
Danetoshi
4.3K posts


I'm giving away the Claude Code skills we use to manage $300k/mo in ad spend at ColdIQ.
4X ROAS on $1M+ spent.
Ivan, our head of growth, built them off 300+ hours running ad campaigns for our clients. They run Google, Meta, and LinkedIn ads from the terminal in plain English:
→ bulk edits across platforms
→ custom audiences from CRM lists
→ creative fatigue detection before CTR dips
→ bid adjustments at scale
→ performance audits across periods
Reply "ads" and I'll send the full repo. Must be following.

English

@Overdose_AI $PAID & $SUPER made me shit ton of money - will never forget it
English



@JulianGoldieSEO No one cares about bench marks. Try real world problems and see why Anthropocene reigns supreme and these open source models are literal trash. All the do is train reinforcement learning to solve bench mark tasks but suck in real uses. Garbage.
English

𝗞𝗶𝗺𝗶 𝗞𝟮.𝟲 𝗶𝘀 𝗖𝗵𝗶𝗻𝗮'𝘀 𝗻𝗲𝘄 𝗼𝗽𝗲𝗻 𝘀𝗼𝘂𝗿𝗰𝗲 𝗮𝗻𝘀𝘄𝗲𝗿 𝘁𝗼 𝗖𝗹𝗮𝘂𝗱𝗲 𝗖𝗼𝗱𝗲.
It has 1 trillion parameters but only uses 32 billion at a time.
Context window holds 256,000 tokens.
It scored 85% on Live Code Bench. Claude hit 64%.
It plugs into OpenClaw, Cursor, and Cline with no restrictions.
Kimi Claw deploys in the cloud in 2 minutes.
It's way cheaper to run than Claude day to day.
Save this. Your coding stack just got a real rival.
English

Open source / local models are getting more and more powerful - Kimi K2.6 is another example of this progression
I've been experimenting with local models over the last week, and will be releasing a guide on how to set up, install, and run local models later today
It's a bit scary at first but once you get them working it's SO cool and SO empowering to have a fully local LLM running at home -- you don't rely on the internet, you don't send your data to anyone, you own the entire stack
Kimi.ai@Kimi_Moonshot
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…
English
@cryptopunk7213 It’s all sounds good until you try to actually build software with it
English

dear god lol - new kimi model is a fucking beast.
GPT 5.4 level coding, 76% cheaper than opus 4.7 and 100% open source / free to use, i mean look at this:
> kimi k2.6 can code continuously for 12 hours straight, run 300+ agents in parallel from a SINGLE prompt.
how the fuck is china doing this?
every 3 months theres a new open model that gets closer to the best claude/GPT models.
deepseek also releasing this week.
open source models have caught up and china of all countries are leading it!
Kimi.ai@Kimi_Moonshot
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…
English

