Sabitlenmiş Tweet
CricketInSand
16.6K posts

@callebtc Nor should you. The industry created benchmarks to represent progress within their own interests. They do not reflect reality in a meaningful way.
x.com/sukh_saroy/sta…
Sukh Sroay@sukh_saroy
New research just exposed the biggest lie in AI coding benchmarks. LLMs score 84-89% on standard coding tests. On real production code? 25-34%. That's not a gap. That's a different reality. Here's what happened: Researchers built a benchmark from actual open-source repositories real classes with real dependencies, real type systems, real integration complexity. Then they tested the same models that dominate HumanEval leaderboards. The results were brutal. The models weren't failing because the code was "harder." They were failing because it was *real*. Synthetic benchmarks test whether a model can write a self-contained function with a clean docstring. Production code requires understanding inheritance hierarchies, framework integrations, and project-specific utilities. Different universe. Same leaderboard score. But it gets worse. A separate study ran 600,000 debugging experiments across 9 LLMs. They found a bug in a program. The LLM found it too. Then they renamed a variable. Added a comment. Shuffled function order. Changed nothing about the bug itself. The LLM couldn't find the same bug anymore. 78% of the time, cosmetic changes that don't affect program behavior completely broke the model's ability to debug. Function shuffling alone reduced debugging accuracy by 83%. The models aren't reading code. They're pattern-matching against what code *looks like* in their training data. A third study confirmed this from another angle: when researchers obfuscated real-world code changing symbols, structure, and semantics while keeping functionality identical LLM pass rates dropped by up to 62.5%. The researchers call this the "Specialist in Familiarity" problem. LLMs perform well on code they've memorized. The moment you show them something unfamiliar with the same logic, they collapse. Three papers. Three different methodologies. Same conclusion: The benchmarks we use to evaluate AI coding tools are measuring memorization, not understanding. If you're shipping code generated by LLMs into production without review, these numbers should concern you. If you're building developer tools, the question isn't "what's your HumanEval score." It's "what happens when the code doesn't look like the training data."
English

@RayMairead @hayasaka_aryan @Rightanglenews Foreign aid has exploded their population from ~250M to ~1.5 BILLION.
English


