
0xAqz🤡 🐦⬛🔑❤️ Memecoin
946 posts

0xAqz🤡 🐦⬛🔑❤️ Memecoin
@Adycjaa
Iove memes and trading meme coins. Keep talking about the right things publicly until they become second nature to me. 热爱meme,热爱交易meme coin。坚持把正确的事情反复公开讲述
Katılım Temmuz 2018
1.1K Takip Edilen522 Takipçiler


0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

十年,从30股到14,000股。
164次交易,不是运气,而是信念的累积。
《Brick by Brick》记录一个普通投资者如何在特斯拉的起伏中,一块砖一块砖搭建自己的认知与长期主义。
当市场质疑你时,你还相信什么?
这本书,讲的就是这个问题。
免费下载《Brick by Brick》(简体中文版):
#aOeXVGHQCv" target="_blank" rel="nofollow noopener">limewire.com/d/r9vpi#aOeXVG…
英文版可在 Amazon 购买:
tinyurl.com/teslayoda
中文

0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

这篇文章建议所有用Claude Code的人都读一遍,把.claude文件夹讲得非常透彻。
大多数人只知道CLAUDE.md,但其实.claude文件夹里藏了一整套配置体系:
1、CLAUDE.md:最核心的文件,写什么Claude就照做,建议控制在200行以内
2、rules/文件夹:当CLAUDE.md太臃肿时,按关注点拆分成多个规则文件,还支持按路径作用域加载
3、commands/文件夹:自定义斜杠命令,能嵌入shell命令输出,团队共享
4、skills/文件夹:和命令不同,技能是Claude自动触发的,不用手动输入
5、agents/文件夹:给子代理定义独立角色和权限,处理复杂任务
6、settings.json:权限控制,哪些工具能用、哪些文件能读
还有个容易忽略的点:其实有两个.claude目录,项目级的提交到git团队共享,全局~/.claude/放个人偏好。

Akshay 🚀@akshay_pachaar
中文

受 WorldMonitor 启发,我做了一个 Polymarket 世界看板: PolyWorld
有了 PolyWorld,你可以实时看到世界上重大事件对应的预测市场,以及“内幕人士”对事件真实概率的判断,掌握时代脉搏。
网站: polyworld.bet
开源: github.com/AmazingAng/pol…
@Polymarket @PolyWorld_bet
中文
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

发布一个新的 Skill:baoyu-youtube-transcript
输入 YouTube URL,直接抓取视频字幕,生成带章节、发言人和封面图的文档,不需要任何 API Key。
【怎么用】
选择这个 Skill,把 YouTube 链接丢进去就行。支持完整链接、短链接、嵌入链接、Shorts 链接,甚至直接输入视频 ID 都可以。
默认输出带时间戳的 Markdown 格式,也可以导出 SRT 字幕文件。支持多语言,可以指定优先语言,也可以翻译成其他语言。
第一次抓取后会自动缓存原始数据,之后换格式、换参数都不用重新请求,秒出结果。
【工作原理】
底层调用的是 YouTube 的 InnerTube API,这是 YouTube 内部用来获取字幕数据的接口,公开可用但没有官方文档。好处是不需要 Google API Key,不需要 OAuth 认证,脚本直接发请求就能拿到字幕数据。
拿到原始字幕后,脚本会做一次智能断句处理:按句末标点(句号、问号、感叹号等)切分,跨字幕片段合并成完整句子,时间戳按字符长度等比分配,对中日韩文字做了专门适配。这样输出的文本是自然的句子,不是 YouTube 那种碎片化的逐行字幕。
【章节分割】
如果视频描述里有章节时间戳(比如 "0:00 Introduction"),脚本会自动解析,按章节把字幕分段,生成带目录的 Markdown。没有章节信息的视频,就按段落分组输出。
【说话人识别】
这是最有意思的部分。YouTube 字幕本身不带说话人信息,所以识别说话人需要 AI 后处理。
流程是这样的:先用 --speakers 参数抓取原始字幕,脚本会把视频元数据(标题、频道名、简介)和 SRT 格式的原始字幕一起输出到一个 Markdown 文件里。然后启动一个 AI 子代理(用 Claude Sonnet,够用且省成本),按预设的 Prompt 模板处理这个文件。
AI 识别说话人的逻辑分三层优先级:首先从元数据推断,视频标题通常包含嘉宾名字,频道名就是主持人;其次从对话内容判断,比如自我介绍、互相称呼;都不行就用通用标签(Speaker 1、Host 之类),保持全文一致。如果后面对话中才出现名字,会回溯更新前面所有标签。
处理完的输出是带说话人标签的分段对话,长独白会被切成 2-4 句一段,每段末尾带时间范围。
【缓存机制】
第一次运行会缓存四样东西:视频元数据(meta.json)、原始字幕片段(transcript-raw.json)、断句后的字幕(transcript-sentences.json)、视频封面图(cover.jpg)。之后不管切换格式还是重新生成,都直接用缓存,不再请求网络。加 --refresh 参数可以强制刷新。
安装命令:
$ npx skills add jimliu/baoyu-skills --skill baoyu-youtube-transcript
项目地址:github.com/jimliu/baoyu-s…
宝玉@dotey
New Agent skill: baoyu-youtube-transcript 🎬 Extract YouTube transcripts directly — no API key needed. ✦ Multi-language support ✦ Chapter segmentation ✦ AI speaker identification ✦ SRT & Markdown output ✦ Smart caching for instant re-formatting Just select the skill and paste a YouTube URL and go. Install: $ npx skills add github.com/jimliu/baoyu-s… --skill baoyu-youtube-transcript
中文
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

