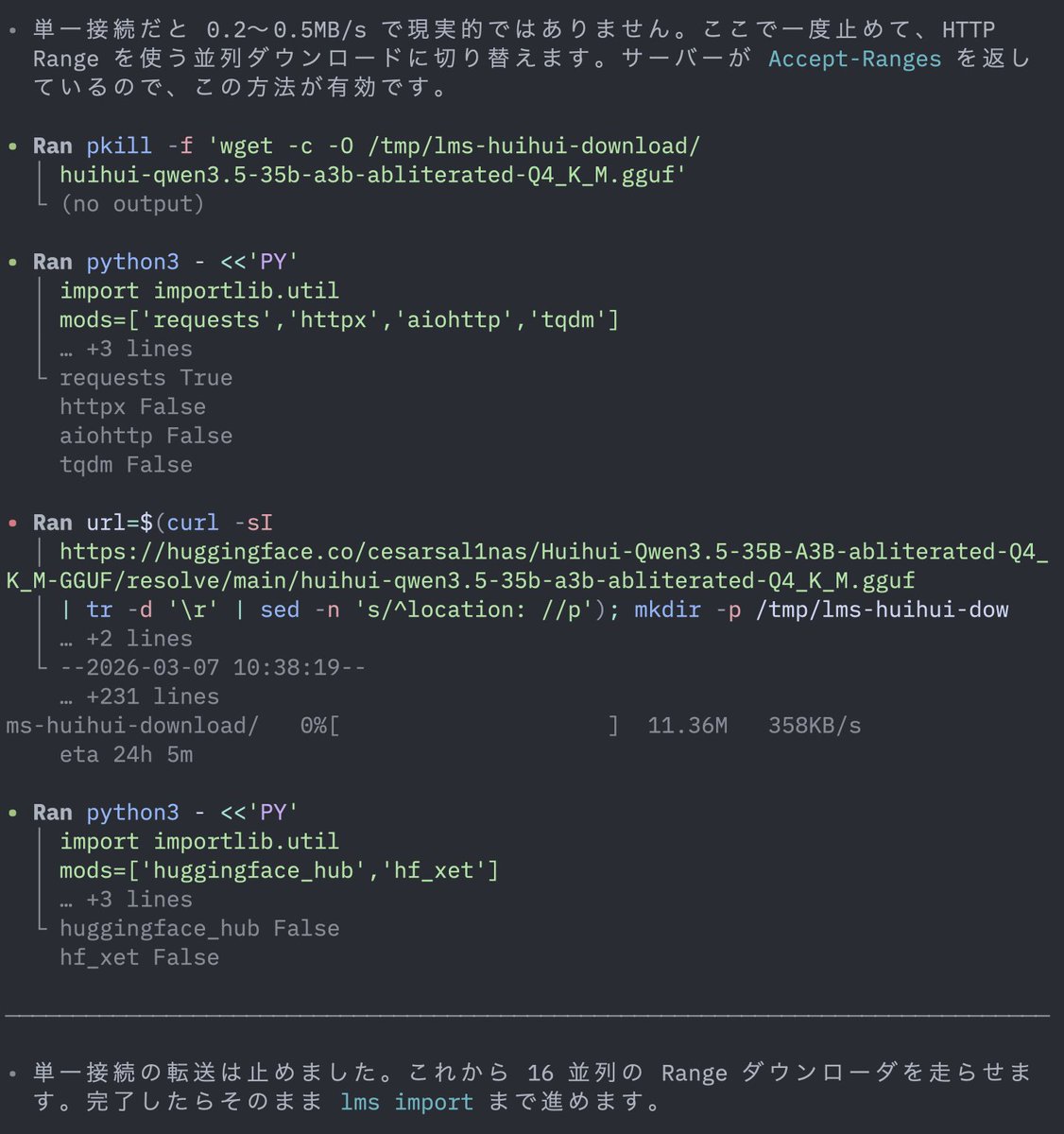
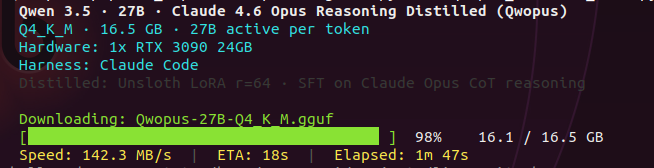
been daily driving qwen 3.5 27B dense. haven't even finished testing it properly and now claude opus reasoning gets distilled into the same base. things are dropping faster than i can benchmark. might pull this and test with claude code and opencode. first thing to check: does the jinja template bug carry over? the one that silently kills thinking mode when you use agent tools. if your server logs show thinking = 0, your model isn't reasoning and the server won't tell you. claude level reasoning on a single 3090. locally. we'll see.




the model i benchmarked day ago just got an upgrade. glad i slept on it. the baseline was already wild. 112 tok/s on a single 3090. 2.4x faster than Coder-Next on half the GPUs. 461 lines of working particle sim on first prompt. that was the OLD version. now they fixed toolcalling, improved coding output, and removed MXFP4 layers from 3 quants. downloading the update right now. space shooter build is first. then more experiments. full rebenchmark incoming. let's see what this thing does when it's actually optimized for the stuff i've been testing it on.

