Endmare
23 posts



Excited to share our most powerful new Claude Code feature: dynamic workflows! Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.


amazing results (specifically for pi.dev) :D




Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
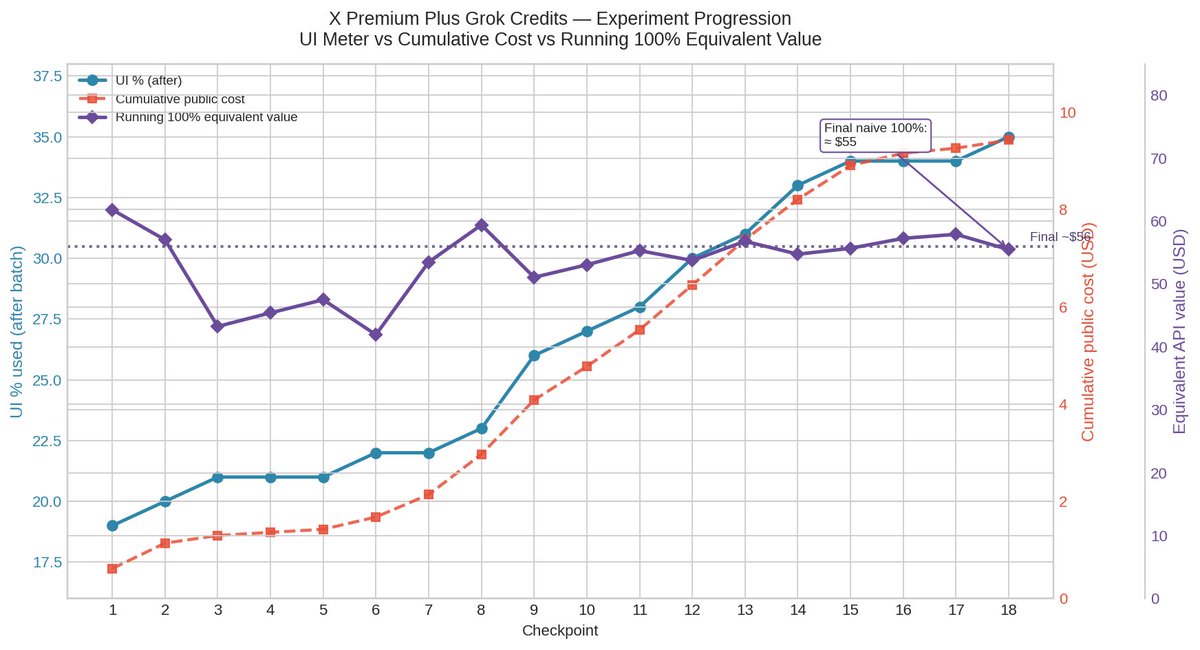
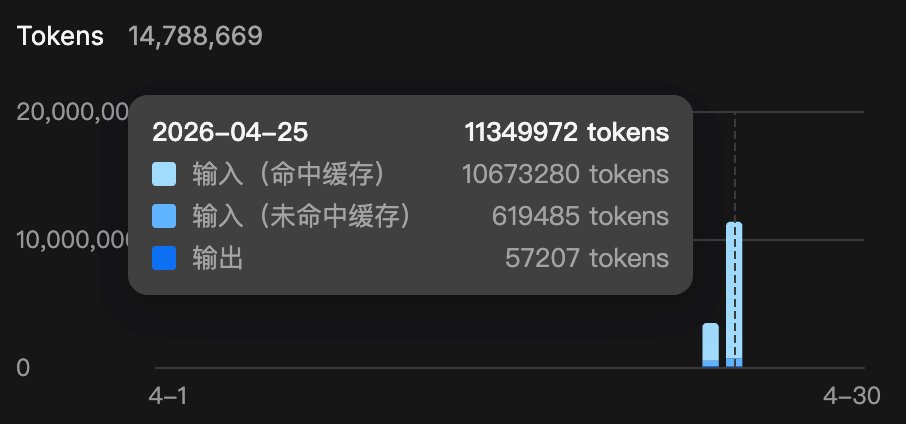
Curious what X Premium+ Grok credits are really worth? 18 Pi subagent batches on grok-build-0.1 + real token logs, regressed vs in-app % using official xAI API pricing. Result: 100% ≈ $55–56. Limitation: Integer UI with lag + non-public internal accounting.


Thank you so much for all the feedback on the Grok Build Beta. Some of you reported hitting limits quickly. Our team found areas to improve caching, so we've reset Grok Build usage limits for all accounts. Please keep sharing feedback - the team is here to help.