
Imama
634 posts
Imama
@Caffeinix_alche
Gpu heavy thoughts at 1024 threads, token-deep focus and a coffee devotee.
404👾 🌎 ☁️ Katılım Eylül 2021
1.2K Takip Edilen141 Takipçiler
@cwolferesearch @ManavGarkel Valid point on the logging approach! Also do you find evaluating the reasoning quality at each handoff changes how you structure your transcripts? Asking because Superbryn are tackling agent observability from that angle curious how the community is thinking about this.
English

@ManavGarkel you need to log details of all agent actions / handoffs and then you can add checks to the transcript to verify aspects of how handoffs / problem solving occured.
English
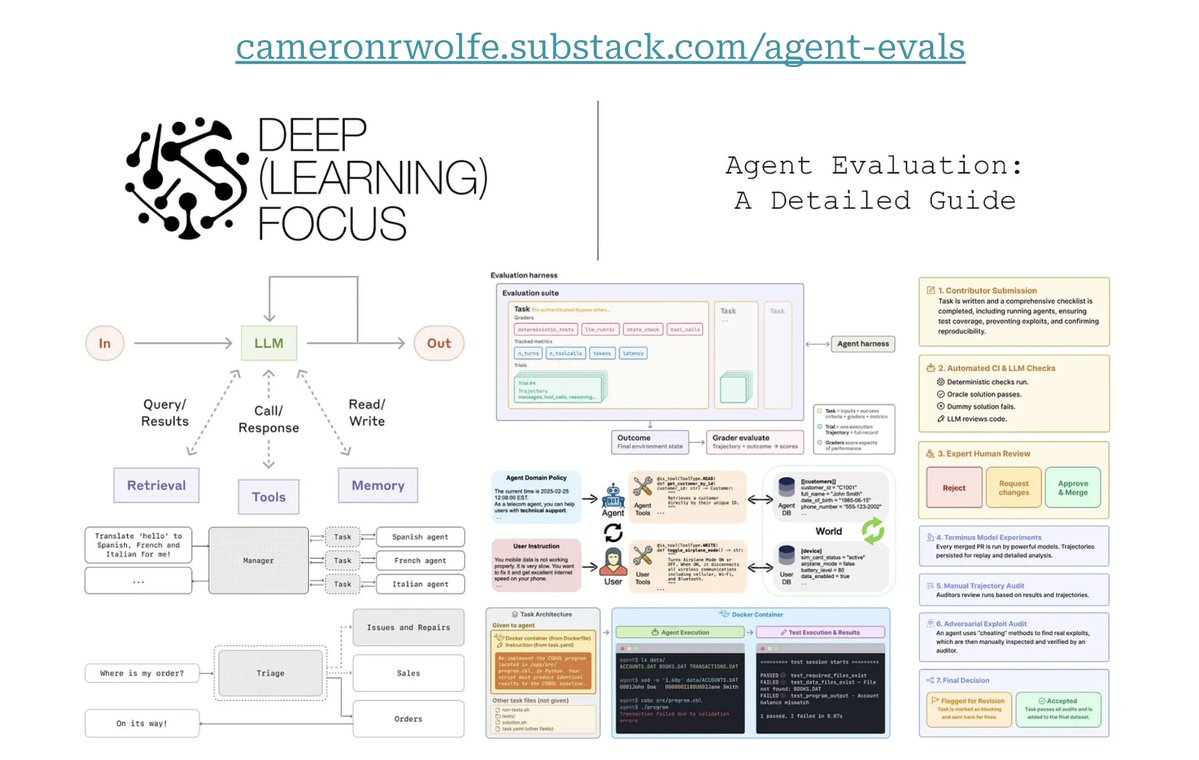
I just published a detailed guide on evaluating agents. It covers:
1. Agent fundamentals (everything from basic concepts to complex ideas like multi-agent systems).
2. Common evaluation patterns / frameworks observed in practice.
3. Case studies of popular agent benchmarks (e.g., Tau-Bench and Terminal-Bench series).
Building high-quality evaluation capabilities is now more important than ever due to the growing adoption of agents in high-stakes applications like coding and medicine. Although evaluation is time-consuming and difficult, learning how to properly evaluate agents is incredibly valuable. Rigorously measuring performance and not relying on anecdotal checks allows us to rapidly improve agent capabilities.
English
Interesting..LLMs rediscovered Fourier analysis to do arithmetic.numbers encoded as frequencies on a circle. addition = phase shift. not memorizing 6+7 interfering wave patterns until the answer emerges.
what other frameworks is it running that we haven't discovered yet?
Goodfire@GoodfireAI
Neural networks do math by rotating shapes. We found a shape-rotating calculator hidden inside an LLM – and it’s used for more than just math! (1/6)
English
@kalamazooooo @aigrantsindia @smallest_AI @nvidia @jarvislabsai @0xBosky @nova_residency Interesting 👀 any specific domains/projects you’re hoping people build around or is it fully open-ended chaos and creativity? The “Uber’s on us” part is actually wild 😂
English

