
English
Adam Zmenak
306 posts

@AdamZmenak
Technologist and Neurotic audiophile | ex @coinbase Custody and cryoto security



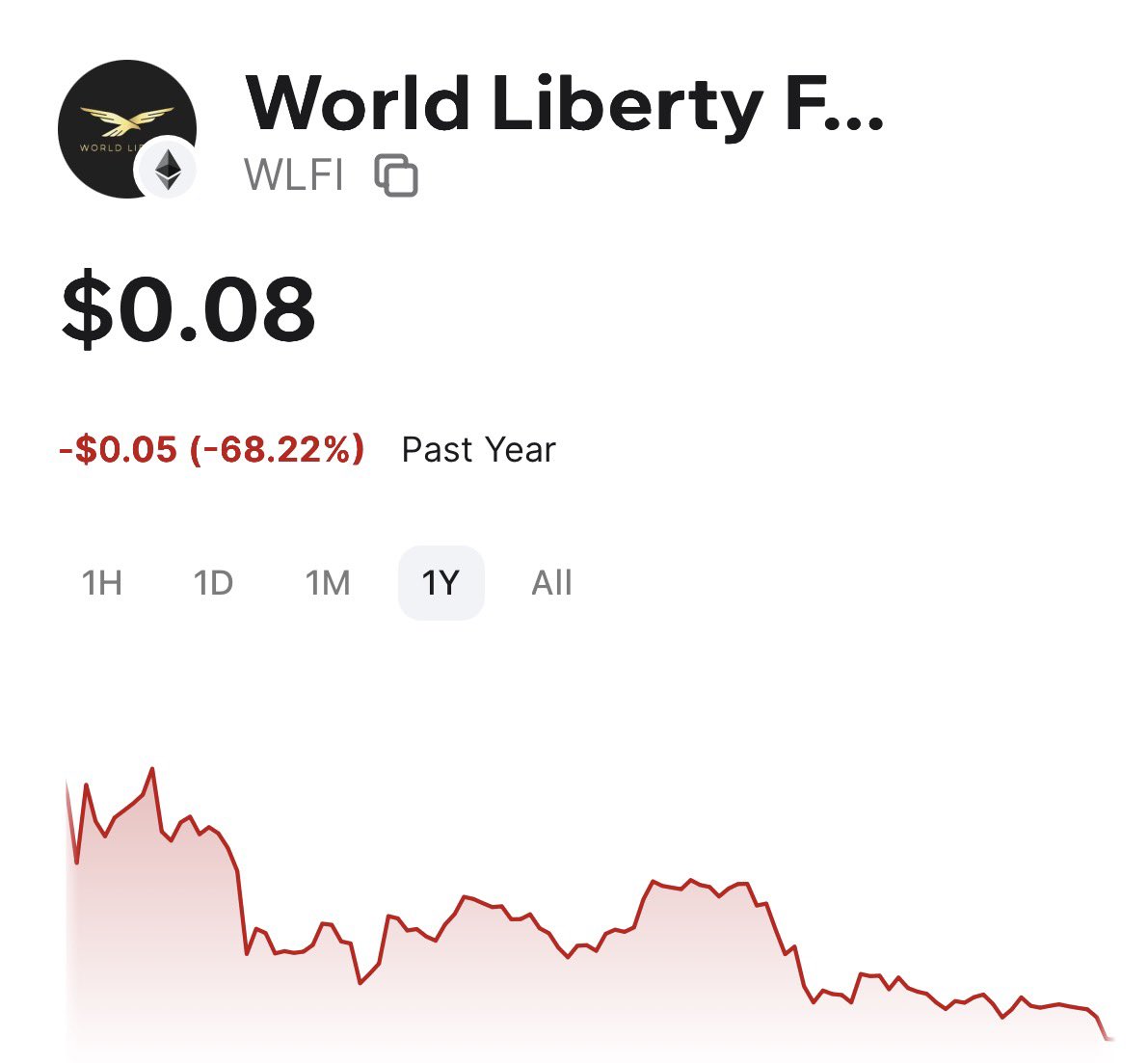
The last administration drove away the digital asset industry. It’s time to welcome them home with clear rules of the road. Pass the Clarity Act.







Someone stole $630,000 worth of Blueprint creatine in an elaborate heist. The driver used a false ID to pick up the units from our factory, then turned off the tracker and stopped responding to calls. The stolen creatine monohydrate was precision-dosed and third-party tested for purity and heavy metals. 15,918 units of pure grade A powder. If anyone has information, lmk. Even if we don't recover the creatine, I'd at least like to know this person's health stats. Here’s a rendering of what we suspect the perp might look like.


📈 In this analysis of Qwen3.5 and tool calling, the researcher found for programming productivity, use GGUF quantization in your Apple silicon. For just speed, use MLX quantization. Great review!





everybody is really doing everything