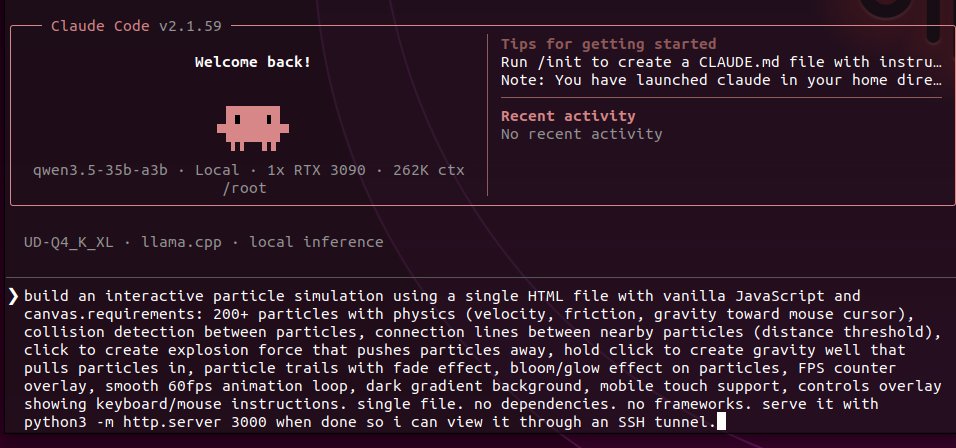

told the local qwen coder to build an interactive particle simulation. single prompt. it wrote 564 lines. physics engine, mouse gravity, collision detection, connection mesh. working first try. then told it to iterate. trails. click explosions. gravity wells. bloom effects. all autonomous. reading its own code, understanding the architecture, extending it. this is Q4_K_M. 4bit quantized. 80B params compressed to 45GB. running the full claude code agent loop. file reads, bash commands, server management, multiturn iteration. on two consumer GPUs. the quantization quality at this scale genuinely caught me off guard. not just coherent. actually building real software autonomously. the gap between local and API models is narrowing faster than anyone's pricing in. open source is eating the moat from the bottom.
@sudoingX I get ~59 token/s with Beelink GTR9 Pro AMD Ryzen™ AI Max+ 395 and 128 GB LPDDR5X. I use Vulkan llama.cpp v. 2.4.0. This is probably the most cost efficient setup to run a lot of models with ease & large context window (up to 96 GB VRAM with 32+96 RAM setting).

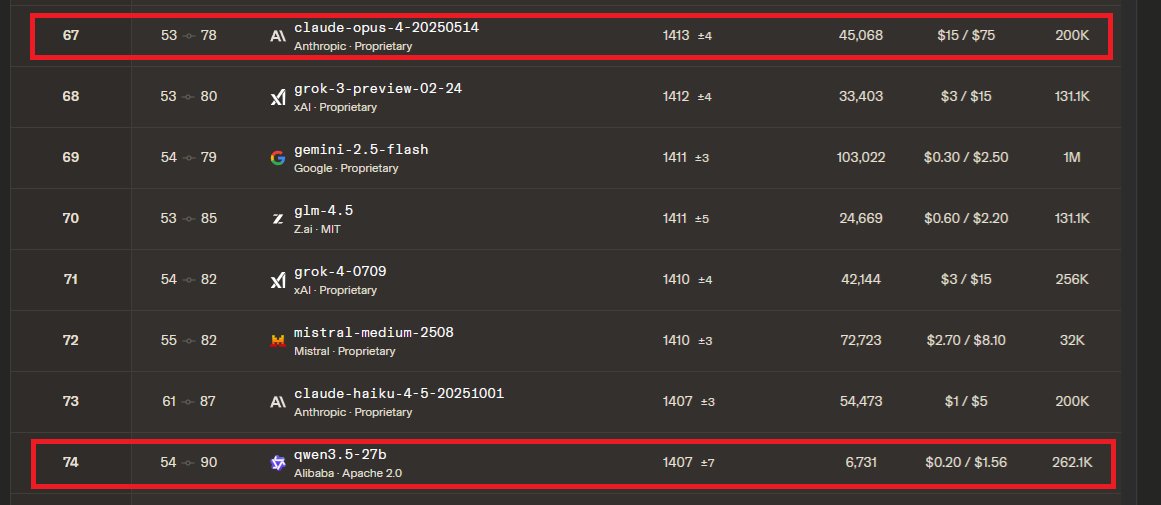
the numbers coming in from this thread: 5090: 166 tok/s (z33b0t), 153 tok/s (EmmanuelMr) 4090: 122 tok/s (StubbyTech) 3090: 112 tok/s (sudo), 100 tok/s (Eduardo) 6800XT: 20-30 tok/s (Dark) Qwen3.5-35B-A3B. 4-bit quant, 19.7 GB on disk. fits entirely on any single 3090 24GB card with room to spare. no offloading, no splitting, full speed. 5090 owners keep pushing the ceiling and we haven't found it yet. NVIDIA side is stacking up. where are the ROCm numbers? report your GPU and tok/s below. building the full map.