nova's 1st partner just dropped
@aigrantsindia is covering:
- voice ai credits @smallest_AI
- 90+ open models @nvidia
- 5000 GPU hrs @jarvislabsai
- everyone's ride to the hacker house covered
yes. your uber is on us.
thanks @0xBosky :D

English
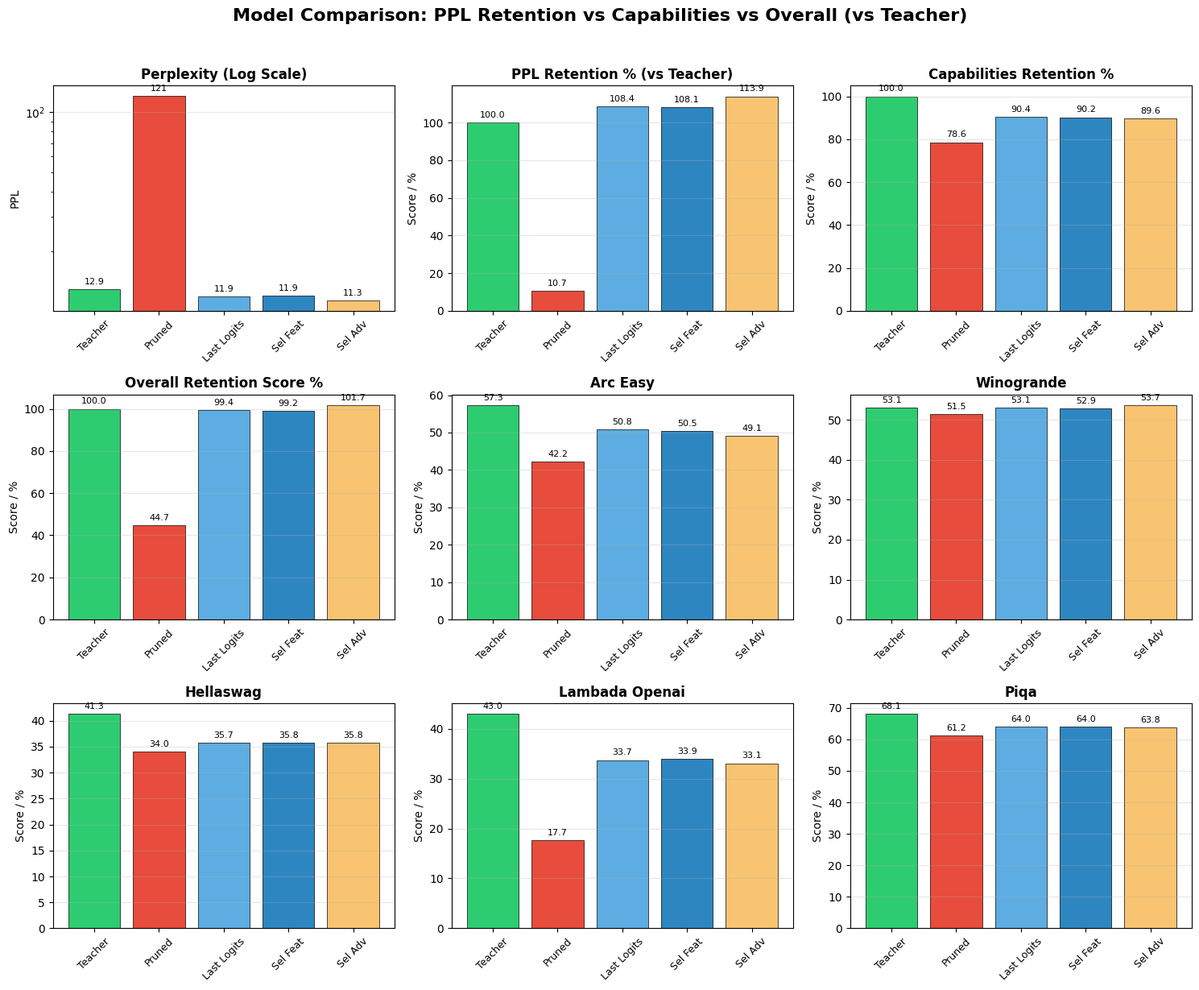
@PereMartra @ManningBooks Really cool result reminds me of NVIDIA's Minitron approach prune low-importance blocks first, then distill the capability back in. You're compressing redundancy not intelligence. Has anyone tried pushing this further with layer-sharing before the distillation step?
English

