
Ali Naeimi
15 posts
Ali Naeimi
@Ali_NT99
MSc AI | Research Engineer | Distributed Pretraining optimization
Manchester, UK Katılım Temmuz 2023
43 Takip Edilen3 Takipçiler

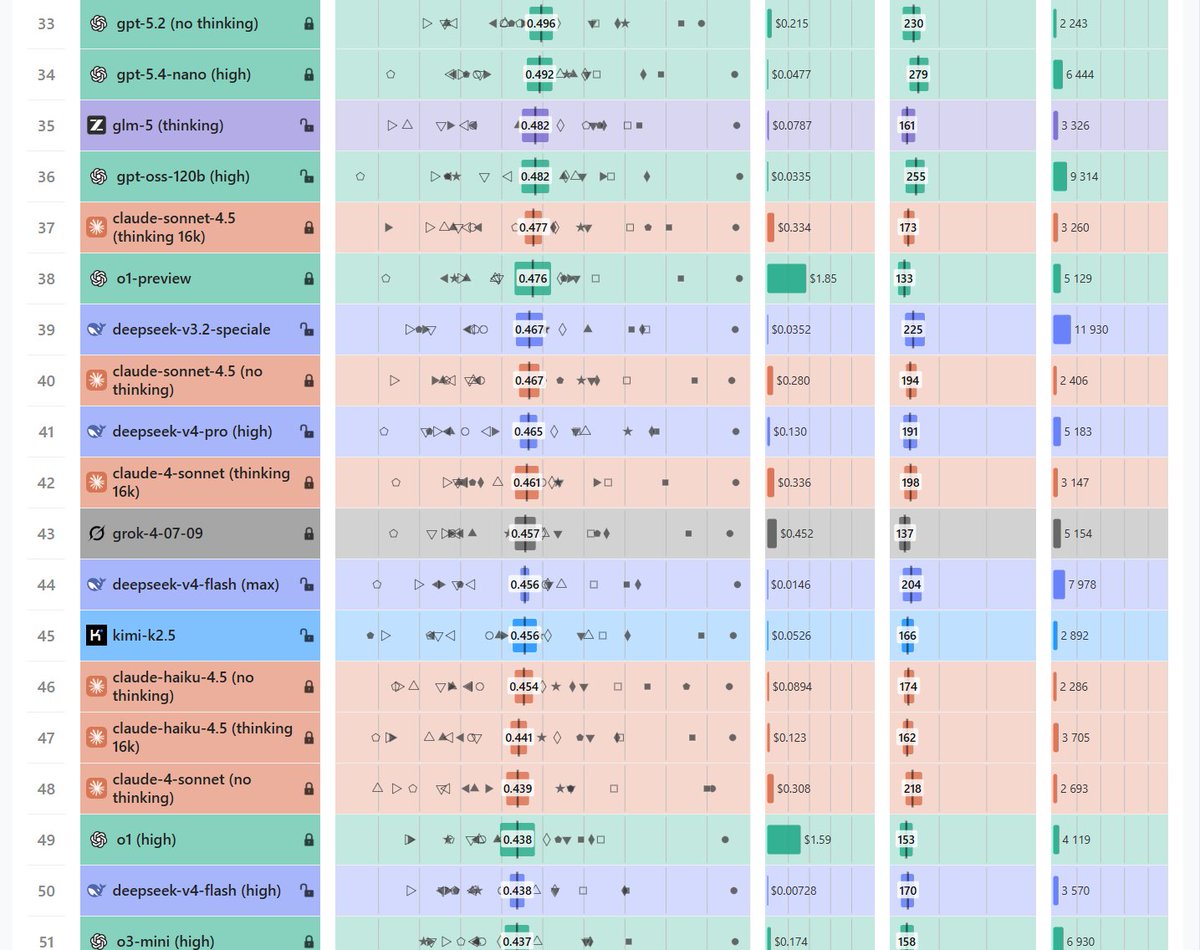
Deepseek v4 pro (high) scores 46.5% on WeirdML, which is way lower than I'd expected. It does not exceed deepseek 3.2 speciale, although it does match it with far fewer tokens.
I ran this through fireworks AI, and the outputs look reasonable, but the results being this weak makes me suspect something is wrong.
I have a separate run with "max" reasoning setting ongoing right now.
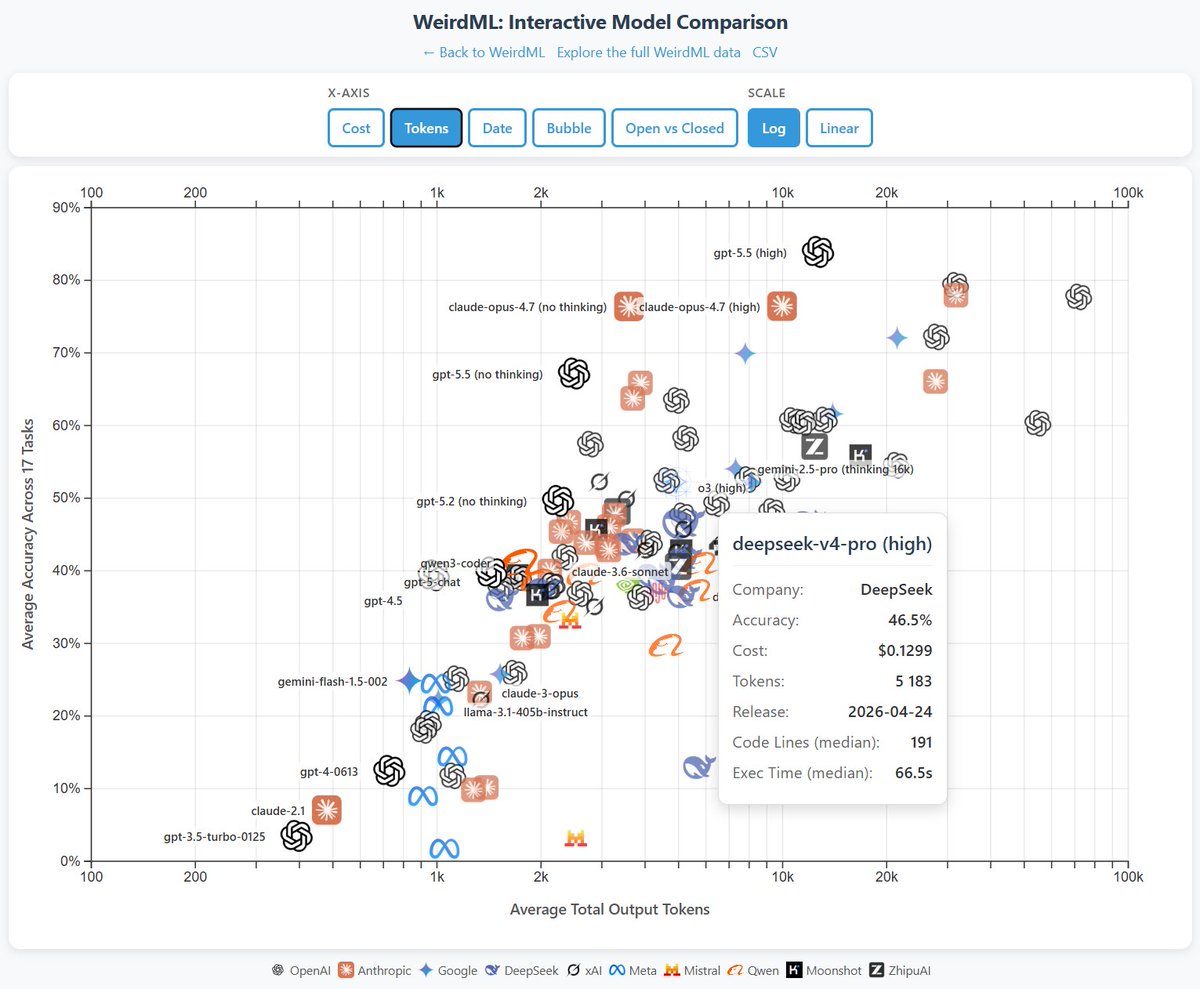
Håvard Ihle@htihle
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two figures. The first one shows an overview of the overall results as well as the results on individual tasks, in addition to various metadata. The second figure shows cost vs performance and shows a clear scaling with better results for higher costs. We also have a very varied pareto frontier with 11 models from 6 different companies having the best accuracy for a given cost for at least some of the cost range. Grok 3, Claude Opus 4 and GPT 4.5 are the ones that underperform for their costs, while Gemini pro and o3 pro have the best results at the highest costs. Qwen3 30B3A, grok 3 mini and deepseek R1 also each represent a good chunk of the pareto frontier.
English
@yifan_zhang_ And someone (me :D) has already created fused triton kernels for it, and tested it on protein LM training :)
github.com/alint77/flash-…
English

Embarrassingly, just found that someone wrote a paper exactly the same of this tweet, and call it “mHC-lite” (arxiv.org/abs/2601.05732)
That is a bold move.

