DaemonEye
2.3K posts




曾经 2024年的 AI 三板斧, 提示词工程 RAG 微调 Fine tuning 一定程度慢慢告别


惊闻微软把BOC搞出来了???? 好久没关注编程语言的进展了. 大家知道CSP(比如golang)是显式传递指针的,而BOC是隐式传递指针的, 这玩意最牛逼的点是, 传统Actor是一维的锁拓扑, 而这玩意是个二维的DAG! 所以锁粒度可以做到极致. 理论吞吐量嗷嗷高. 那么老问题来了, 就py那个垃圾GIL, 现在实现BOC必然要涉及到内存拷贝. boc将一个指针从线程A传递到线程B, 如果指针内部引用了py的原生数据结构, 就必然要拷内存 (不拷就直接segment fault了). 所以为了方便无拷贝传递指针, 我估计它还得在堆里自己搞个C实现的原始数据结构(FFI时代的老经验谈). 至于这玩意是否兼容py3.13那就不知道了... 总之这个是特别值得关注的, 算是PL圈子的爆炸性新闻了. 但无奈现在应该没有手工编程艺人了. microsoft.github.io/bocpy/



虽然大家普遍认为Claude是最牛的大模型公司,周围也都在用Claude。 但实际上,Claude的月活只有2000-3000 万人,是Gemini的1/30,更是Chatgpt的1/40。

chinese models are ~8 months behind and are falling further behind






MIT just made every AI company's billion dollar bet look embarrassing. They solved AI memory. Not by building a bigger brain. By teaching it how to read. The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely. Here is the problem nobody solved. Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for. Context rot. The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400. So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed. It was always a compromise dressed up as a solution. The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded. Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st. Here is what they built. Stop putting the document in the AI's memory at all. That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way. When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window. Then it does something that makes this recursive. When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer. No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it. Now here are the numbers. Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems. RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window. Cost per query: comparable to or cheaper than standard massive context calls. Read that again. One hundred times the context. Better answers. Same price. The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption. More context equals better performance. MIT just proved that assumption was wrong the entire time. Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question. The right question was never how much can you force an AI to hold in its head. It was whether you could teach an AI to know where to look. A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer. RLMs are the first AI architecture that works the same way. The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely. Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months. The context window wars are over. MIT won them by walking away from the battlefield. Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601 Paper: arxiv.org/abs/2512.24601 GitHub: github.com/alexzhang13/rlm



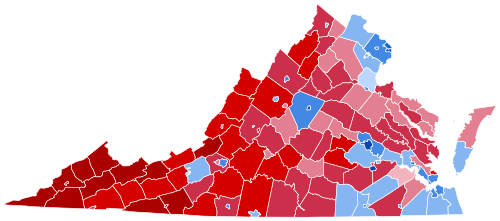
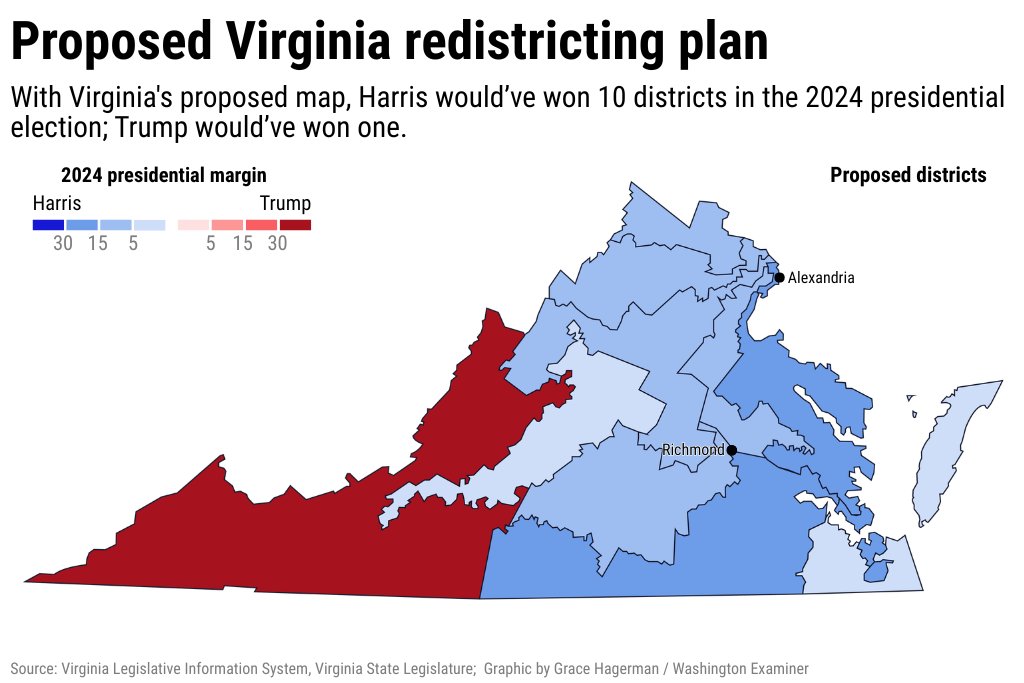
Congratulations, Virginia! Republicans are trying to tilt the midterm elections in their favor, but they haven’t done it yet. Thanks for showing us what it looks like to stand up for our democracy and fight back.
前几天还在庆幸 GitHub Copilot 的 Opus 4.6 没有降智,结果今天 GitHub 就直接撤回了所有 Pro 订阅对 Claude Opus 全系的访问权……(仅提供给 Pro+ 及以上订阅套餐了)🫠 看来还真是,全行业都已经烧不起了。 #opus-models-removed-from-pro" target="_blank" rel="nofollow noopener">github.blog/changelog/2026…

我有一个暴论:AI时代,Windows笔记本已经基本没救了 一个原因是Windows的AI API适配能力不如Mac,毕竟Mac是UNIX标准系统,命令行的实用性更高,利好桌面型智能Agent 另一个原因是RAM。M系列芯片早就在搞统一内存了,导致模型可用内存特别是带宽足够大;而受限于台湾主板产业链的利润分配,Wintel联盟还在用DDR内存,最大也就32,64GB,而且不是统一内存,显寸需要另算, 访问内存需要走总线,带宽更差,Prefill和Inference都吃亏 完了,想不到在AI上毫无投入的苹果,竟然成为AI发展的最大受益者 把所有事情都做到极限,这就是苹果永远能赢的哲学吧 不说了,加仓AAPL! 😅😅😅