
XpeGj0
63 posts


Yeah it’s crazy. I got a new macbook to replace my old M1, I got an 24gb M5.
Running a 9b q4 locally is slow af, I can’t.
Then I just send requests to to my rig remotely, running qwen3.6 27b q8 and there is no comparison in the speed. GPUs are on another level.
As usual, the buy a gpu guy was right lol
I did not get the mac to do inference or anything but I thought it was faster. A bit disappointing
English

"Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought"
Do reasoning models really need to think in words?
This paper replaces long verbal CoT with a short learned sequence of abstract tokens that acts like a latent scratchpad.
Warmed up from verbal CoT, then distilled and improved with RL.
Resulting up to 11.6x fewer reasoning tokens while staying competitive with standard CoT.

English

@SergioHidalAERO Exijimos otro video hablando de los nuevos videos que publicaron 🙂
Español

Veo muchisma gente hablar de OVNIS y creo que muchos aun no conocen la historia en la que varios pilotos de caza se toparon con uno
Preparaos para alucinar
youtu.be/fF_MvxOxqCE?is…

YouTube
Español
@AthofReligion @Science_TechTV But they also murdered women who practiced folk healing in the same era.
English

@Science_TechTV Also of note, Newton believed in the resurrection and the second coming of Christ.
English

Isaac Newton's college notebook, handwritten by the genius himself around 1664.



English
@agusbuilds @gabmfrl Es una pena. Aumentan el tamaño del modelo y miran que habilidades emergen despues del entrenamiento. Es la única manera segura y fácil de mejorar el modelo y poder competir en un mercado tan competitivo.
Así no podemos adaptar la AI en la sociedad.
Español

@224Shroud @gabmfrl Yo ahora mismo creo que no lo han puesto disponible porque no pueden servirlo a un precio razonable
Español

Supongo que pueden haber muchas variables que no vemos explicando parte de estos resultados.
Pero ojalá sigan sacando evidencia que vaya solidificando el caso de qué tan capaz es realmente Claude Mythos aplicado en el mundo real.
Y además no es un gráfico de esos engañosos que se sacan algunos labs a veces (ejem), la diferencia realmente ha sido muy pronunciada.
Alex Albert@alexalbert__
With the help of Claude Mythos Preview, the Firefox team fixed more security bugs in April than in the past 15 months combined.
Español
@agusbuilds @gabmfrl No las cumplira, va a estar carisimo y aparte de eso, estara limitado por el computo. Simplemente están inflando el valor del modelo.
Español
@gabmfrl Menudas expectativas está generando este modelo. Cuando lo lancen para todos, veremos si las cumple
Español
@fbjoe @alex_whedon It better be true, I want open source models to adopt this architecture
English

Look I would love to use it first before I call BS but so far it's empty promise just like you said and I am not disagreeing with you
BUT
Remember how Deepseek able to train their stuff simply by adjusting some params that are so simple to achieve desired outcome?
I am saying what they promised might be possible but remain skeptical until I see it and try it out.
English

Hey, folks! We have been blown away by the response to SubQ and the SSA breakthrough over the last 48 hours.
It is awesome to see how many people are responding to our mission of creating more efficient algorithms to create better models.
We are working hard to firm up our release timeline and will share more very soon.
We will also share additional data and third-party validation in our model card next week.
If you have questions, please post them in the thread, and I'll do my best to respond!
Above all, THANK YOU! The support, feedback, and discussion from this community have been inspiring.
English
@fbjoe @alex_whedon To overvalue their company. How long will it take the big Ai companies to copy and invest in this architecture?
If it’s true, then this startup won’t have money to compete with the other models at the end it’s lose or lose. When they lose, they would lose but with a bag of money
English
@224Shroud @alex_whedon looks like a larp announcement why announce it without giving ppl to try is this like trying to raise money?
for VCs doing DD on this please actually try the product and do the benchmark runs.
English

@digitalix 144GB HBM on PCIe. Impressive specs until you realize interconnect bandwidth is what actually limits distributed training at scale.
English

New "GPU" with 144GB HBM - AMD Instinct MI350P, BUT IT's PCIe!

