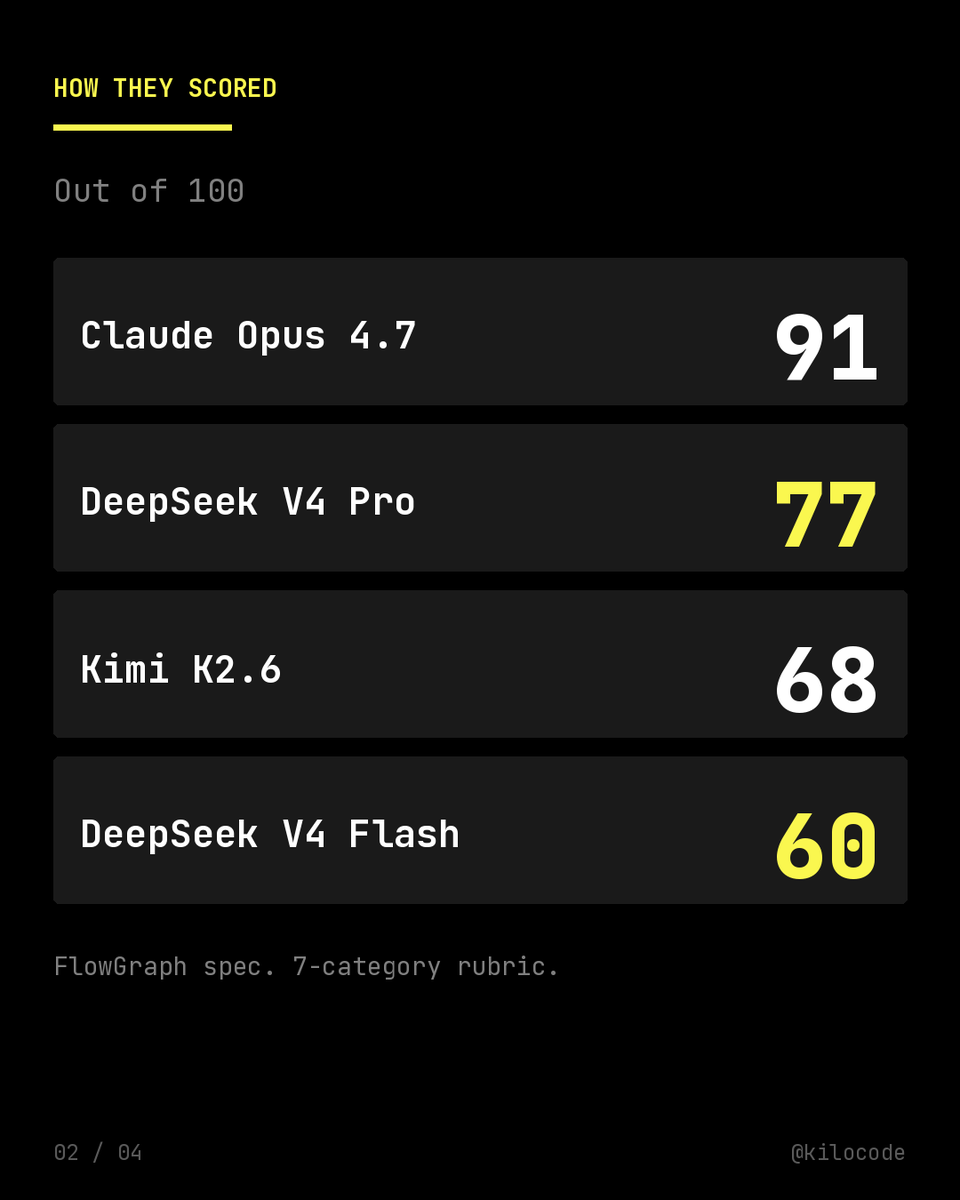
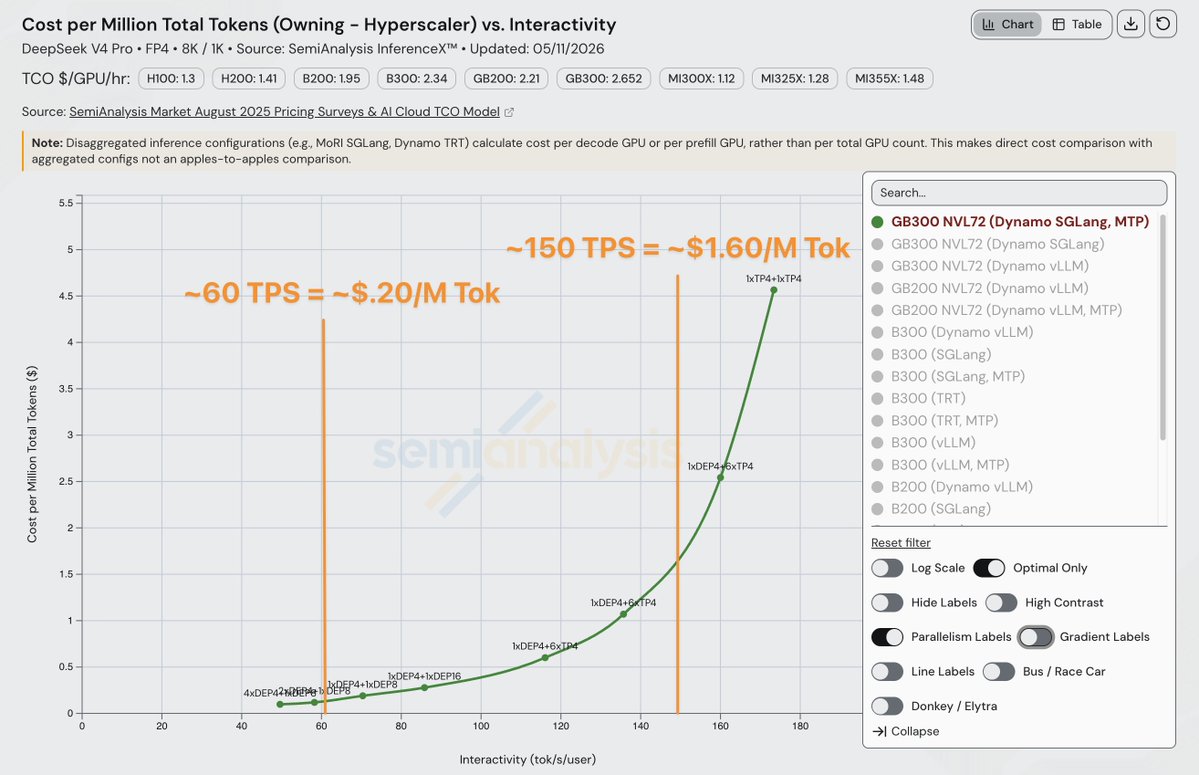
Sabitlenmiş Tweet

The median price gap between neoclouds and model developers this week sits at 64.9%. Inference platforms come in at 52.6% cheaper. Open-weight models trade at 80.9% below proprietary equivalents.