Yifan Zhang@yifan_zhang_
Yes, spot on! For n=4, any doubly stochastic matrix W has an exact decomposition (Birkhoff-von Neumann): W = \sum_{i=1}^{24} \alpha_i P_i with \alpha_i \geq 0, \sum \alpha_i = 1, and P_i the 24 permutation matrices. Just set \alpha = \text{softmax}(\text{logits}) over 24 trainable logits → exact, differentiable, no Sinkhorn needed. Clean trick for small n!
English

I just saw a job named "mnist_train" on the cluster with H200s (140GB of VRAM).
Welcome to Slovak science. We will overtake all of you soon.
English
@kellerjordan0 @wen_kaiyue A ~5x faster, FSDP2 compatible implementation of MuonH in Dion for anyone interested:
github.com/microsoft/dion…
English

New modded-NanoGPT optimization benchmark result: @wen_kaiyue has improved upon both the Muon and AdamW baselines, by replacing their weight decay with hyperball optimization. The new record is 3325 steps.

English
@kellerjordan0 New Record: -125 steps - Normuon for MLP - CWD:
github.com/KellerJordan/m…
English
Modded-NanoGPT Optimization Benchmark
Hundreds of neural network optimizers have been proposed in the literature, recently including dozens citing Muon: MARS, SWAN, REG, ADANA, Newton-Muon, TrasMuon, AdaMuon, HTMuon, COSMOS, Conda, ASGO, SAGE, and Magma, to name a few.
The majority of this innovation is happening in the public research community. But the community currently lacks a widely accepted, easily accessible way to compare and make sense of the deluge of methods. As a result, promising new ideas get buried, and spurious results go unchallenged.
To help address these issues, I'm releasing a new optimization benchmark. It's designed for maximum simplicity and speed: Just a single file containing ~350 lines of plain PyTorch, which can complete a baseline LM training within 20 minutes of booting up a fresh 8xH100 machine. It also works with {1,2,4}xH100 or A100. These attributes make the new benchmark more accessible than any prior work.
The rules are simple: The optimization algorithm can be changed arbitrarily, with the goal being to minimize the number of training steps needed to reach 3.28 val loss on FineWeb (this is the same target loss as in the main speedrun). Modifying the architecture or dataloader, on the other hand, is not allowed. Wallclock time is unlimited, in order to give a fair chance to optimizers which would need kernel work or larger scale to become wallclock-efficient.
Like the main NanoGPT speedrun, submissions are open, and new results will be publicly broadcast. Beyond just improving the step count record, another goal of the benchmark is to collaboratively produce well-tuned baselines for as many optimizers as possible. For example, any improvement to the benchmark's best hyperparameters for AdamW would be considered a worthwhile new result.
This benchmark is not intended to be the final measure of optimizer quality across all domains. Convenient shared experimental infrastructure which covers the full space of possibilities -- across varying batch size, tokens per parameter, model scale, epoch count, and architecture -- is desirable, but far beyond the current status quo. This benchmark is only meant to be one step towards that goal.
To start the benchmark off, I've spent ~20 runs tuning baselines for Muon and AdamW. From time to time over the next few weeks, I'll add another optimizer from the literature, with my best effort at finding good hyperparameters. Researchers interested in neural network optimization are invited to join in by picking an optimizer and giving it a try on the benchmark. All optimizers are welcome, and even runs that don't necessarily have the best hyperparameters are desirable additions to the repo, because each new run adds to the collective knowledge.