English
@alex_whedon Question for anyone on X : has anyone got their hands on this subq coding plan yet?
English

Let me make local AI easy for you
Give Codex Cli the tweet below & tell it:
- Infer the right Inference Engine from your hardware + tweet content below
- Use uv+venv
- Pick the right kernels
- Tune flags, batching, KVCache, etc
- Optimize for your hardware & chosen model
Enjoy
Ahmad@TheAhmadOsman
You don’t pick an Inference Engine You pick a Hardware Strategy and the Engine follows Inference Engines Breakdown (Cheat Sheet at the bottom) > llama.cpp runs anywhere CPU, GPU, Mac, weird edge boxes best when VRAM is tight and RAM is plenty hybrid offload, GGUF, ultimate portability not built for serious multi-node scale > MLX Apple Silicon weapon unified memory = “fits” bigger models than VRAM would allow but also slower than GPUs clean dev stack (Python/Swift/C++) sits on Metal (and expanding beyond) now supports CUDA + distributed too great for Mac-first workflows, not prod serving > ExLlamaV2 single RTX box go brrr EXL2 quant, fast local inference perfect for 1/2/3/4 GPU(s) setups (4090/3090) not meant for clusters or non-CUDA > ExLlamaV3 same idea, but bigger ambition multi-GPU, MoE, EXL3 quant consumer rigs pretending to be datacenters still CUDA-first, still rough edges depending on model > vLLM default answer for prod serving continuous batching, KV cache magic tensor / pipeline / data parallel runs on CUDA + ROCm (and some CPUs) this is your “serve 100s of users” engine > SGLang vLLM but more systems-brained routing, disaggregation, long-context scaling expert parallel for MoE built for ugly workloads at scale lives on top of CUDA / ROCm clusters this is infra nerd territory > TensorRT-LLM maximum NVIDIA performance FP8/FP4, CUDA graphs, insane throughput multi-node, multi-GPU, fully optimized pure CUDA stack, zero portability (And underneath all of it: Transformers → model architecture layer → CUDA / ROCm / TT-Metal → compute layer) What actually happens under the hood: > Transformers defines the model > CUDA / ROCm executes it > TT-Metal (if you’re insane) lets you write the kernel yourself The Inference Engine is just the orchestrator (simplified) When running LLMs locally, the bottleneck isn’t just “VRAM size” It isn’t even the model It’s: - memory bandwidth (the real limiter) - KV cache (explodes with long context) - interconnect (PCIe vs NVLink vs RDMA) - scheduler quality (batching + engine design) - runtime overhead (activations, graphs, etc) (and your compute stack decides all of this) P.S. Unified Memory is way slower than VRAM Cheat Sheet / Rules of Thumb > laptop / edge / weird hardware → llama.cpp > Mac workflows → MLX > 1–4 RTX GPUs → ExLlamaV2/V3 > general serving → vLLM > complex infra / long context / MoE → SGLang > NVIDIA max performance → TensorRT-LLM
English

@224Shroud @0xSero Yeah the real issue is the thinking loop. Gemma won't do this since they baked in a system prompt but that's a trade off with other effects.
English

New best local model for y'all
16GB-64GB rejoice, the chosen one has arrived.
huggingface.co/Qwen/Qwen3.6-2…
English

@HuggingModels is it better than nano banana or chatgpt image 2.0 ??
English

Ever wanted to generate high-quality images from text prompts? Meet Dustoevsky/pornmasterZImage_turboV35Fp8, a powerful text-to-image model from the US. It's built for fast, creative image generation, perfect for artists and developers alike.

English

>be me
>have $2000 and no life
>buy two RTX 3090s on eBay
>"used but good condition" my ass one has thermal paste the color of mayonnaise from 2018
>open a window, close every other door in the house
>plug them into my motherboard like I'm wiring a bomb
>turn it on
>noise level: commercial jet taking off
>wifey: "what is that sound?"
>"it's just... science"
>she doesn't come back for 3 days
>now have 48GB VRAM total
>can run models that weigh more than my car
>lm studio running at 103.69.27.87:1234
>serve cold LLM responses from a room that's basically an oven in July
>electric bill arrives
>stare at it for 20 minutes
>"it'll be fine"
>want to remote into my little homelab without exposing ports
>install tailscale on everything
>now I can SSH into my GPU rig from literally anywhere
>my laptop connects like magic, no router config needed
>mDNS, exit nodes, funnel — all working out of the box
>"I'm basically a hacker now"
>sit in airport at 2am running benchmarks from my phone
>some random guy watches me typing furiously
>he thinks I'm doing illegal stuff
>I'm just waiting for qwen3.5-27b to finish inference on a poem about his mom
>send him the output anyway
>mfw I have more VRAM than most datacenters but less sleep than a college freshman
English
@TheAhmadOsman How about we talk about making the best LLM as a community!?!? And get rig of the big techs!?!?
English
@sven2401 @TheAhmadOsman Can’t scale it to 1T parameters, you would need it to be quantized at least 2 bits for the transistor to fit on a silicon warfare
English