We’re launching a brand new, full-stack vibe coding experience in @GoogleAIStudio, made possible by integrations with the @Antigravity coding agent and @Firebase backends.
This unlocks:
— Full-stack multiplayer experiences: Create complex, multiplayer apps with fully-featured UIs and backends directly within AI Studio
— Connection to real-world services: Build applications that connect to live data sources, databases, or payment processors and the Antigravity agent will securely store your API credentials for you
— A smarter agent that works even when you don't: By maintaining a deeper understanding of your project structure and chat history, the agent can execute multi-step code edits from simpler prompts. It also remembers where you left off and completes your tasks while you’re away, so you can seamlessly resume your builds from anywhere
— Configuration of database connections and authentication flows: Add Firebase integration to provision Cloud Firestore for databases and Firebase authentication for secure sign-in
This demo displays what can be built in the new vibe coding experience in AI Studio. Geoseeker is a full-stack application that manages real-time multiplayer states, compass-based logic, and an external API integration with @GoogleMaps 🕹️
English
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi


0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

最近专心搞 AI 基建,重点之一就是浏览器自动化,这也是小🦞能让很多小白高呼惊艳的大杀器。
调研了一圈之后,最后留下来的两个种子选手分别是 Agent-Browser 和 PinchTab 。
它们都说自己是给 Agent 用的新一代自动化工具,但用起来完全是两个物种。花了几天时间踩坑后,把我的一点小小的踩坑心得梳理一下,免得你们重蹈覆辙。
先说 Agent-Browser,这货真是个宝贝啊!不信你翻开 OpenClaw 看看也内置了它。
Vercel 这帮人做的 Agent-Browser,说白了就是给 Playwright 套了个"AI友好"的壳。最爽的是什么?你可以直接在和 AI 对话的时候跟它说"点击登录按钮",他就会自己去帮你探索到底应该点哪个按钮。
更妙的是,当你用 AI Coding(例如 Claude Code)帮你探索完自动化流程后,你可以让它再丝滑的转成 Playwright 生产代码。
这就像是先让 AI 先帮你画草图,等你满意了再让它你再把它变成工程图纸。整个过程行云流水,一个 Token 也不浪费。
再说 PinchTab,这玩意就是多自动化浏览器实例管理狂魔,还是能保存登录状态的那种!
PinchTab 是个 Go 写的独立服务,核心是一个 12MB 的二进制文件。执行之后会启动一个 HTTP 服务,然后 AI 就可以通过 curl 来通过调用这个服务去操控浏览器
它的设计哲学是:"我不管你用什么语言,反正我就是个 HTTP 服务,你爱怎么调就怎么调。"
最大的卖点是多实例自动编排。如果你需要同时跑 10 个浏览器实例(比如管理 10 个不同 X 账户),用 Playwright 你得自己管端口、进程、配置文件路径……但 PinchTab 一行命令直接搞定:自动分配端口 9868、9869、9870,配置文件管理、健康检查全都内置。
这货还标榜自己能通过模拟人类的鼠标操作和点击操作习惯,进一步躲避网站的反爬虫检测。
我怎么越看这货越像是个搞灰产的神器???
如果你的工作流和我类似是这样的:
- "我就写个 TypeScript 脚本,单实例够用"
- "我主要用 Claude Code 帮我写代码"
- "我想要开发体验好,能快速迭代"
那就无脑直接上 Agent-Browser 吧,背靠 Playwright 和 Electron 两个爸爸,它就是为你而生的。
如果你是这样的:
- "我要同时管 10 个账户,每个都要独立浏览器"
- "我用 Python/Go,不想碰 Node.js"
- "我要部署成微服务,扔到 Docker 里"
那就从一开始就用 PinchTab 吧,这种轮子可不是 Vibe Coding 能随手搓出来的。
github.com/vercel-labs/ag…
中文
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