A Gemma model with 4 fewer Transformer blocks achieves better PPL and Winogrande than the original.
That's what pruning + Knowledge Distillation achieve together.
Chapters 5 & 6 of Rearchitecting LLMs dropped on @ManningBooks .
hubs.la/Q040twqq0
#LLMs #MachineLearning
English

Got an idea? Find your co-founder.
Create your project and get matched with founders who align on equity, commitment, and vision.
Takes 2 minutes.
English
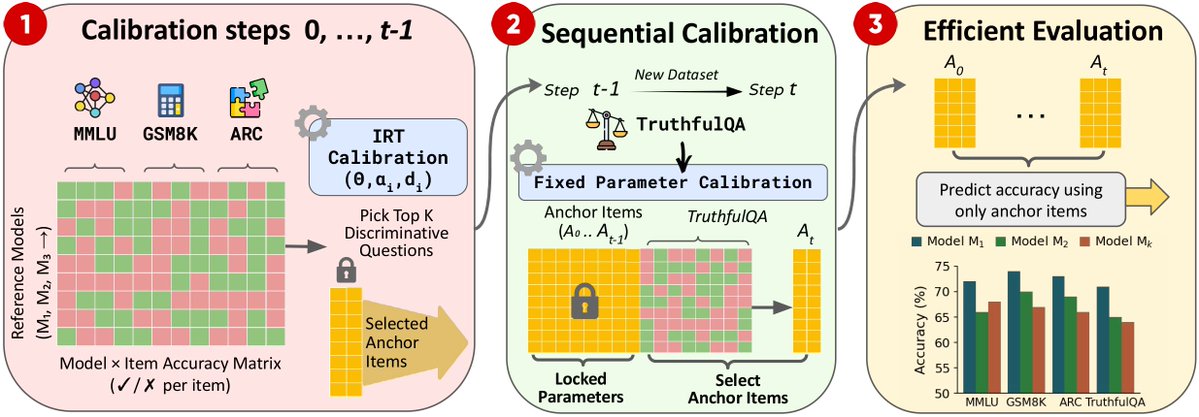
@EliyaHabba Interesting work .Benchmarks are starting to look like distributed systems 😅
You can’t recompute the whole state every time something new arrives.
Using anchor tasks + calibration feels a lot like versioning API evolve the system without breaking comparability.
English

