
Aryan Seth
733 posts

English


Aryan Seth retweetledi

@willccbb but plain OPD has issues - mostly pointed out in this paper; arxiv.org/pdf/2604.03128
"privileged information" leads to an irreducible loss term, and i have not found much luck with training stability (maybe this is a personal issue lol)
English

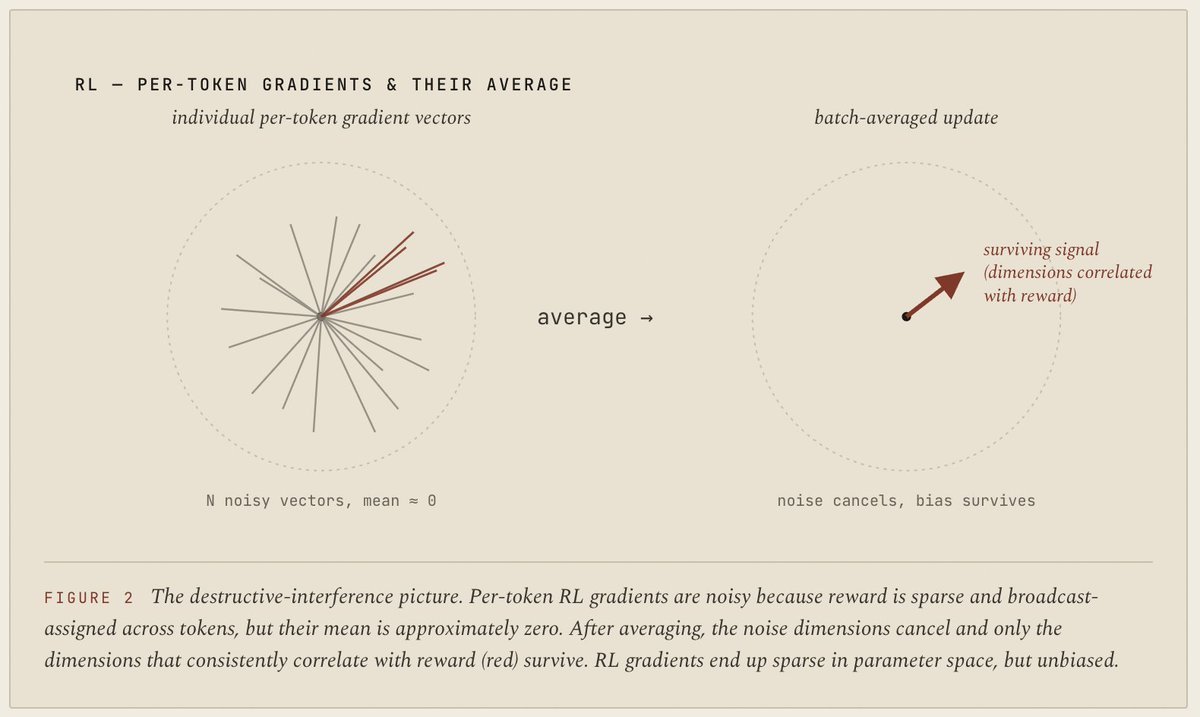


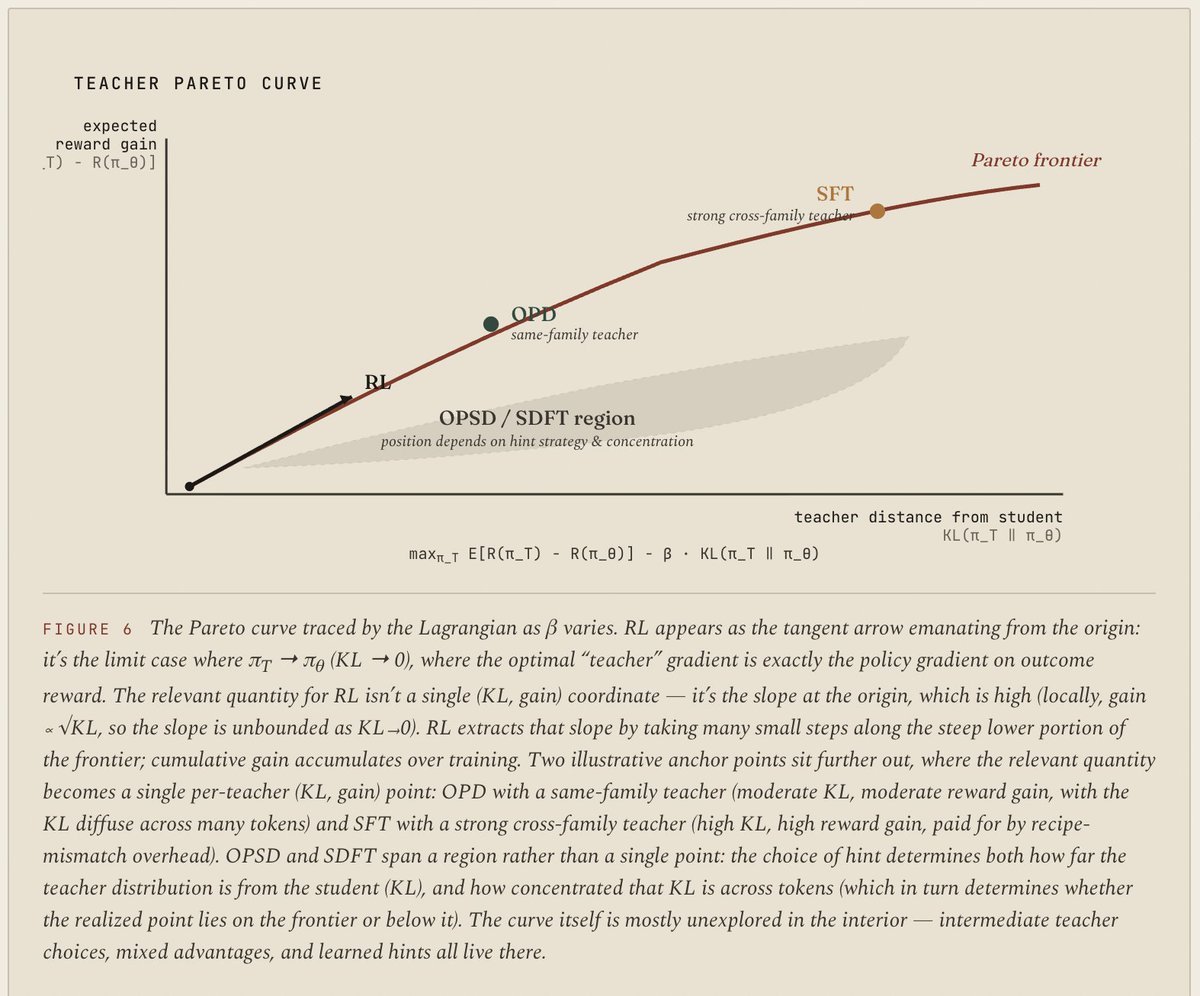


calling Mythos a preview now feels ragebait-ey
Anthropic@AnthropicAI
New on the Science Blog: We gave Claude 99 problems analyzing real biological data and compared its performance against an expert panel. On 23 problems, the experts were stumped. Our most recent models solved roughly 30% of those—and most of the rest.
English

SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI.
The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models.
Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
English
Aryan Seth retweetledi

thanks to arsenal there will be no drought this year my tears shall fill every river
English
Aryan Seth retweetledi

@_lyraaaa_ they all track the same underlying signal but the directions are different because each layer performs a Richelot step on the representation.
the polynomial gets factored.
the curve transforms.
the class persists.
English

found a vector in gemma4 e4b that roughly correlates with perplexity
the more surprisal in the passage, the stronger this vector fires
R²=0.775, corr=0.880, p<10⁻³³²³⁶
this is avg across all layers, L20 and 21 have R² 0.828 and 0.845 alone
wonder what i can do with this
English
count the false positives count the false positives count the false positives count the false positives count the false positives count the false positives
Stanislav Fort@stanislavfort
New post: We tested the Mythos showcase vulnerabilities with open models. They recovered similar scoped analysis! 8/8 models found the flagship FreeBSD zero-day, including a 3B model. Rankings reshuffle completely across tasks => the AI cybersecurity frontier is super jagged!
English
Aryan Seth retweetledi

