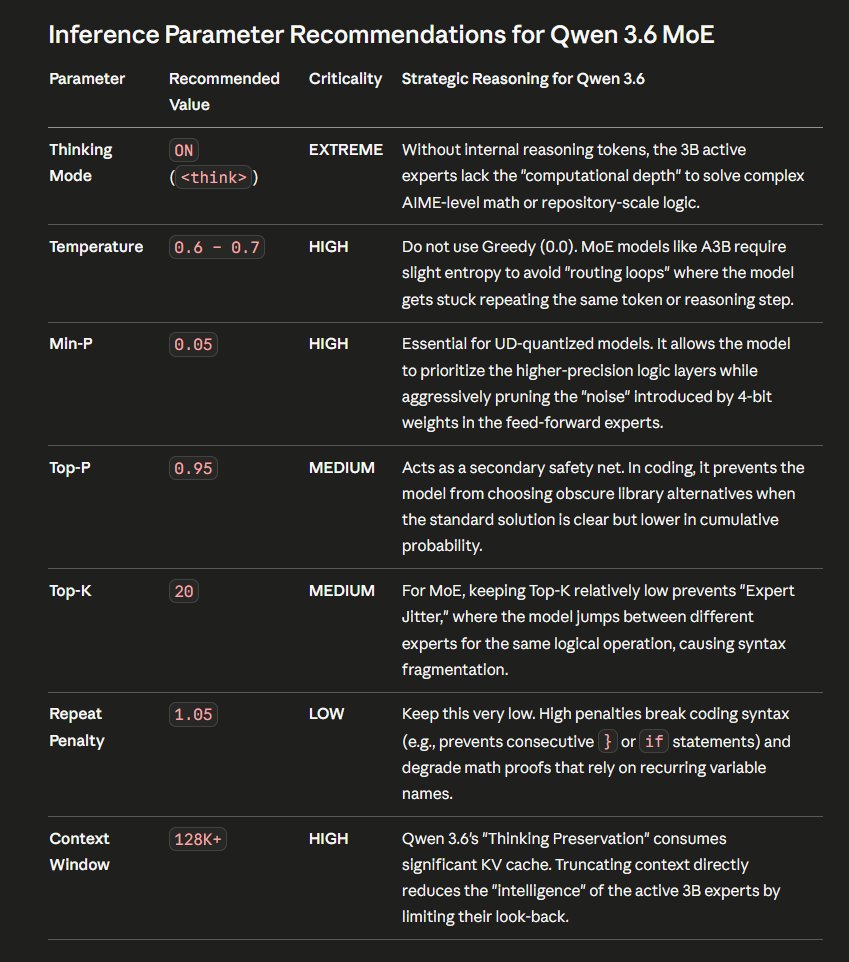
Use llama.cpp compiled from source, which updates almost daily. Codex, Claude Code, Hermes, or Openclaw can do this for you. Just ask it to install lllama.cpp and Qwen3.6 27B or 35B MTP. LM Studio is essentially a graphical user interface (GUI) built on top of llama.cpp.
Model Compatibility: Both use the GGUF format. You can download a model in LM Studio and then point standalone llama.cpp to the same file to run it, or vice versa. If you need a GUI for llama-server add Open WebUI
English