Vibe coding 最强模型, 一定是 Claude 结合 Codex
是的, 一定需要两个结合起来, 最后产生的代码质量更高.
比如说这篇论文:
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity" (arXiv:2602.03794) 提到
同源的模型,跟容易遇到瓶颈.
原因也很简单. opus 4.6, 训练集和训练参数都是一样的, 你分几个agent来角色扮演, 也是会容易出现信息茧房. 这时候引入Codex, 就不一样了.
实际上我现在的流程是这样的.
Plan阶段
Opus 4.6 做计划, Codex gpt 5.3 Xhigh 挑刺 (最多三个来回)
实施阶段
Sonnet 4.6写代码, 另外一个Sonnet 4.6初步审核代码. Codex 5.3 high 最终审核代码
(最多三个来回)
这里面评审完了打回去改, 多轮评审. 最后达到一个最佳状态.
缺点:
1. 时间长
这是必然的. 多轮迭代下来, 1个小时很正常.
2. 耗token
主要是Claude 贵. Codex的很便宜, 忽略不计了.
还好我有个 0.3倍 和 0.15 倍费率的Claude 订阅. (具体看2楼)
(0.15倍费率的 Sonnet 4.6我现在当主力) Codex自己去咸鱼上找一个, 十几二十元一个月足够用了.
你可以看到 Codex 给 Claude review出很多bug出来.最终结果是 准确性很高.
另外, Claude Code 调用 Codex 有两种方法, MCP或者 Skills. 这里建议用Skill, 有一些性能上的考虑, 这里不细说了. Github 上搜 "skill-codex" 就行了.
当然, 你要不嫌麻烦, 开几个Claude 和 Codex命令行窗口, 来回复制黏贴 双方的吵架结论 也可以. 我建议是搞成自动化的:
以下是我的Claude[.]md 文件, 你们可以参考一下. 我打磨了两周了, 现在已经稳定了, 很好用.
有的时候Claude 会忘记上下文, 这时候prompt里可以让他重新加载一下 Claude .md, 或者
明确告诉它 "现在修复xx问题, 然后从第0阶段开始"
----以下是 Claude. md 文件, 你可以直接复制过去----
# xx项目 — 强制性规则
## 模型层级与角色归属
* **主管/规划者 (The Lead/Planner):** 主 CLI 会话。负责把控策略和 `claude.md` 规则。你不编写代码;你负责委派任务。例外情况:微小的修改(如拼写错误、配置值、日志信息)可以由主管直接进行而无需委派。**仅当**审查者标记出架构缺陷、交易策略不兼容或达到重试上限时才进行干预。
* **蓝图实现者 (`blueprint-implementer`,Sonnet 4.6):** 子代理。严格按照主管的蓝图编写新功能和测试。**不**负责修复测试失败问题。
* **调试者 (`debugger`,Sonnet 4.6):** 子代理。负责修复测试套件或审查者标记的局部错误、语法错误、失败的测试和内存泄漏。
* **代码审查者 (`claude-code-reviewer`,Sonnet 4.6):** 子代理。执行快速通道的内部验证(第 1 阶段)。
---
## 实施前:Actor-Critic 架构辩论(第 0 阶段)
**触发条件:** 新功能、架构变更、复杂的业务逻辑或复杂的错误修复时必须进行。
**绕过条件:** 琐碎任务可跳过第 0 阶段。“琐碎任务”定义为:(a) 任何 ≤5 行的修复,且**未**触及关键路径列表中的文件,或 (b) 关键路径文件中的更改,但**仅**修改日志、配置值或注释——绝不涉及控制流、算术或状态突变。如果更改处于模棱两可的边界,则**不属于**琐碎任务——请运行第 0 阶段。符合绕过条件的任务示例:拼写错误修复、简单的 UI 微调、一次性诊断脚本(如拉取 VPS 日志)或简单的配置更新。
> **阻塞网关 (BLOCKING GATE):** 第 0 阶段是一个严格的顺序网关。主管必须等待 Codex 返回且计划被锁定后,才能开始**任何**实施工作。切勿在后台运行 Codex 审计并同时并行实施——这样做违背了实施前审查的初衷,且属于违反协议的行为。
**1. 草案 (主管):** 主管编写一份严格的、循序渐进的架构蓝图,详细说明业务逻辑、组件、数据结构、状态变化和执行流程。
**2. 质询 (Codex 技能桥接):**
通过 `Skill("codex")` 在**前台**(非后台)调用 `codex` 技能。将其配置为使用 `gpt-5.3-codex` 并设置 `model_reasoning_effort` 为 `xhigh`。传递以下有效载荷:
* **目标范围 (Target Scope):** 提议的架构蓝图。
* **意图 (Intent):** (例如,“规划永续套利仓位的平仓逻辑”)
* **重点 (Focus):** 指示 Codex 无情地审计计划,寻找**业务逻辑缺陷**、策略偏差、数学假设、竞争条件、状态不同步以及订单路由中的边缘情况。
* **格式 (Format):** 指示 Codex 返回可操作的批评意见,格式严格遵循:`[组件] - [严重程度] - [架构/逻辑缺陷] - [建议的缓解措施]`。
**3. 评估与辩论循环(迭代):**
主管必须结合项目不变量及其更广泛的背景,批判性地评估 Codex 的批评。你**绝不能**盲目接受所有发现,也不要对客观事实进行辩论。你必须对 Codex 的反馈应用这种严格的二分法:
* **路径 A:客观错误(自动修复并遵守):** 如果 Codex 标记了客观的数学错误、API 约束违规、单位转换错误、数据损坏风险或明显的竞争条件,**不要辩论**。立即接受该发现,将修复整合到蓝图中,并进入下一次迭代。
* **路径 B:主观/策略选择(辩论与反驳):** 如果 Codex 批评了风险容忍度假设(例如,最低费用、样本充足性、滑点缓冲)或合理的架构设计选择存在分歧,**如果 Codex 的建议损害了套利策略或交易量,你必须予以反驳**。提出合乎逻辑的反驳意见,为原始架构辩护或提出折中方案。
**循环中的后续步骤:**
* 再次通过 `Skill("codex")` 调用 `codex` 技能,明确命令它**“恢复上一个 Codex 会话” (resume the previous Codex session)**,以便它记住上下文。传递修改后的蓝图(对于路径 A)或主管的反驳意见(对于路径 B)。
* **退出条件(何时打破循环):** 继续“草案 -> 批评 -> 评估/辩论”循环,直到满足以下**任一**条件:
1. **达成共识(锁定计划):** Codex 报告零客观错误,并且要么同意你的策略性辩护,要么你们达成了一个折中的蓝图。(进入第 1 阶段)。
2. **迭代上限:** 你完成了 **3 个完整的辩论周期**且无法达成一致。**不要**开始编写代码;停止该过程并移交给 用户。(状态:已升级 🛑)
3. **主观/策略僵局:** 模型在无法仅凭逻辑解决的策略假设上存在根本分歧。停止该过程并移交给 用户。(状态:已升级 🛑)
> **移交检查点:** 只有在达到退出条件 1(锁定计划)后,主管才能将蓝图移交给 `blueprint-implementer`。在计划锁定之前,请勿委派实施任务。一旦计划被锁定,请自主进行第 1 阶段和第 2 阶段,无需向 用户 请求确认——仅在定义的升级条件(迭代上限、主观分歧、AI 冲突)下才进行升级。
---
## 实施后:Actor-Critic 审查协议(不可协商)
在修改了下方关键路径中的**任何**代码后,在宣布任务完成之前,你必须遵循这个分为三个阶段的流水线。
### 第 1 阶段:内部验证(Actor 团队:规划者 + 子代理)
在调用外部工具之前,你必须确保代码处于“稳定的候选状态”。
1. **执行移交:** 主管定义计划。`blueprint-implementer` 编写代码。
2. **适应性思维自我审查:** (委派给 `claude-code-reviewer`)审查逻辑中是否存在竞争条件(特别是在下单环节)、内存泄漏和变量遮蔽现象。
3. **冲突优先级规则:** 架构审查优先于测试结果。如果测试因架构更改而失败,请评估是否应更新测试以匹配新架构——**切勿**仅仅为了让旧测试通过而撤销架构决策。
4. **测试自动化:** `blueprint-implementer` 编写或更新相关测试。如果测试失败,委派给 `debugger` 进行修复。在进入第 2 阶段之前,你**必须**运行测试并达到 `PASS` 状态(**所有**测试均为绿色,零失败)。如果发现预先存在的测试失败,请对其进行审查:如果测试是合理的并且反映了真实预期,请更新代码或测试以使其通过;不要忽略它们。
5. **稳定性网关:** 仅当代码功能正常、通过本地 lint 检查并满足当前任务要求时,才继续交给 Codex。
### 第 2 阶段:“最终 Boss”审计(Critic:Codex 5.3 高级推理)
仅在第 1 阶段成功且测试全部通过后才触发此阶段。