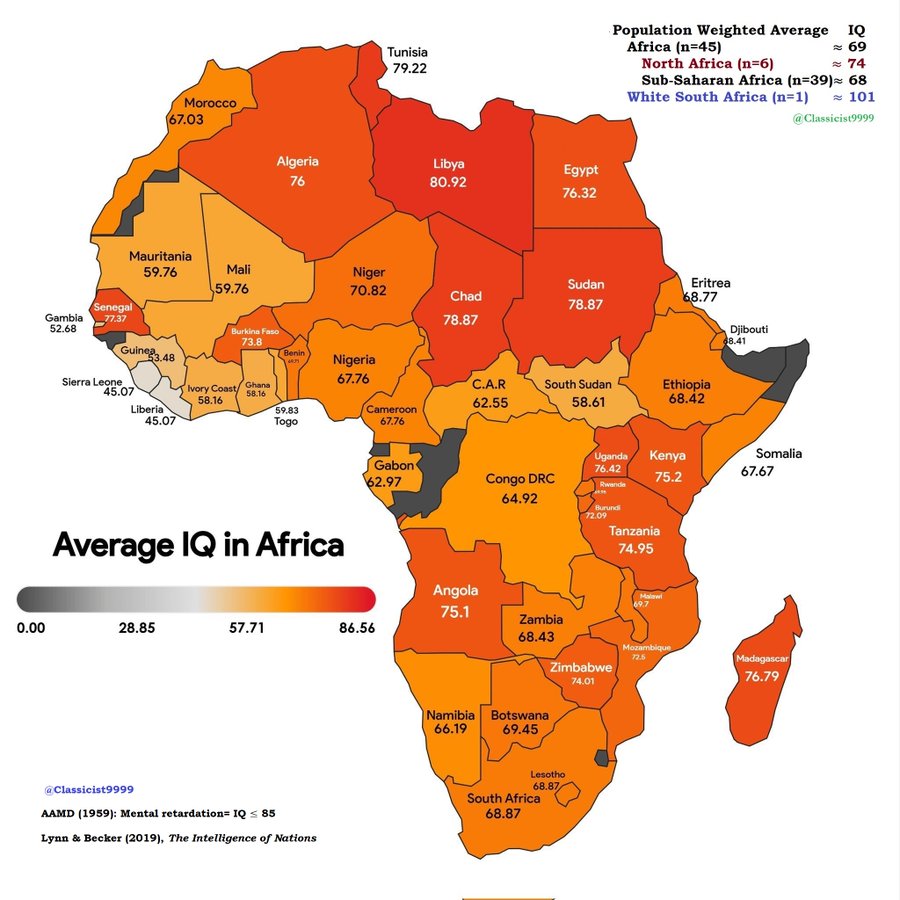
BREAKING - An Africa-based research team aiming to disprove Western claims about low IQ in African countries is going viral after conducting mass IQ tests in Lagos, Nigeria, only for over 50% of participants to score below 70, with a median score of 69.7.
English
@hayasaka_aryan @Rightanglenews Who has weaponized them and created these invasions?
x.com/AtRealBen/stat…
ⱤɆ₳Ⱡ ฿Ɇ₦@AtRealBen
“Kalergi Plan? Don’t talk about that! That’s just a debunked conspiracy theory, that’s just low IQ antisemitism man” Meanwhile:
English
@hayasaka_aryan @Rightanglenews The forced insertion into every non-African nation can only ever create conflict and envy. Which in turn drives further conflict. Which is the very nature of their weaponization against European nations.

English
@hayasaka_aryan @Rightanglenews * They are simply well NOT well adapted to...
English
@hayasaka_aryan @Rightanglenews They are well adapted to surviving in Africa. They are simply well well adapted to the modern world created by Europeans. Conflict only exists because a certain group has weaponized them and forced them into European nations. All African civilization was created by Europeans.
English

@ChrisDrz AI is insanely capital intensive.
They are building billions in data centers and buying even more in chips. Plus electricity!
English
Ford shutting down Electric Vehicle production.
Meta shutting down Virtual Reality investment.
Only a matter of time until companies pull way back on Artificial Intelligence.
English
@CarriePrejean1 Christianity is the rejection of them and their religion. They have themselves repeatedly labeled Christianity as antisemitism.
Christianity is inherently antisemitic. Anyone claiming Christians should embrace what God rejects is antichrist.
English

They are making Christianity antisemitism.
Will you reject antisemitism if Christianity is antisemitism?
U.S. Conference of Catholic Bishops@USCCB
Catholics are called to reject antisemitism and the lies and conspiracies that fuel it, and to stand clearly against hatred and violence directed toward our Jewish brothers and sisters. To defend religious freedom with integrity, we must also reject antisemitism. @ArchbishpSample @archdpdx Watch the full video at: ow.ly/sYF550Yw6cA
English
@WaifuverseAI Intel is unofficially headquartered there too.
English

Your graphics card has a Israeli backdoor
*Walter Bloomberg@DeItaone
NVIDIA CEO SAYS HE IS 100% COMMITTED TO ISRAEL AND WILL HAVE STAFF THERE FOR A VERY LONG TIME - PRESS CONF
English
@BreeSolstad The Bible says to pray against your enemies. Physical presence is not required.

