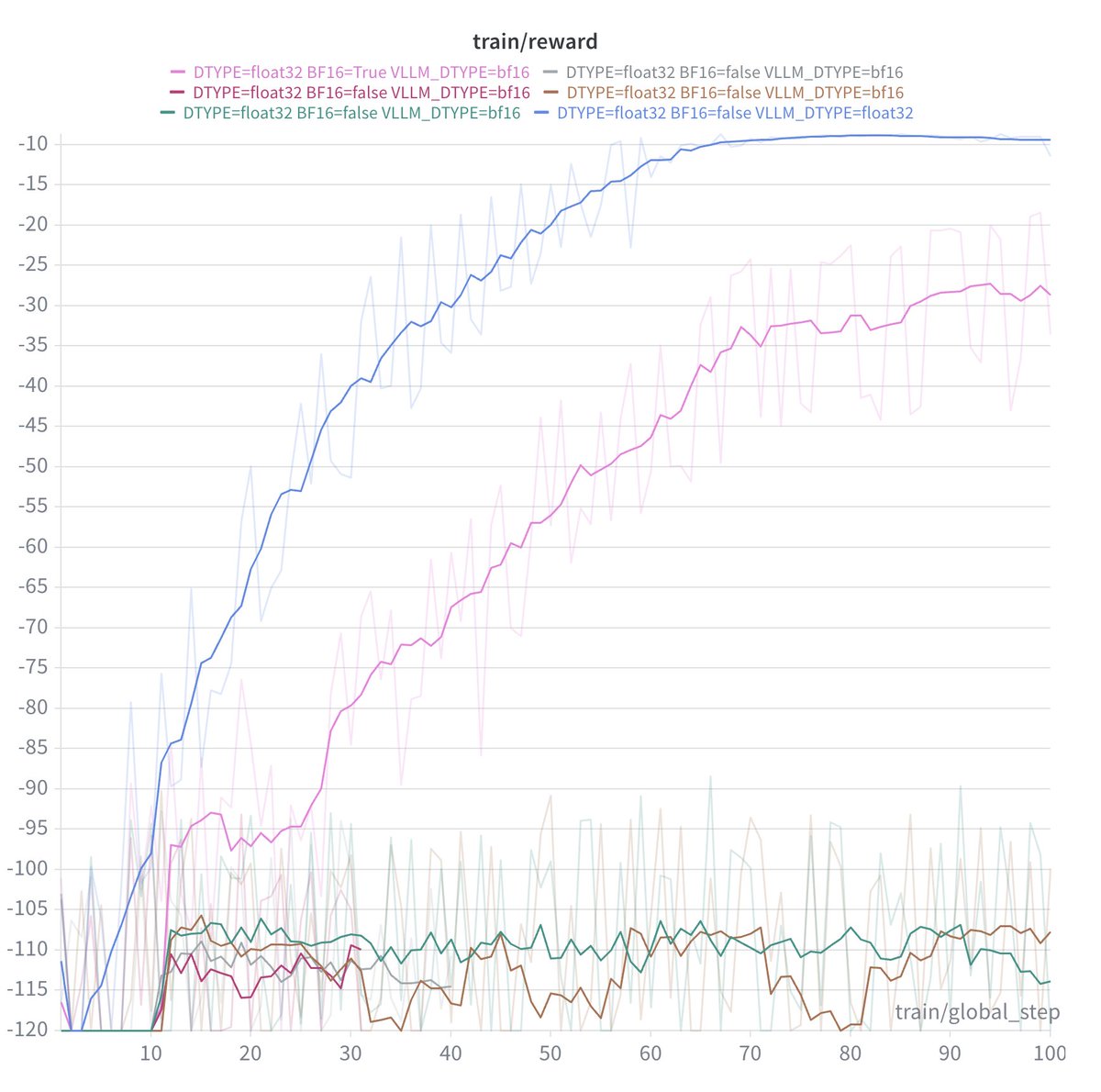
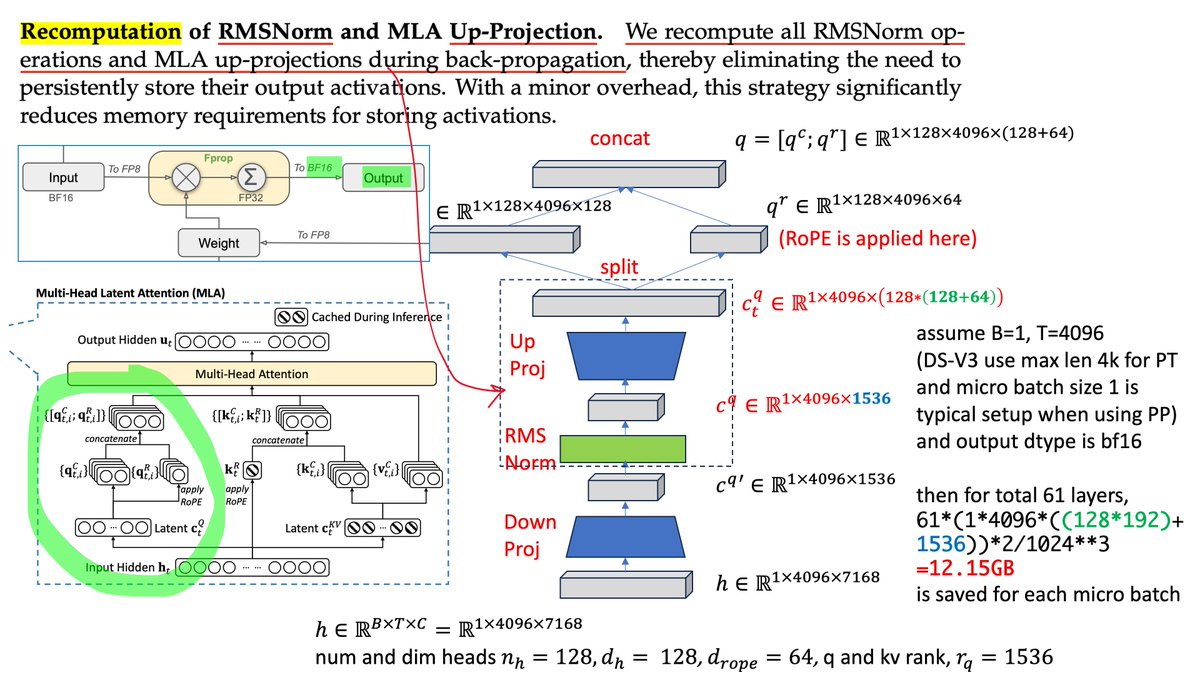
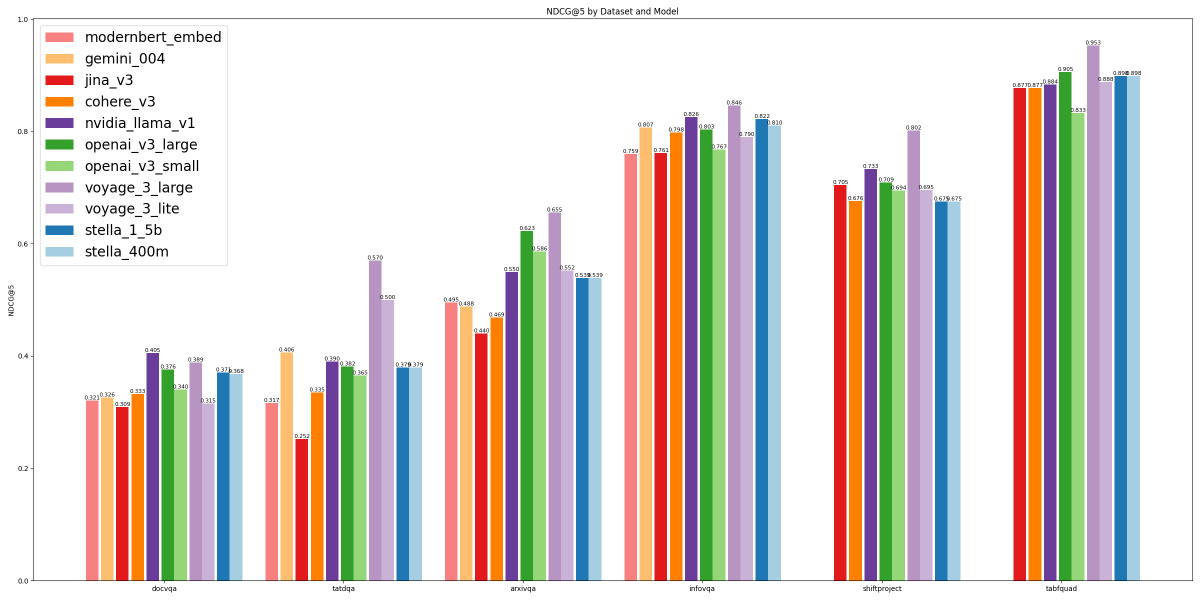
@DirhousssiAmine @hgoel1000 If it works with 1e-5 then is it the case that the total update with the smaller learning rate goes out of the representable range in bf16 whereas when we use 1e-5 the update is still representable? By update I mean the product of the learninf rate and gradient
English