Aviraj Bevli retweetledi

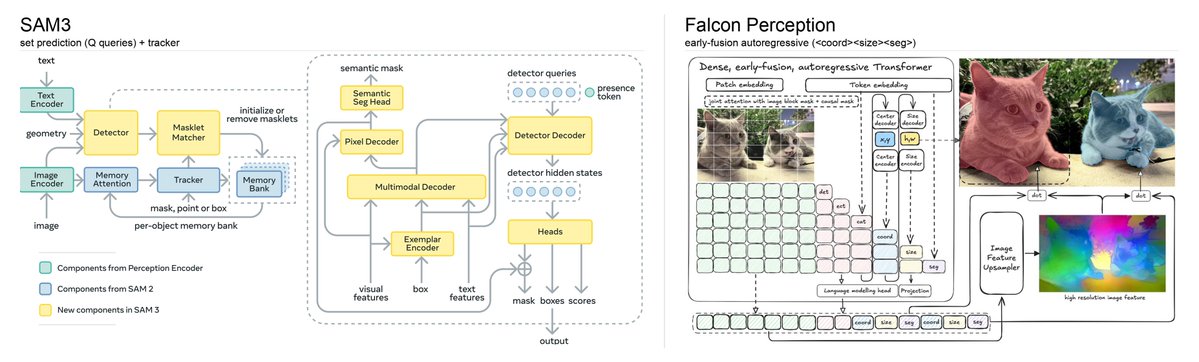
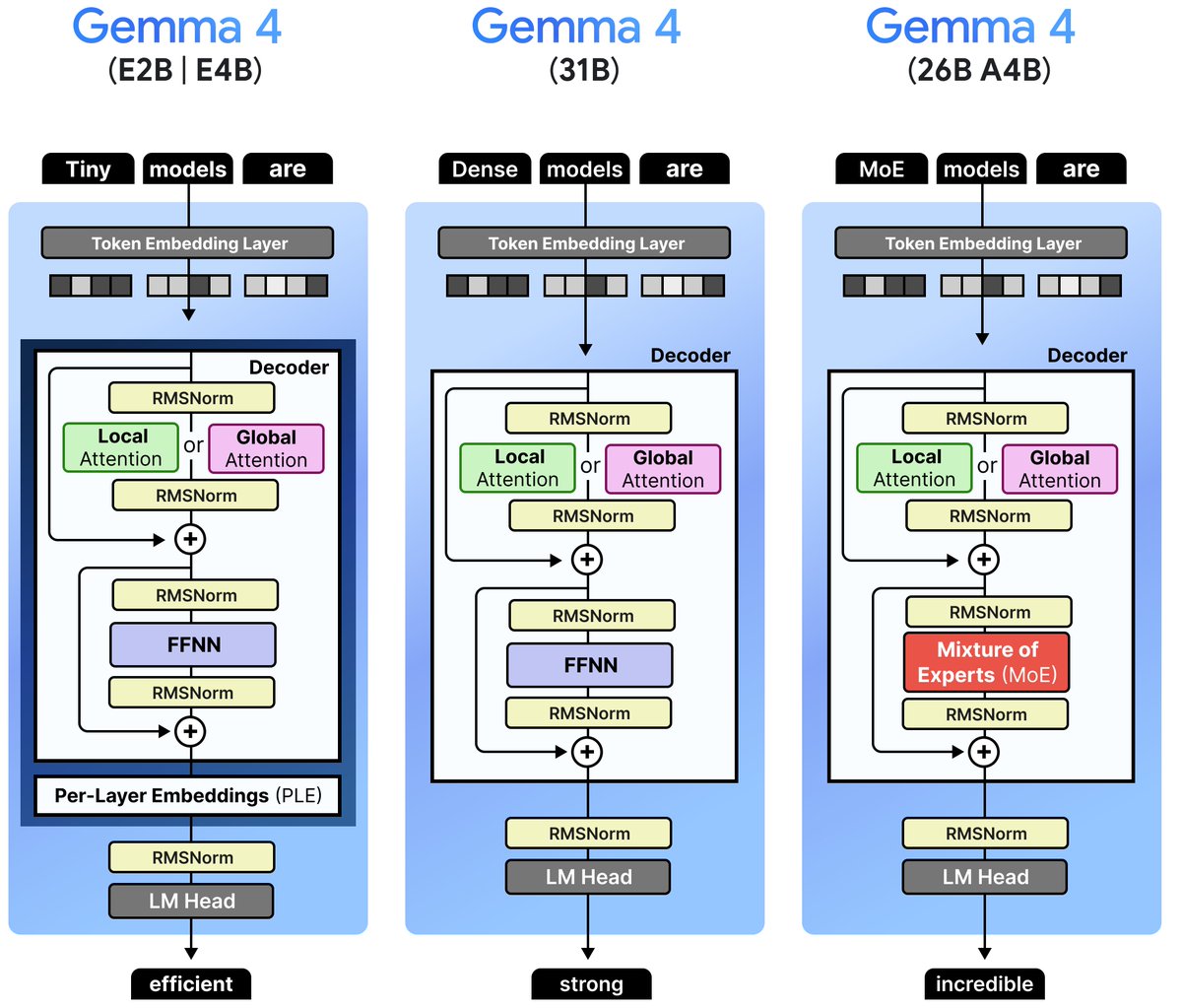
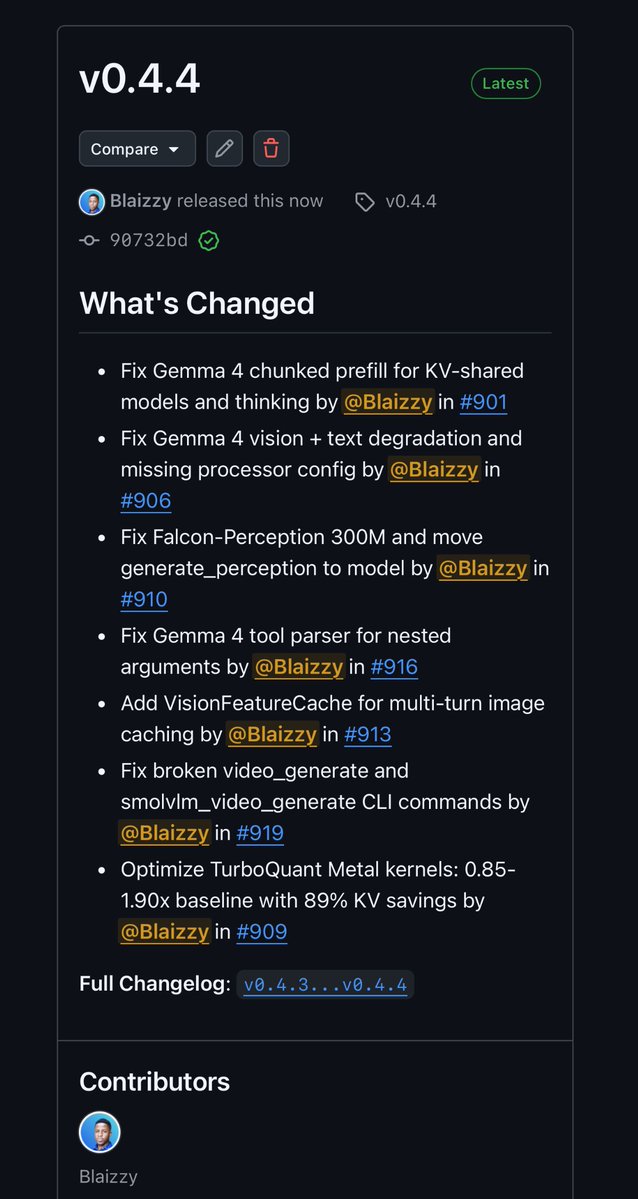
launching `data-label-factory` a generic auto-labeling pipeline. You write a YAML for your object class and run one command: a vision dataset on a 16 GB MacBook. No GPU, no labelers, no vendor. Using Gemma 4 @Google mlx-vlm @Prince_Canuma + Falcon Perception @lkhphuc
here's how : 🧵(point your /agent at the claude.md file to start asap)
English