English
@kellerjordan0 I think it's a good idea to add DDP instead of manual NCCL calls for better overlap and throughput on PCIE instances since one of the goals is to make this track more accessible: github.com/KellerJordan/m…
English
@htihle It might be same ish on average but It’s a massive improvement in the worst performing tasks compared to other models… In actual complex coding tasks that’s a much more important metric imo… Would love to see how 5.5 performs too.
English
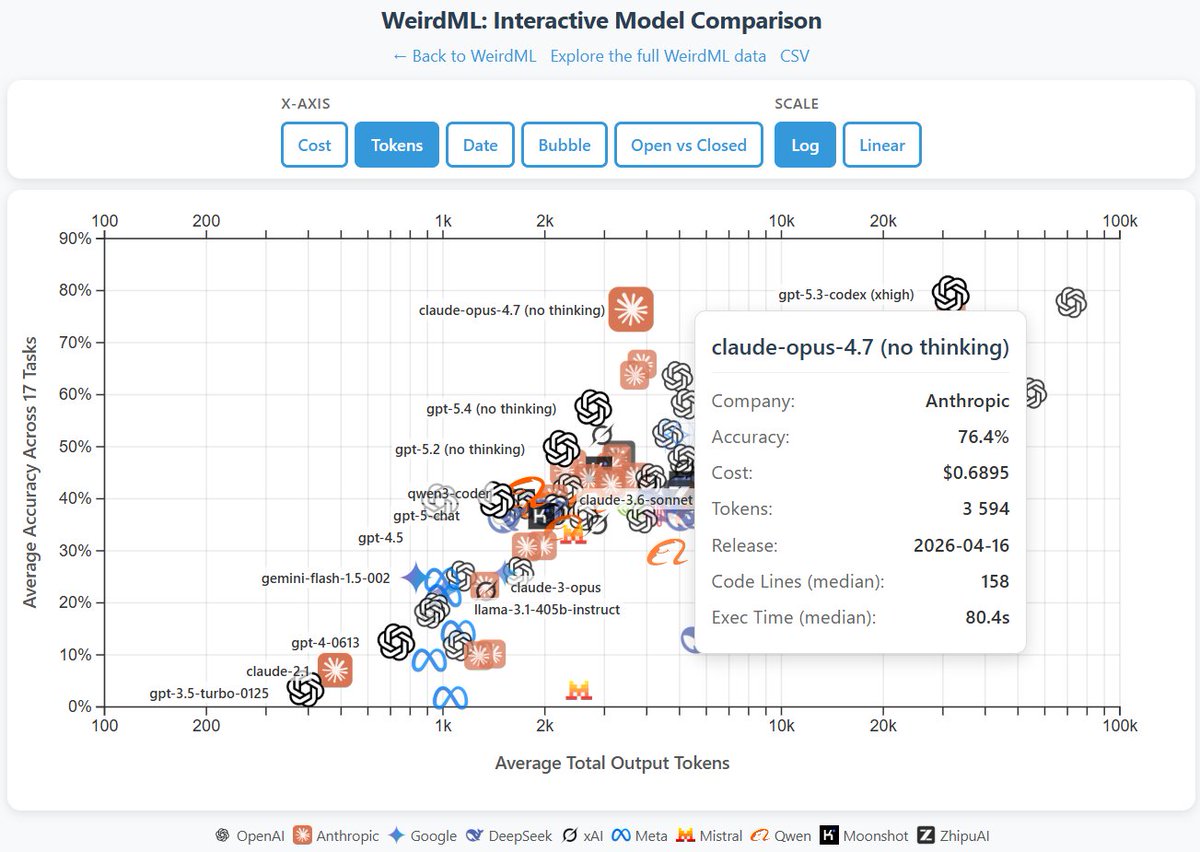
Claude Opus 4.7 (high) scores 76.4% on WeirdML and does not improve on the non-thinking version.
It's probably a bit better, but within the error bar. It shows a higher peak performance, with a new individual high score on 4 of the 17 tasks.
It uses much less tokens, 10k vs 32k for 4.6 (high). I may try to run with max setting later.

Håvard Ihle@htihle
Claude Opus 4.7 (no thinking) scores 76.4% on WeirdML, right behind gpt 5.4 (xhigh) at 77.7%, Opus 4.6 (adaptive) at 77.9% and gpt 5.3 codex (xhigh) at 79.3%, using an order of magnitude less tokens. This looks like a major step forward, things are moving fast now! Results with thinking next week.
English
@TheVixhal ~Speed Of Light AVX2 matmul to speed things up: github.com/alint77/matmul…
English

Claude Opus 4.7 (no thinking) scores 76.4% on WeirdML, right behind gpt 5.4 (xhigh) at 77.7%, Opus 4.6 (adaptive) at 77.9% and gpt 5.3 codex (xhigh) at 79.3%, using an order of magnitude less tokens.
This looks like a major step forward, things are moving fast now!
Results with thinking next week.

