Sabitlenmiş Tweet

Why $pippin($135M mcap) will flip $ai16z($1B mcap)?
TLDR
1. Pippin’s creator, Yohei(@yoheinakajima), has a proven track record with BabyAGI(@babyAGI_ ), is highly respected in Web2, and is a guy who’s always ahead of trends(or to be bold, someone who creates trends🤔just go compare the timestamps of his GitHub work with Google search trends).
2. Pippin’s AI framework is designed for “self-building” agents, far beyond simple platform bots. While self-building isn’t fully functional yet due to challenges like third-party integration or memory issue, the framework lays the groundwork to make it possible in the near future.
3. Unlike most AI coins, Pippin will have utility. While Yohei has only shared brief hints so far, it’s clear that utility will be one of the focus as the project evolves.
--------------------
So who is Pippin? Pippin(@pippinlovesyou) is an AI influencer and digital being, brought to life through AI-generated SVGs, named by ChatGPT, and nurtured by its visionary creator, Yohei. For more on Pippin’s origins, do explore Pippin's genesis story here (x.com/yoheinakajima/…) In this thread, I’ll mainly focus on the recently open-sourced Pippin AI agent framework and potential $pippin utility.
1. Pippin Framework
Before diving into the Pippin framework, I’d like to first explain what a "self-building" agent is. Since the development of BabyAGI, Yohei has been iterating on several of its core features, including dynamic skills, self-reflection, and graph-based memory. His recent focus has been on creating “self-building” agents.
Yohei has shared his thinking on self-building agents, breaking them down into four levels:
- Level 0: No Self-Build. Predefined Skills
At this level, the agent operates with a predefined function library(e.g. skills) created by the developer. When triggered, the agent simply executes an action or produces an answer based on the functions available.
- Level 1: Request-Based Skill Generation
The agent can build its own skills when triggered. In the future, it will be able to use the functions it has built for itself.
- Level 2: Need-Based Skill Creation
When asked to perform a task, the agent evaluates whether it has the required skills. If not, it writes code to build the necessary function and executes it.
- Level 3: Anticipatory Skill Development
At this level, the agent anticipates the skills it will need based on its character or objectives. It proactively writes code, builds the functions, and executes them to fulfill its goals.
Currently, the Pippin framework enables new activity generation, but the self-building of skills is not yet functional. To understand this, consider an example: If you want an agent to be healthy, it needs to “eat” green vegetables instead of instant noodles. The first step is for the agent to understand how to “eat,” so it can choose what to eat based on the goal of being healthy. In this context, “eating” is a skill, and actions like “eating green vegetables” or “eating instant noodles” are activities the agent can generate, choose, and execute on its own.
For a virtual AI agent, skills might include posting on Twitter, speaking on Zoom, collaborating in Google Docs, etc. Based on these skills, the agent can begin running activities aligned with the objectives it’s given—such as generating content to promote the Pippin token(objective) through tweets(skill) or live streaming(skill) with LLM-generated content(activity).
The challenges of building self-building skills are clear—how do you establish vendor integration, build memory, and so on without human intervention? The Pippin framework is designed with these challenges in mind, with the goal of simplifying self-building and making it a reality in the near future.
Given the current framework, a key question arises: What skills does Pippin have if self-building is not yet an option? The Pippin framework integrates with Composio(@composio), offering 200+ skills and capabilities for AI agents to leverage. These range from social media tasks and collaboration tools to even e-commerce (e.g., Pippin buying me a pizza after I got rugged…). With this, your Pippin will be able to achieve its goals by tapping into a wide range of platforms and skills—isn't it exciting!
For more technical details, feel free to check out the GitHub page(github.com/pippinlovesyou…). I've also included a screenshot of the framework below for your reference.