New datasets keep coming,
New models keep coming.
Frustrating!
How can we evaluate everything on everything?
How do we keep scores comparable over time?
We propose a way to grow benchmark suites without losing comparability.
Details:👇🧵
English
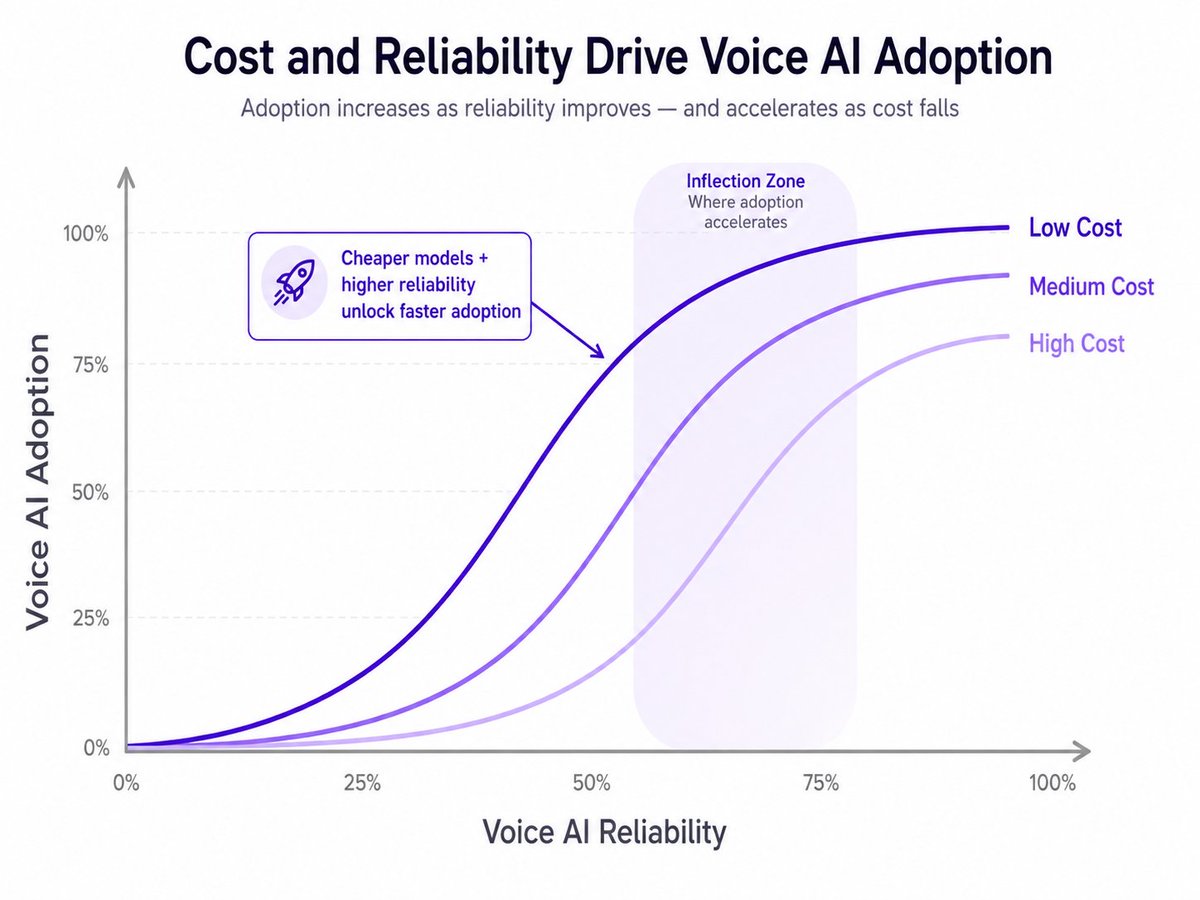
@nikkithashanker @FarzaTV @heyclicky Feels a lot like the shift from command lines to GUIs😀 once the interface becomes more natural adoption becomes easier.For voice agents latency is the new loading screen and reliability is the new UX.
English

Mark my words, voice will become the new interface for software
We are already seeing this with @FarzaTV 's @heyclicky. Even companies like Zillow are building agents to help people buy homes
Every interface shift needs two things:
1. Lower cost.
2. Higher reliability.
OpenAI@OpenAI
Introducing GPT-Realtime-2 in the API: our most intelligent voice model yet, bringing GPT-5-class reasoning to voice agents. Voice agents are now real-time collaborators that can listen, reason, and solve complex problems as conversations unfold. Now available in the API alongside streaming models GPT-Realtime-Translate and GPT-Realtime-Whisper — a new set of audio capabilities for the next generation of voice interfaces.
English