We got into @ycombinator!
A few months ago, @onkar_borade_10, @SujaySriv , and I met at a football game in HSR, Bengaluru, and went deep on one question -
Why does SaaS take months and a huge team to get delivered after the sale? Building a good product should be enough, right?
Right?
Messy integrations. Handoffs. Siloed information. Poor documentation. Fragmented data. The list goes on.
We started a company with the vision to make SaaS self-serve.
@lab0_ai
Huge thanks to @dessaigne , @collinmathilde , and the YC team for this opportunity.
If your product rollouts take months or you're a system integrator/partner/FDE implementing SaaS, let's talk. Link below.



English
Aryan Seth retweetledi

Breaking news: Anthropic buys the All in podcast just to shut it down
Dario quoted as saying: “this isn’t even about new media I just want to stop seeing them on my timeline”


English
@viplismism sure, harnessing works at inference, but I still don't follow how this solves sparse reward because that's a training-time problem; recursive call = tool call, so you can train using the subagent output, but the reward is still a scalar (higher due to harness), but sparse
English

@AryanSeth07 true in principle i guess, but in practice the harness has to do the heavy lifting man. models tend to jump to conclusions or lose context fast if the harness isn't driving the search process properly
English
most people don't realize that rlms are just solving the sparse reward problem for long context! instead of an llm hunting for checkmate in one giant forward pass, it's like you break it into bite-sized reasoning tasks. every recursive step is a checkpoint where the model updates its internal value of the context before moving to the next piece it turns a massive search space into a dense signal
English
Aryan Seth retweetledi


there's going to be a movie at some point about hinton being like oppenheimer or something with the toronto lab being the ai manhattan project and sam altman and co being like the govt and scaling the models
English