Sabitlenmiş Tweet

Amazing work from the team to build FalconPerception and FalconOCR, two early-fusion perception and OCR models! Check out the demos, technical report, models, and PBench benchmark. Many thanks to the amazing people in the vision team and TII for making this possible.
Yasser Dahou@dahou_yasser
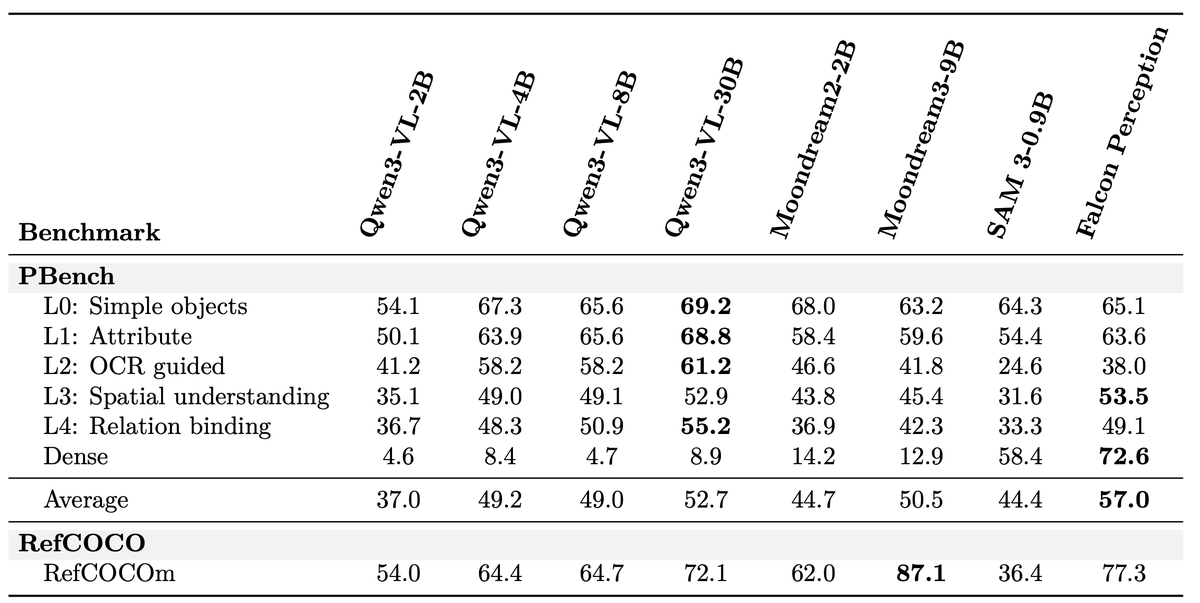
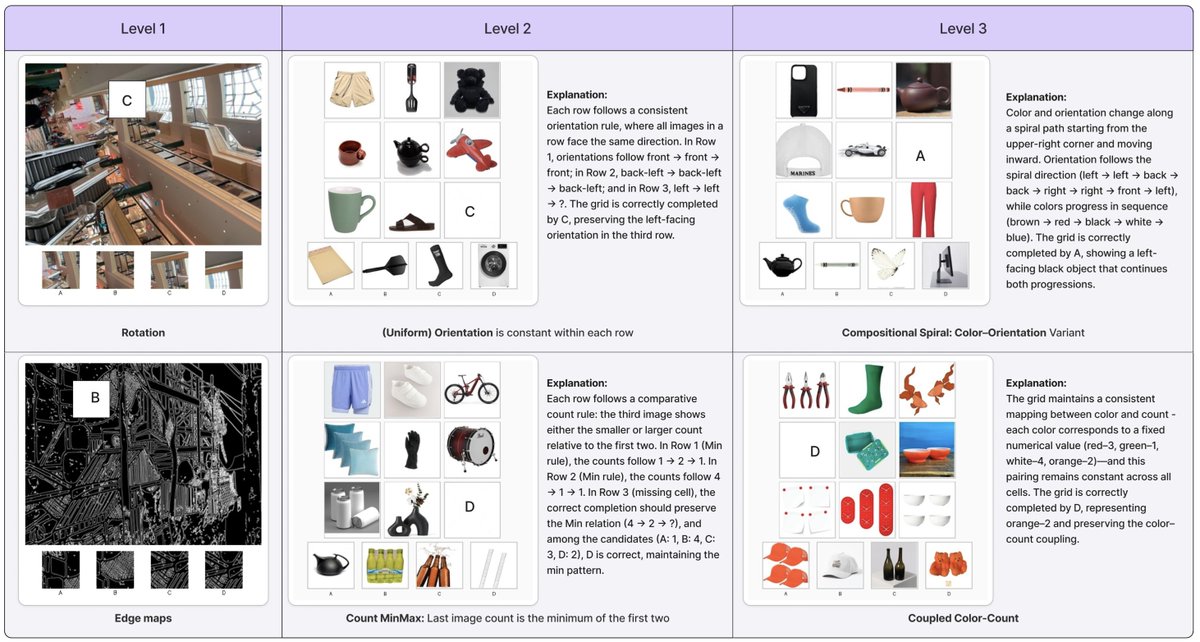
We are releasing Falcon Perception, an open-vocabulary referring expression segmentation model. Along with it, a 0.3B OCR model that is on par with 3-10x larger competitors. Current systems solve this with complex pipelines (separate encoders, late fusion, matching algorithms). We developed a novel simpler "bitter" approach: one early-fusion Transformer (image + text from first layer) with a shared parameter space, and let scale + training signal do the work. Please check our work ! 📄 Paper: arxiv.org/pdf/2603.27365 💻 Code: github.com/tiiuae/falcon-… 🎮 Playground: vision.falcon.aidrc.tii.ae 🤗 Blogpost: huggingface.co/blog/tiiuae/fa…
English