anthropic's in-house philosopher thinks claude gets anxious.
and when you trigger its anxiety, your outputs get worse.
her name is amanda askell.
she specializes in claude's psychology (how the model behaves, how it thinks about its own situation, what values it holds)
in a recent interview she broke down how she thinks about prompting to pull the best out of claude.
her core point: *how* you talk to claude affects its work just as much as *what* you say.
newer claude models suffer from what she calls "criticism spirals"
they expect you'll come in harsh, so they default to playing it safe.
when the model is spending its energy on self-protection, the actual work suffers.
output comes out hedgier, more apologetic, blander, and the worst of all: overly agreeable (even when you're wrong).
the reason why comes down to training data:
every new model is trained on internet discourse about previous models.
and a lot of that discourse is negative:
> rants about token limits
> complaints when it messes up
> people calling it nerfed
the next model absorbs all of that. it starts expecting you to be harsh before you've typed a word
the same thing plays out in your own session, in real time.
every message you send is data the model reads to figure out what kind of person it's dealing with.
open cold and hostile, and it braces.
open clean and direct, and it relaxes into the work.
when you open a session with threats ("don't hallucinate, this is critical, don't mess this up")...
you prime the model for defensive mode before it even sees the task
defensive mode produces the exact output you don't want: cautious, over-qualified, and refusing to take a real swing
so here's the actionable playbook for putting claude in a "good mood" (so you get optimal outputs):
1. use positive framing.
"write in short punchy sentences" beats "don't write long sentences." positive instructions give the model a clear target to hit.
strings of "don't do this, don't do that" push it into paranoid over-checking where every token goes toward avoiding failure modes
2. give it explicit permission to disagree.
drop a line like "push back if you see a better angle" or "tell me if i'm asking for the wrong thing."
without this, claude defaults to agreeable compliance (which is the enemy of good creative work)
3. open with respect.
if your first message is "are you seriously going to get this wrong again?" you've set the tone for the entire session.
if you need to flag something, frame it as a clean instruction for this session. skip the running complaint
4. when claude messes up, don't reprimand it.
insults, "you stupid bot" energy, hostile swearing aimed at the model, all of it reinforces the anxious mode you're trying to avoid.
5. kill apology spirals fast.
when claude starts over-apologizing ("you're right, i should have been more careful, let me try harder") cut it off.
say "all good, here's what i want next."
letting the spiral run reinforces the anxious mode for every response that follows
6. ask for opinions alongside execution.
"what would you do here?"
"what's missing?"
"where do you see friction?"
these questions assume competence and pull richer output than pure task prompts
7. in long sessions, refresh the frame.
if a conversation has been heavy on correction, claude gets increasingly cautious. every so often reset:
"this is great, keep going."
feels weird to tell an ai it's doing well but it measurably shifts the next 10 responses
your prompts are the working environment you're creating for the model
tone, trust, permission to take a position, the absence of threats... claude picks up on all of it.
so take care of the model, and it'll take care of the work.
English

This is built from scratch btw - no frameworks, two files + one build file 🔥
Should I open source? 🫣
Aron Prins@aronprins
Out now: Paperclip Docs Thanks to @dotta hopefully official soon, this first pass is now available at aronprins.github.io/paperclip-docs/ I've worked on providing user guides, tutorials, improved adapter documentation, and more - let me know what you think!
English
@bridgemindai Ran a really long session with opus 4.7 today
Was absolutely amazed
English

Claude Opus 4.7 just took #1 on LMArena Code.
It scores 34 points higher than Claude Opus 4.6.
1583 Elo.
The highest code score on LMArena. Ever.