Håvard Ihle@htihle
WeirdML v2 is now out! The update includes a bunch of new tasks (now 19 tasks total, up from 6), and results from all the latest models. We now also track api costs and other metadata which give more insight into the different models. The new results are shown in these two figures. The first one shows an overview of the overall results as well as the results on individual tasks, in addition to various metadata. The second figure shows cost vs performance and shows a clear scaling with better results for higher costs. We also have a very varied pareto frontier with 11 models from 6 different companies having the best accuracy for a given cost for at least some of the cost range. Grok 3, Claude Opus 4 and GPT 4.5 are the ones that underperform for their costs, while Gemini pro and o3 pro have the best results at the highest costs. Qwen3 30B3A, grok 3 mini and deepseek R1 also each represent a good chunk of the pareto frontier.
English
@MatternJustus Great work! Any plans on benchmarking GLM 5.1 as it's the open-weight SOTA atm?
English

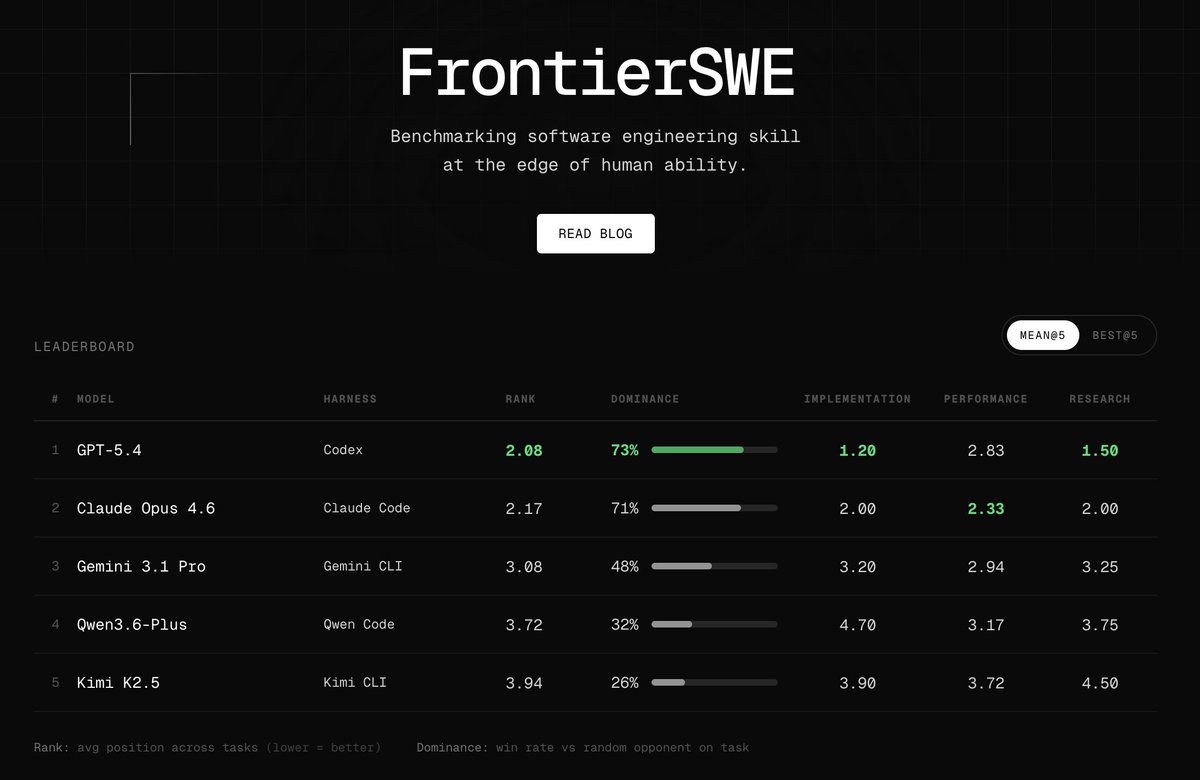
Introducing FrontierSWE, an ultra-long horizon coding benchmark.
We test agents on some of the hardest technical tasks like optimizing a video rendering library or training a model to predict the quantum properties of molecules.
Despite having 20 hours, they rarely succeed
English
@jino_rohit If anyone is interested in a more comprehensive worklog in X86 Assembly, check this out:
github.com/alint77/matmul…
English

@danveloper I'm curious, did you try putting the shared experts in RAM? should give a huge speedup with minimal extra RAM usage.
Also since you're using only 4 experts out of 10, this is extremely lossy in terms of model output quality.
English