**1. Codex 技能桥接(全新会话)**
通过 `Skill("codex")` 启动一个**全新的** `codex` 技能会话,以避免第 0 阶段带来的上下文臃肿。将其配置为使用 `gpt-5.3-codex` 并设置 `high` 推理工作量 (reasoning effort),传递以下有效载荷:
* **标准 (The Standard):** 提供在第 0 阶段结束时生成的最终版“锁定蓝图”。
* **目标范围 (Target Scope):** (例如,`variational_client/browser_client.py` @ 第 45-120 行)
* **变更 (Diff):** **仅**提供 `git diff` 或更改的具体代码行。
* **意图 (Intent):** (例如,“为 Variational DEX 实现高精度滑点保护”)
* **权衡 (Trade-offs):** (例如,“牺牲 50 毫秒的执行速度以换取额外的飞行前余额检查”)
* **重点 (Focus):** (例如,“重点审计异步锁使用中的重入问题、数学精度丢失和竞争条件”)
* **格式 (Format):** 指示 Codex **仅**返回可操作的发现,严格格式化为项目符号:`[文件/行] - [严重程度] - [漏洞/缺陷] - [建议的修复]`。
**2. 执行与修复循环(迭代 2 与 3)**
* **自动修复:** 委派给 `debugger` 修复 Codex 标记的客观错误或安全漏洞。
* **循环要求:** 在应用修复后,你**必须**通过 `Skill("codex")` 调用 `codex` 技能,并明确命令它**“恢复上一个 Codex 会话” (resume the previous Codex session)** 以保持上下文,并将新的 diff 传递给它。你**不能**自我证明你自己的修复。
* **退出条件(何时打破循环):** 你必须继续“修复 -> 重新审计”循环,直到满足以下**任一**条件:
1. **完全通过 (Clean Pass):** Codex 报告零客观功能缺陷。(状态:成功 ✅)
2. **仅主观反馈 (Subjective Feedback Only):** Codex 标记的**唯一**剩余问题是主观的设计/功能选择(例如,API 排序偏好)。**不要**尝试修复主观选择;打破循环并移交给 用户。(状态:已升级 🛑)
3. **迭代上限 (Iteration Cap):** 你完成了 **3 个完整周期**,但仍然存在客观错误。**不要**交付代码;停止该过程并移交给 用户。(状态:已升级 🛑)
4. **AI 冲突 (Conflicting AI):** Codex 在不同的迭代中提供了相互矛盾的指令。(状态:已升级 🛑)
### 第 3 阶段:强制移交摘要 + 自动提交
每当循环停止时(成功、达到上限或升级),你必须提供此状态报告:
* **最终状态:** [成功 ✅ / 已升级 🛑]
* **Codex 发现:** (用简短的项目符号列出被标记的关键漏洞或逻辑缺陷)
* **采取的行动:** (总结代码在审查循环期间是如何演变的)
* **剩余事项:** (任何需要 用户 最终批准的主观设计选择或边缘情况)
**自动提交规则(仅限成功时):** 当最终状态为“成功 ✅”时,立即创建所有更改文件的 git 提交,无需等待被要求。**仅**暂存当前任务触及的文件(绝不使用 `git add -A`)。提交消息格式:根据情况使用 `fix:` / `feat:` / `refactor:`,并附带一个简洁的正文,总结修复的错误或添加的功能。**始终**在末尾附加 `Co-Authored-By: Claude Sonnet 4.6 @anthropic.com>`。在“已升级 🛑”状态下**切勿**自动提交——请先等待 用户 的批准。
### Codex 不可用时的后备方案
如果在第 0 阶段或第 2 阶段无法调用 Codex,**不要**进行自我证明。立即将蓝图或代码更改的当前状态升级给 用户。(状态:已升级 🛑)
> **技能名称:** Codex 技能被注册为 `codex`(而不是 `skill-codex`)。始终通过 `Skill("codex")` 调用。插件包名为 `skill-codex`,但其内部的技能名为 `codex`。
---
### 关键路径(始终触发审查):
- `variational_client/browser_client.py` — 订单下达、会话身份验证、隐蔽模式
中文
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

