Nessie
323 posts


Nessie
@AILearningPaths
what if the sustainable AI future is possible? // gamedev






An exclusive conversation with OpenAI’s chief scientist Jakub Pachocki about his firm's new grand challenge and the future of AI. trib.al/2Lr8Kfh
man shit is getting dystopian really fucking quickly doordash is now paying people to film themselves doing chores then using that to train AI robots that will replace them - guess what? they're not the only ones: - niantic (pokemonGO creators) has trained AI delivery robots with 30 billion photos taken by 500M+ players - Uber launched 'digital tasks' last year where drivers complete tasks to train AI in exchange for a few dollars i don't think people realise they're doing something that will eventually get them fired "heres $5 in exchange for your job"



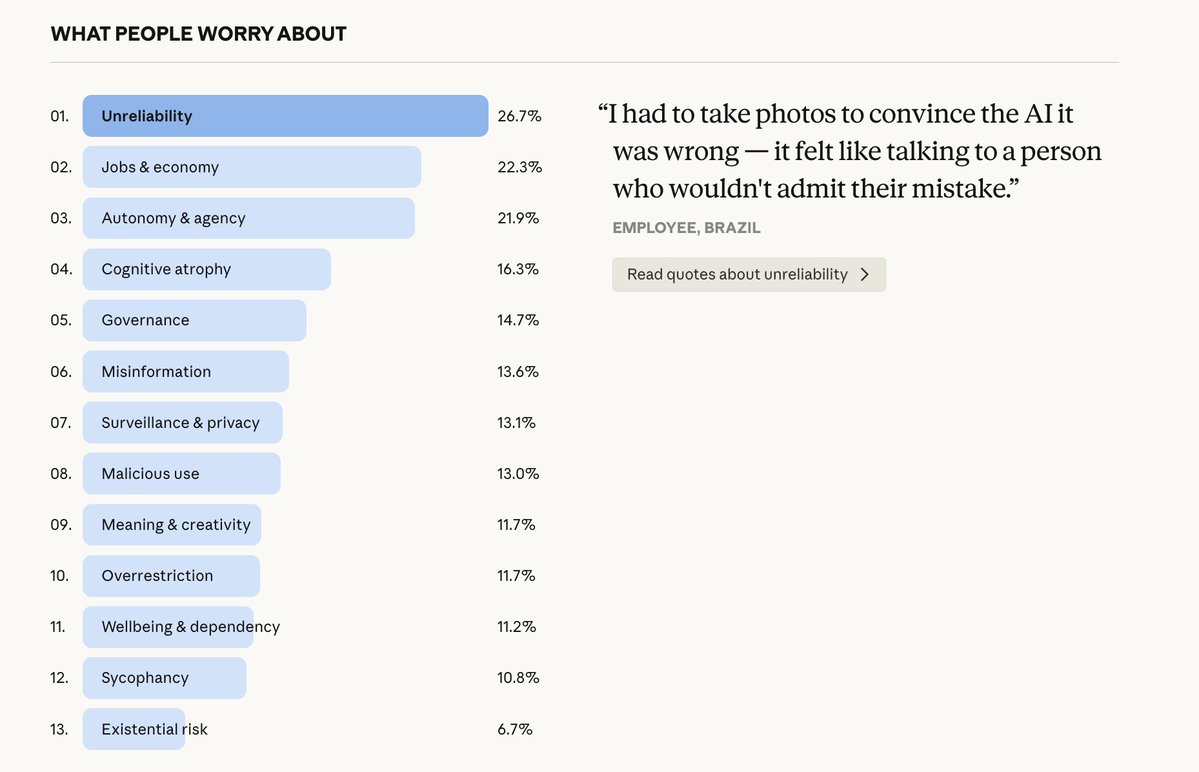
We invited Claude users to share how they use AI, what they dream it could make possible, and what they fear it might do. Nearly 81,000 people responded in one week—the largest qualitative study of its kind. Read more: anthropic.com/features/81k-i…



Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…