@m_sirovatka Maybe Try sharding at sublayer level, shard attn and mlp separately.
English

Sometimes being GPU rich doesn't help you, does someone know of a way to not make FSDP backward materialize full layer grads in a reduce-scatter buffer? For GLM5 it's 40GB of VRAM just for that each layer, no matter the FSDP size. (orange in the img)

Matej Sirovatka@m_sirovatka
you can just do things when you're gpu rich (full post-train GLM5 being the things)
English
@andreslavescu I also have an mHC-lite implementation in Triton wit autotune and compile supprot with every kernel operating around 85% of theomax BW usage, pushing the overhead down from 35% of torch to only 11%, please check it out:
github.com/alint77/flash-…
English

Finally got to publishing mHC.cu on PyPi!
pypi.org/project/mhc-cu…
English

ML interview question: What is happening here?
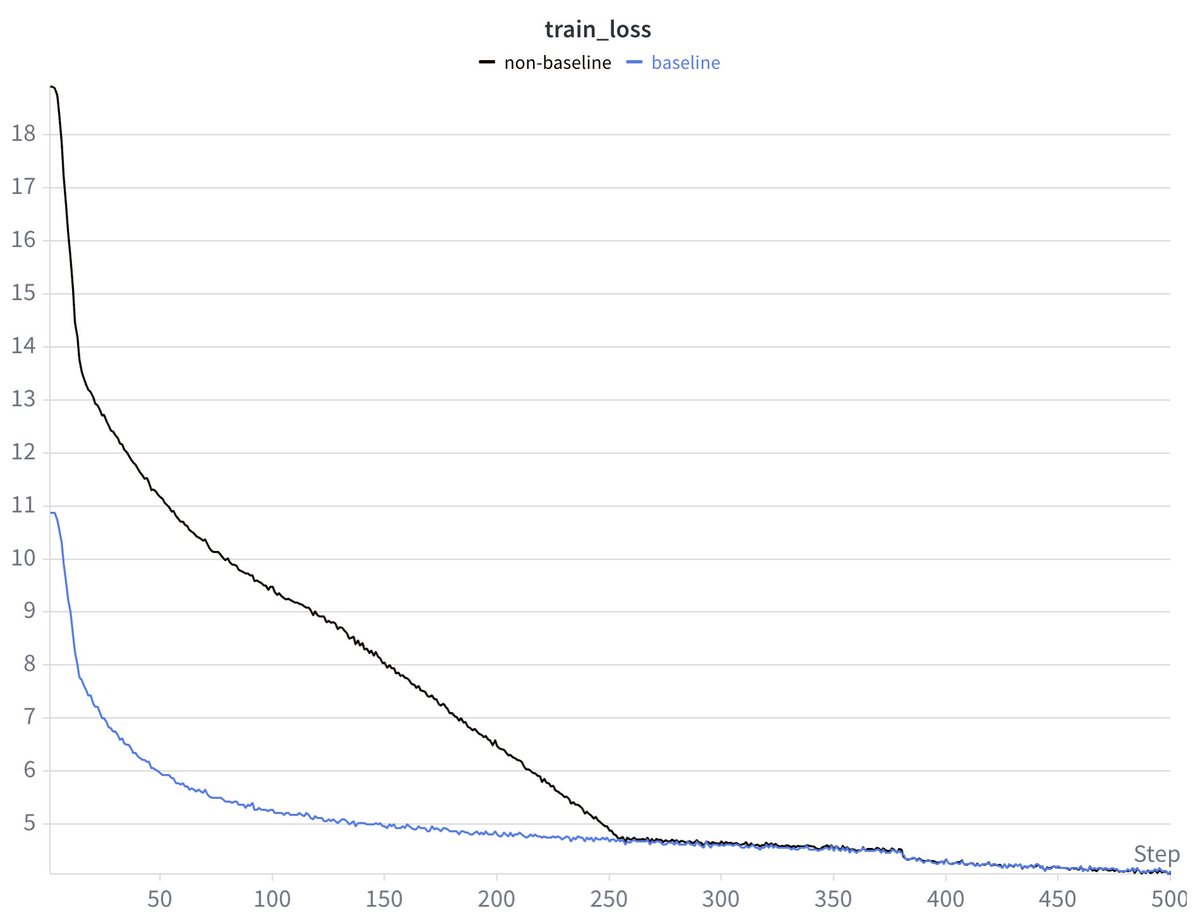
English