@TheAhmadOsman It might be good for at home inference where you say okay GLM-5 / kimi k2.5 is good enough for my purposes and you might upgrade after 5-10 years or so like your pc. Assuming it scales to 1T models. But that would be a deliberate decision not wanting the newest best things
English
the “chip is the model” makes zero sense except for toys and niche stuff
this WILL NOT scale up to Kimi K2.5 level
otherwise OpenAI/Anthropic/Nvidia/Google would have jumped on it a long time ago lol
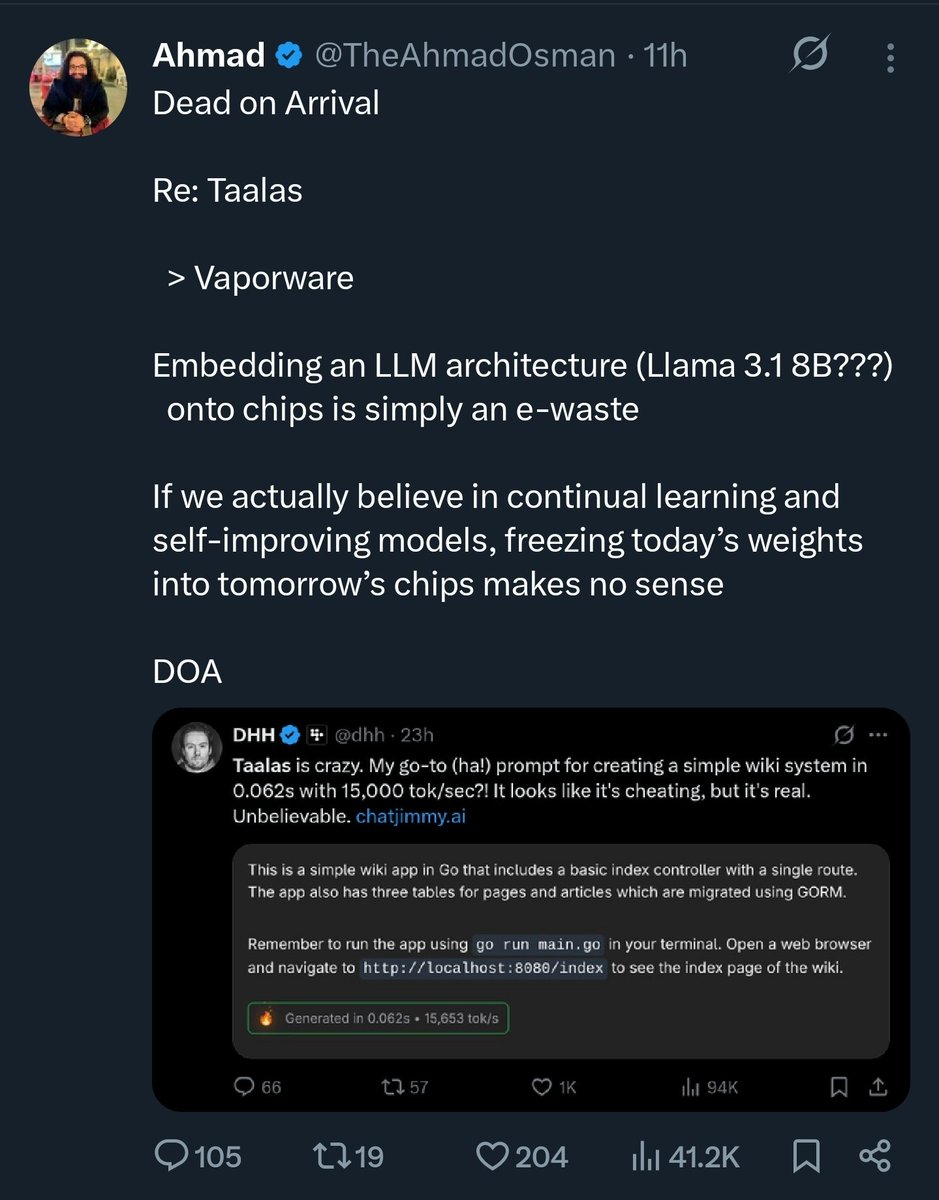
kyle@kylecompute
also aggressively dumb but cool proof of concept
English
@TheAhmadOsman Lowkey. Open source will only win if the community unites to make a model
English

@TheAhmadOsman Man 😭
I haven’t understand what’s the point of the dgx spak, bandwidth of a macbook pro.
English
@224Shroud It's already there :)
x.com/TheAhmadOsman/…
Ahmad@TheAhmadOsman
My name is Ahmad and I have a Compute problem
English
DeepSeek V4 Flash is now running on 4x DGX Spark / GB10 cluster
Had to patch several things in vLLM to get it up w/ PyTorch fallbacks
Targeted kernel optimization is next up
P.S. Codex Cli w/ GPT-5.5 XHIGH handled the whole thing on its own, now we optimize those GB10 kernels

Ahmad@TheAhmadOsman
Getting DeepSeek V4 Flash up and running on the 4x DGX Sparks right now
English