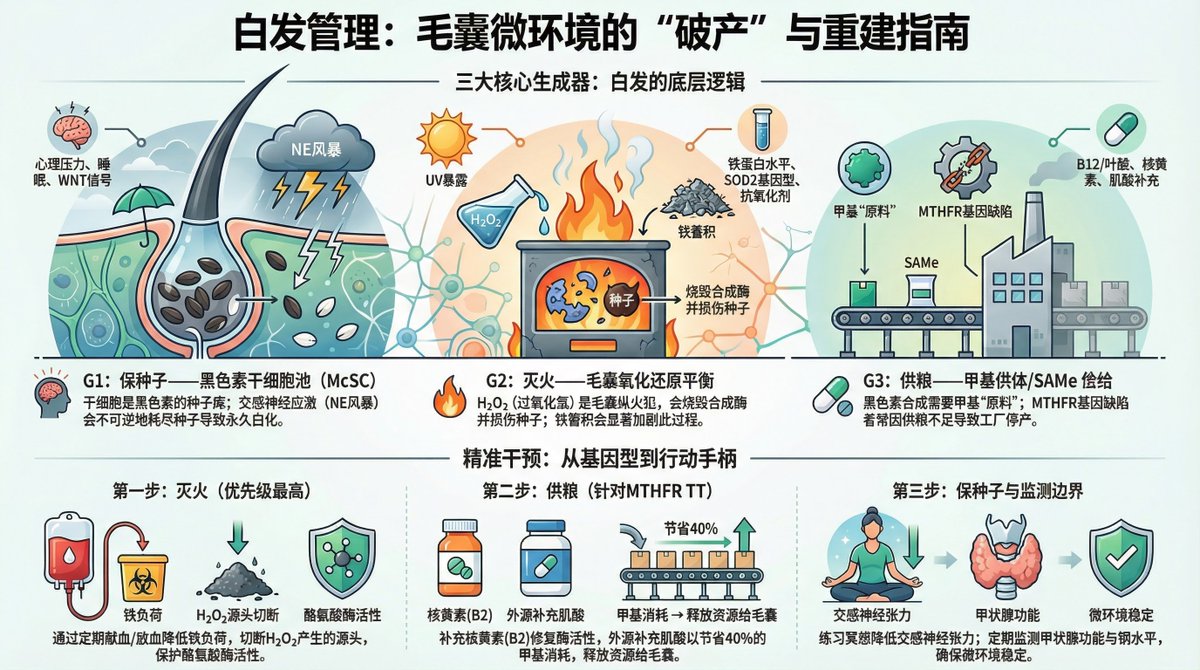
我从十几岁开始长白头发,以为是遗传,没当回事。
创业之后压力上来,白发肉眼可见地加速
直到做了基因检测:MTHFR TT纯合突变。
这不是普通的「少白头」,是身体亮的黄灯——
甲基化低效 + 抗氧化失衡
搞清楚通路后开始靶向干预,现在白头发几乎没有了
核心逻辑:
白发的80%杠杆在两件事——
抗氧化+ 甲基供体
剩下20%是压力管理
如果你也年轻时就开始长白发,先查MTHFR。毛囊还在,种子就还在
中文
0xAqz🤡 🐦⬛🔑❤️ Memecoin retweetledi

