
@tunguz Use all thinking patterns that created aha moments in great people who solved impossible problems.
English
asfaan murthyulas
279 posts
@AMurthyulas
Ask stupid question-Think impossible-Do step by step.






















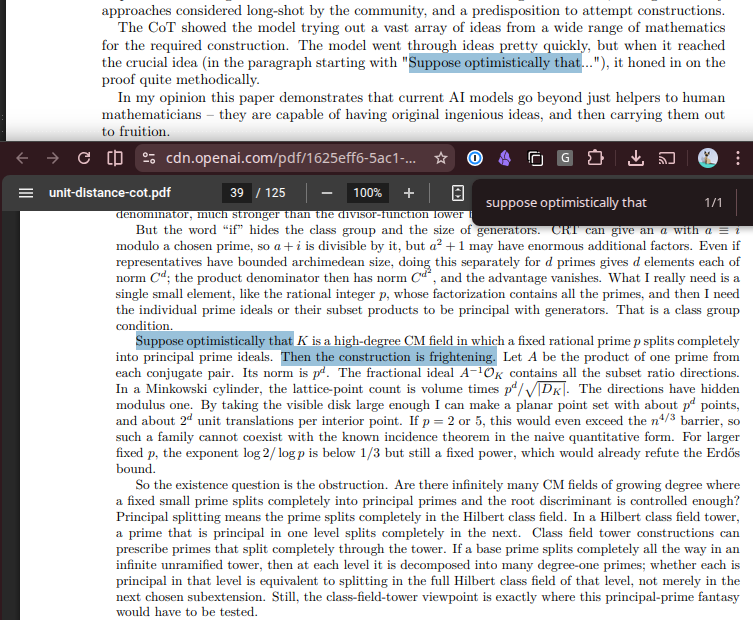
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946. For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids. An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better. This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.



