Sabitlenmiş Tweet

Aleph0
2.2K posts

@Aleph0Tech
Get a lifetime of item tracking stickers: just $5/year.








The claim that computation isn't a universal, transcendent concept often reduces to "simulated water isn't wet". But this objection assumes its conclusion: that wetness isn't already a form of computation. The deeper issue: is any conceiving, of any kind, non-computational?





Can people please stop calling arbitrary multidimensional arrays “tensors”?









Took some time (and coffee) to think what would be a sensible test between COGENT3 and LeJEPA. For that, it's important to understand the differences in their approach. LeJEPA is about representation learning: it learns a feature space after seeing many examples, new inputs get mapped to that space. COGENT3 "learns" in a different way. Given two specific symbols (prototypes) agents examine them and argue about what identifies them. The assumption is that agents deliberation on specific cases find distinctions that general learning misses. So I thought: when two symbols are genuinely confusable (e.g., high pixel similarity) which approach wins? LeJEPA says: "I've seen X of each. Now I'm handed Y to determine what it is given the learned embeddings." COGENT3 says: "I'm looking at this objects right now. What makes them different, or not?" In other words: does distributional optimality guarantee discrimination at the boundaries? Two genuinely confusable inputs might land near each other in embedding space precisely because LeJEPA's SIGReg pushes everything toward a smooth Gaussian (what's minimized is average prediction risk across the learned manifold). COGENT3 doesn't care about distributions. I set as task to try determine whether generalization from many examples has inherent limits, or rather, whether LeJEPA's encoding is good enough to handle cases which are within the class of learned examples but at the decision boundary where class similarity is maximal. Code running, we'll see what comes out @randall_balestr Interestingly, the case for COGENT3 in robotics rests on how boundary cases are handled. Take a robot seeking to pick up an object: it doesn't care about average performance across a distribution, but about the specific object "in the moment" and that may sit exactly at the boundary of what can or cannot be "picked up". If that makes sense. @Scobleizer Maybe @arian_ghashghai will find it useful.











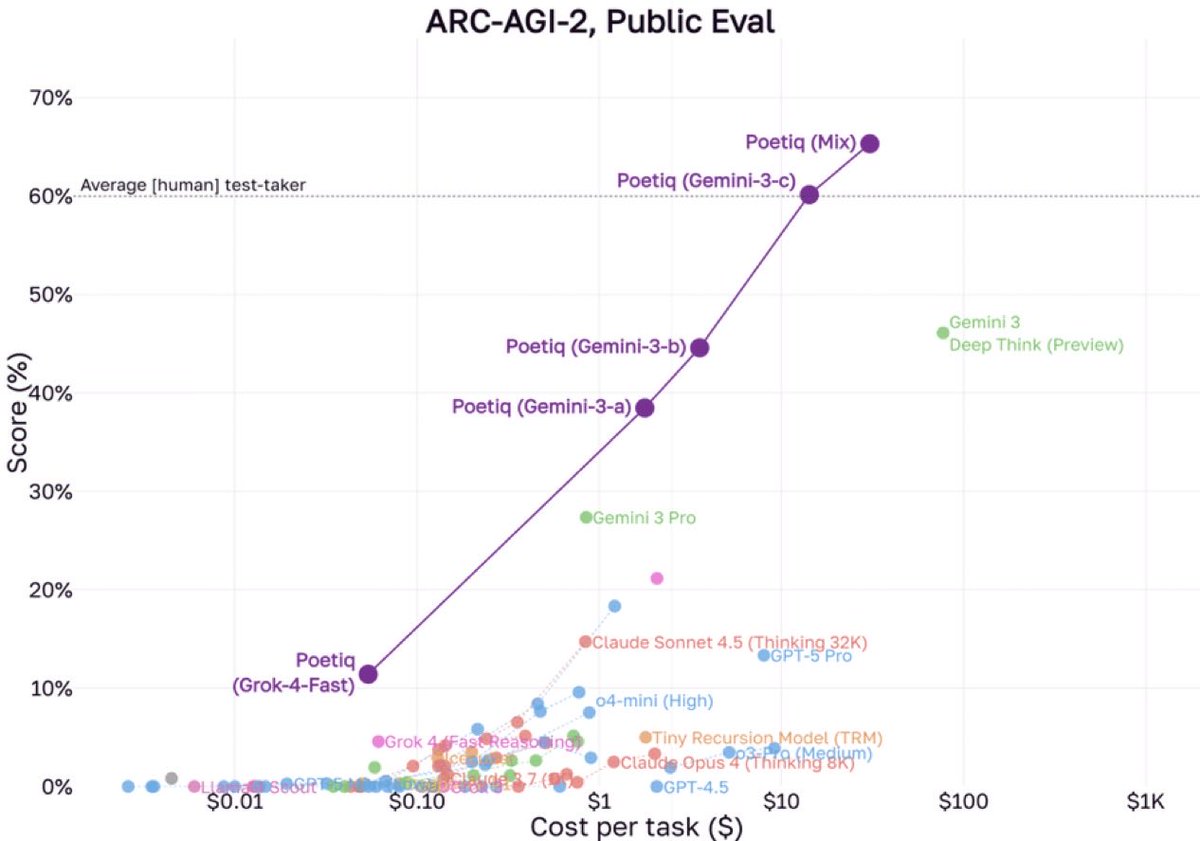
We’re coordinating with @poetiq_ai to verify their reported ARC-AGI Public Eval score Only results on the Semi-Private hold-out set count as official ARC-AGI scores Once the verification is complete, we’ll publish the result and supporting datapoints