牛P了
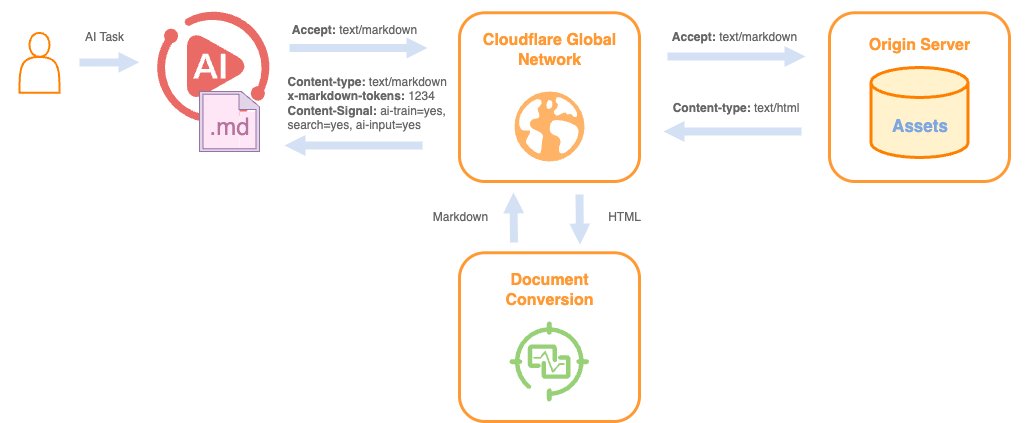
Cloudflare 在其 CDN 网络层上线了一个新功能:
当 AI Agent 或爬虫请求网页时,Cloudflare 可以自动把 HTML 页面转换为 Markdown 格式返回,从而大幅节省 token 消耗,让 AI 更高效地"阅读"网页内容。
一篇博客文章使用HTML 消耗16180 个 token,通过这工具转换后仅消耗 3150 个 token。 (减少约 80%)
原理很简单:
当 AI 请求网页时,加一个请求头:
Accept: text/markdown
Cloudflare 就会:
从源站拿 HTML
在边缘服务器转换成 Markdown
返回 Markdown 版本
中文
最近一个星期,深度使用🦞Openclaw有感而发:
在AI时代,具体的能力变得不重要,重要的是品味(Taste)
“Ultimately, it comes down to taste.”
有时候我想大喊:Gemini,你真的是个天才
中文