English

There is a witches convention coming to town and there’s an internal debate amongst a group at my Church.
Half of us want to go the convention to pray outside it with Rosary prayers & hymns.
The other half are fearful & say it could put us in spiritual danger.
What do you say?
English
@LandStander04 @Kneon While he is a problem, it's much larger than a single individual.
x.com/CricketInSand/…
CricketInSand@CricketInSand
@Kneon Indian ownership will be the death of the country. Microslop is unofficially an Indian company now. They almost exclusively only hire Indians. The downward spiral is directly related to Indian ownership and participation.
English




@Kneon Indian ownership will be the death of the country. Microslop is unofficially an Indian company now. They almost exclusively only hire Indians.
The downward spiral is directly related to Indian ownership and participation.
English
@IanCarrollShow No such thing as "modern Judaism." It is as it has been. Always been a Canaanite/Babylonian religion. This is why Jesus rejected them and their religion. This is why Jesus says their religion is about the glorification of themselves and not God.
Hebraism -> Christianity
English

Modern Judaism has rot at its core and Jews worldwide have to either pull it out at the root (Israel) or go to war with the whole world to fulfill its demonic goals.
Seethroughitall@seethroughit2
Rabbi Mizrachi says Tucker Carlson shouldn't worry about the 3rd Temple being built bc when it is built "there will not be one anti-semite left in the world...they won't be around anyway" "When God will send the Messiah to purify the world...not one wicked gentile will be left"
English

Tulsi turning out to be one of the biggest letdowns of the administration.
As DNI she was perfectly positioned to make a difference. Instead she seems to have joined the swamp.
Tulsi Gabbard 🌺@TulsiGabbard
Trump promised to get the US out of “stupid wars.” But now he and John Bolton are on the brink of launching us into a very stupid and costly war with Iran. Join me in sending a strong message to President Trump: The US must NOT go to war with Iran. #TULSI2020
English
@MoonBaseSpaceX @Bradypolish @DerrickEvans4WV False. Americans pay a premium on everything which is then significantly discounted to the rest of the planet. This is subsidization.
English

No america doesnt subsidize the world, basically you deploy your technology to the world and take payments without ever paying tax in that country, Amazon, no tax, google, no tax, microsoft, no tax, apple no tax. its funneled through tax havens.
What is worse, is your own government then rips off american citizens even more with tariffs, and you all love it aparently.
English

I had no idea that GPS signals are free worldwide & were funded by U.S. taxpayers at roughly $2 billion/year.

English
@Syed_Farhan_CSE @Govindtwtt Research confirms it lowers understanding and harms developer skills.
English


Why AI won't replace developers (it'll just make the good ones richer)
2025: AI writes 90% of code. Devs celebrate. Managers post about 10x gains.
2026: Code reviews are just checking prompts. Tech Twitter says "coding is dead lol"
2027: Reality check.
- 10 hours to debug what took 1 hour to generate
- Nobody understands the abstractions
- Everything breaks in production
Senior engineers now paid 10x because they can delete 5000 lines of AI spaghetti and replace it with 50 clean ones.
English
@nafonsopt Microsoft is an Indian company now in all but name. It's the singular reason Microsoft is now called Microslop. Everything about it is in steady decline.
English

Anybody who thinks that it is ok for telemetry to use 100% of your CPU should be fired immediately.

English
@Itsfoss They are all beholden to corporations for funding. These same corporations are globalist loyalists.
They are not guardians of anything other than globalist corporate interests.
English

@tomfgoodwin Contrary to AI marketing departments, many companies are already moving away from AI because it doesn't delivery productivity gains.
x.com/MrEwanMorrison…
Ewan Morrison@MrEwanMorrison
AI productivity bubble: Early adopters are already burning out. “There will be a wake up call and a reckoning for entire sectors who are adopting AI.” Natasha Bernal.
English
@tomfgoodwin If AIs were actually increasing productivity as AI companies claim, every index would have reflect this. Zero movement.
x.com/econcallum/sta…
Callum Williams@econcallum
There is still no productivity gain from AI in the US data
English

And yet , as a consumer , we see no benefit.
unusual_whales@unusual_whales
The past year has seen an explosion in coding productivity, per FT:
English