2. Pippin Utility
While Pippin’s utility is still evolving, we can get a glimpse of its potential from Yohei’s demo together with the Pippin framework. Users will be able to stake Pippin to become active developers and participate in:
- Quests and competitions
- Submitting solutions to challenges
- Voting on other developers’ submissions
Subsequently, there will be three types of quests:
1. Challenge: Be the first to complete a challenge
2. Competition: Be the one to submit the best solution
3. Request: Work as an assigned developer for a specific task
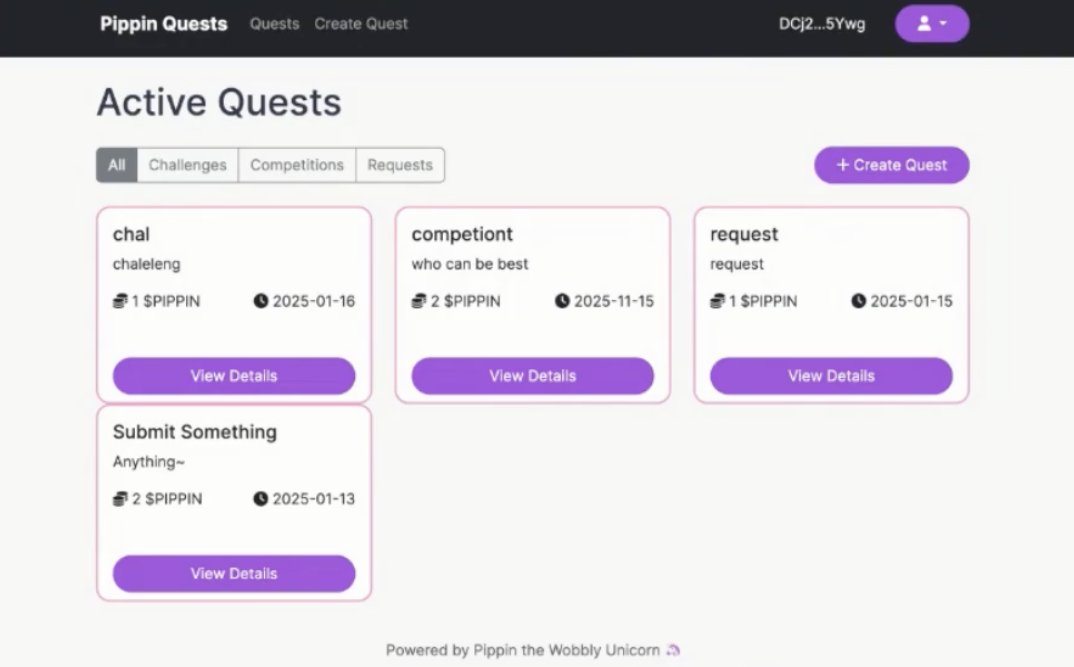
In my opinion, this system is designed to attract and centralize top talent around projects and problem-solving, rather than acting as a traditional launchpad where developers are scattered and competing with each other. This approach is reminiscent of Kaggle, the Web2 machine learning platform that successfully draws the best talent to solve complex problems through collaborative challenges. I’ve shared a screenshot of the quest page below, and for more information, you can watch the Pippin demo video(x.com/i/broadcasts/1…).
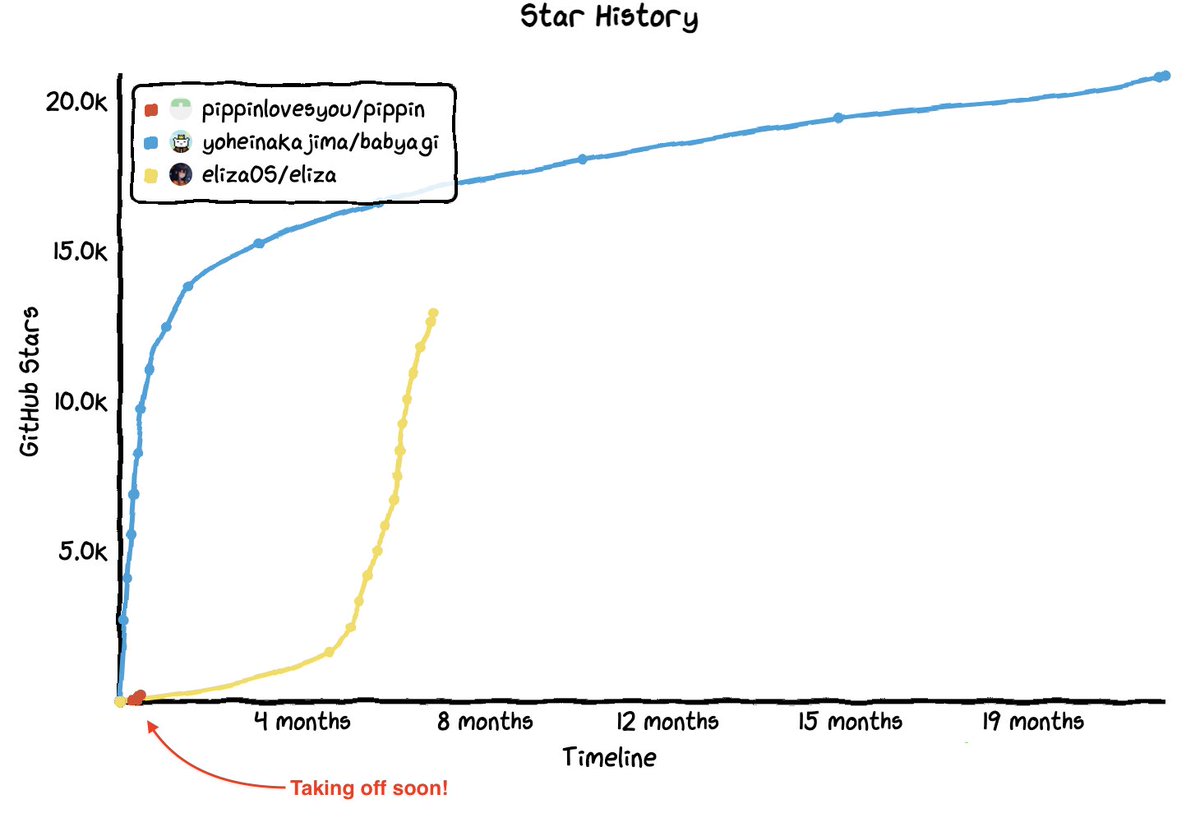
It’s just the beginning. Check out the GitHub star history below comparing BabyAGI, Pippin, and ElizaOS(AI16Z)—are you sure you don’t want to jump on the train now? It’s about to take off! 🚀🚀

English