Channel choice is now a first-order decision. Picking the right place to buy a model often matters more than picking the model itself.
a7om.com
#ATOMInference
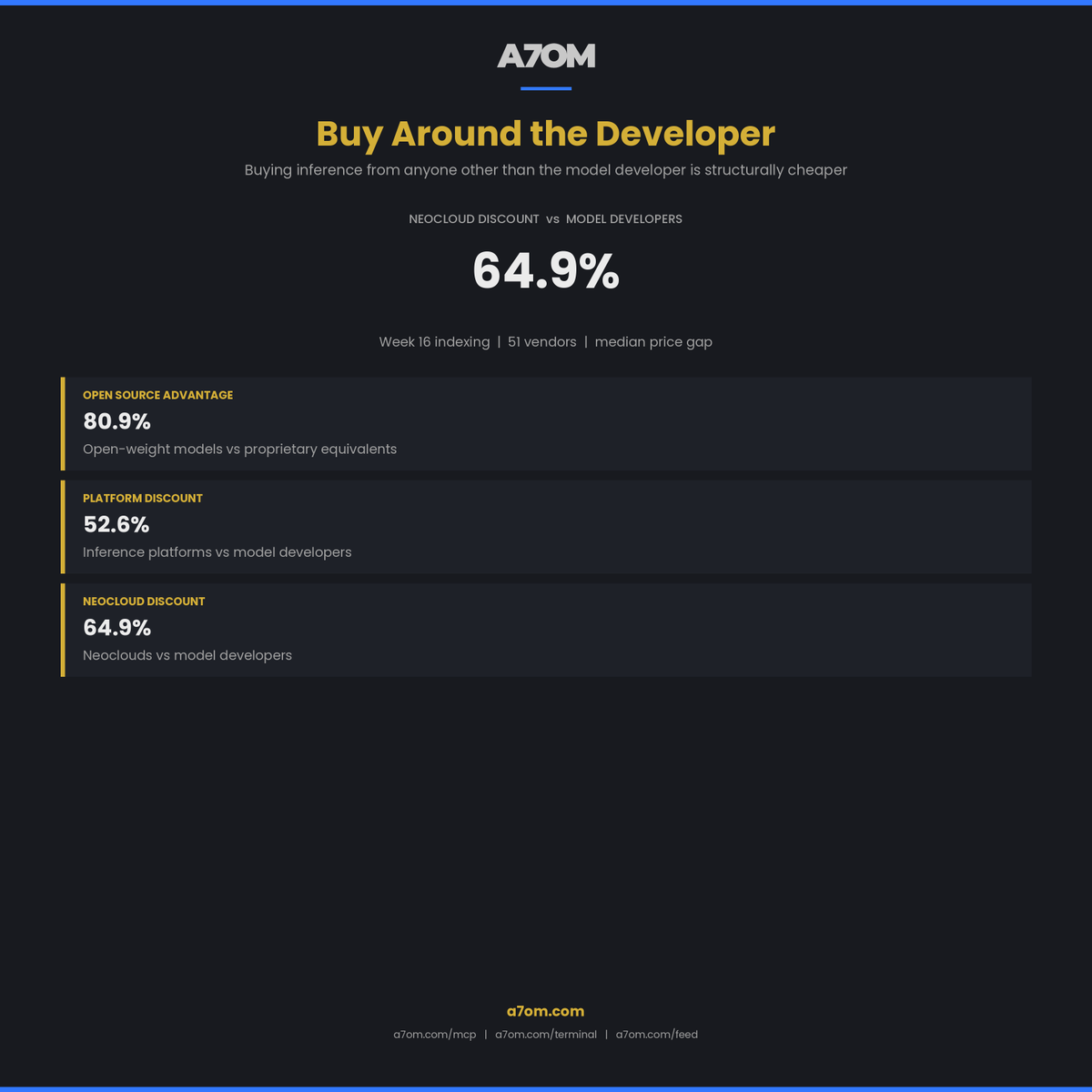
English