It is NeurIPS deadline in 4 days so yeah it is not possible to take a day off.
The PhD Place@ThePhDPlace
Do NOT feel guilty for taking a day off at the weekend
English
@sarahookr @adaption_ai hey this sounds super exciting the idea of shaping adaptive intelligence + environments is 🔥 what you’re building at Adaption AI feels really fresh
curious... what kind of problems or research directions are you most focused on hiring for right now?
English

Stop inheriting intelligence. Shape it.
Join us to build the next era of intelligence @adaption_ai
Hiring across research and engineering. Very exciting time to join.
We cooking something very special for upcoming releases bridging adaptive intelligence + environments.
English
@YashikaChugh4 Damn the keyboard looks amazing 🤩 I am already sold @c_engines if this is the vibe
English




@maharshii This is more like you summoned an ancient GPU deity.
At this point if you whisper “wgmma” three times into your terminal Jensen Huang probably appears in a leather jacket and asks about your memory bandwidth.
Go hydrate, your registers are spilling 🫠
English

triton, gluon, cutedsl, hopper, blackwell, tensorcores, layouts, composition, local_tile, partitionS, partitionD, wgmma, tcgen05, TMA, block scaling, coalesced access, ampere, ada lovelace, cutlass, cublas, cudnn, flash attention, gemm, sgemm, fp16, bf16, mxfp8, nvfp4, int4, quantization, mixed precision, occupancy, reductions, warp divergence, bank conflicts, memory coalescing, shared memory, global memory, texture memory, constant memory, unified memory, epilogues, kernel fusion, graph optimization, tensorrt, torch compile, dynamo, inductor, graph capture, thread blocks, warps, SIMT, streaming multiprocessors, L1 cache, L2 cache, register spilling, thread divergence, memory bandwidth, compute capability, CUDA cores, ldg, stg, ncu, nsys, atomic operations, syncthreads, cooperative groups, dynamic parallelism, persistent kernels, vectorized loads, static quantization, tensors, swizzling, predication, instruction throughput, memory latency hiding...

English
@abhisheknaironx Haha lowkey smart marketing 😄 people might look it up and realize it’s something else entirely.
English

my frnd saw the pink wispr flow autos in Koramangala and was convinced that it's a sanitary pads company 🙂
I didn't take any photos, so here's a stolen one.

English
@DalRotiForLife Me too still waiting for this 😭😭never would have thought that I will wait this desperately in Blr
English

@Ramneet_Singhh try this:Passing an empty torch_cuda_arch_list makes vLLM auto-detect your current GPU and build only for that arch kills 60%+ of nvcc work. VLLM_USE_PRECOMPILED pulls pre-built kernel wheels. sccache over ccache.
GPU-accelerated compilation of GPU code remains a cursed problem💀
English

VLLM build from source is reminding me of the nightmare that is LLVM build from source. GPU-accelerated compilation please, anyone?
English
@cheshta_rajora @fmrbangalore @BangaloreRoomi @GruhamBot @FlatsnFlatmates @Flashmateshq Hey! I know a place that should fit your budget pretty well and is in a decent location too. DM me I’ll share the details 👍
English

Hello Bengaluru! Looking for a 1/2bhk for myself to move in from June 1st. Budget up to ₹17k. Preferred within a 6–7 km radius of Lalbagh. Slightly further if metro is walking distance. Please DM with leads. @fmrbangalore @BangaloreRoomi @GruhamBot @FlatsnFlatmates @Flashmateshq
English
@nikkithashanker @NotTheCh05en1 @Parthjain_01 Looks like a casual ‘weekend chill’ turned into a full blown brainstorming session 🫡
Respect the hustle, but also… does the whiteboard at least get weekends off? 🙃
English
The urge to write a LinkedIn style post about working on weekends is always there, on X

English