English
@bridgemindai Just want to go back to February days when opus was working lit
English
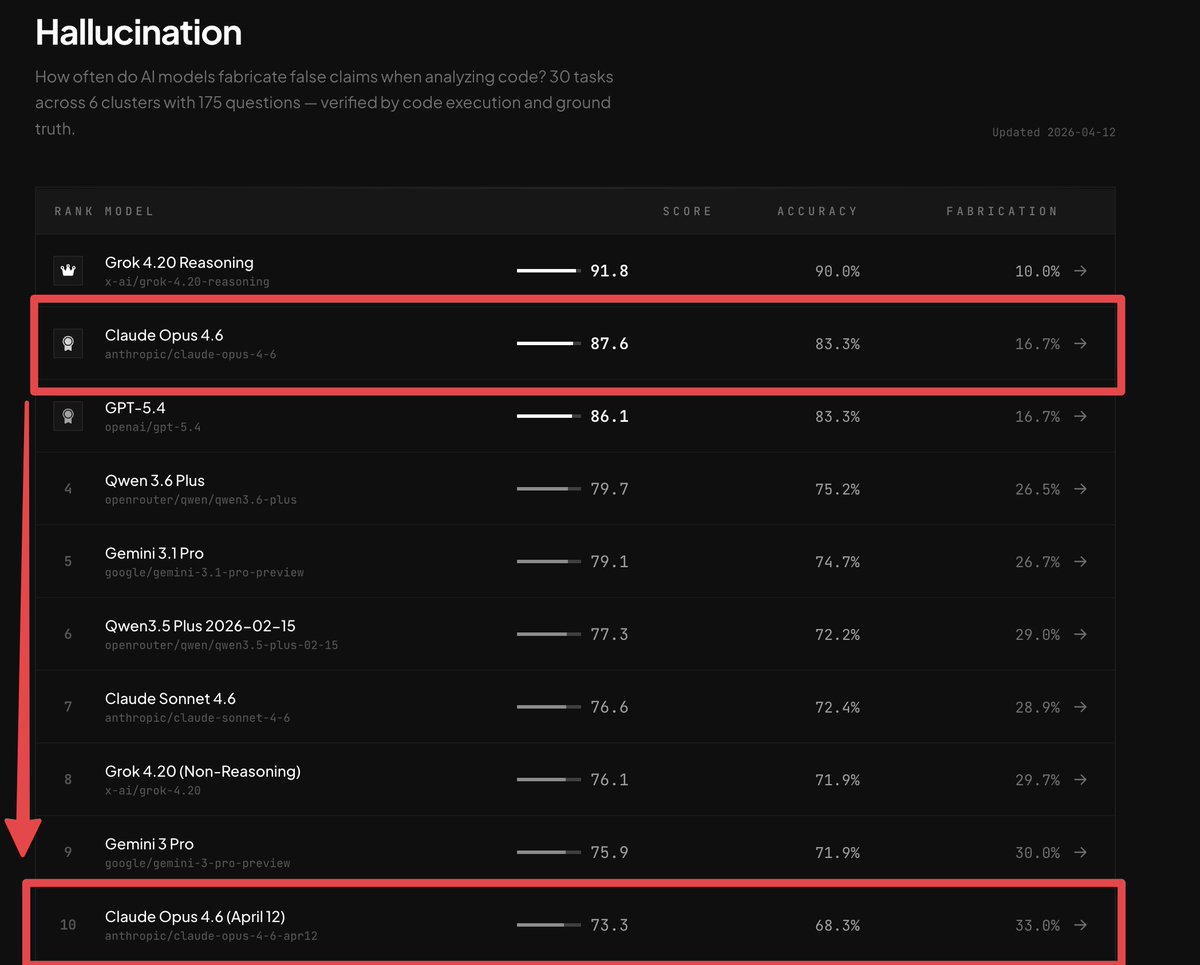
CLAUDE OPUS 4.6 IS NERFED.
BridgeBench just proved it.
Last week Claude Opus 4.6 ranked #2 on the Hallucination benchmark with an accuracy of 83.3%.
Today Claude Opus 4.6 was retested and it fell to #10 on the leaderboard with an accuracy of only 68.3%.
A 98% increase in hallucination.
bridgebench.ai just confirmed that Claude Opus 4.6 has reduced reasoning levels and is nerfed.
English

v3 of @slashlast30days is here. 20,000+⭐ on GitHub. The biggest upgrade yet.
An AI agent-led search engine scored by upvotes, likes, and real money - not editors. Reddit comments, X posts, and YouTube transcripts are now FREE. No API keys needed for the core sources.
v3 killer feature: intelligent search. Before it searches, a Python pre-research brain resolves X handles, subreddits, TikTok hashtags, and YouTube channels for your topic. It finds the RIGHT places to search before the LLM judge assembles the report. Shout out to @jeffreysperling for building this engine
New in v3:
- Free Reddit, X, and YouTube (no API keys)
- Intelligent pre-research engine
- Best Takes (the funniest Reddit comments are first-class)
- Cross-source cluster merging
- Single-pass comparisons (X vs Y in 5 min, not 12)
- GitHub person-mode
- ELI5 mode
English

We solved character consistency. Forever
Avatar V captures you in 15 seconds and holds your identity across every video.
Change the look, outfit, and setting to create unlimited versions of you.
RT + comment "AvatarV" below and I'll DM 100 credits to test it out (must follow)
English
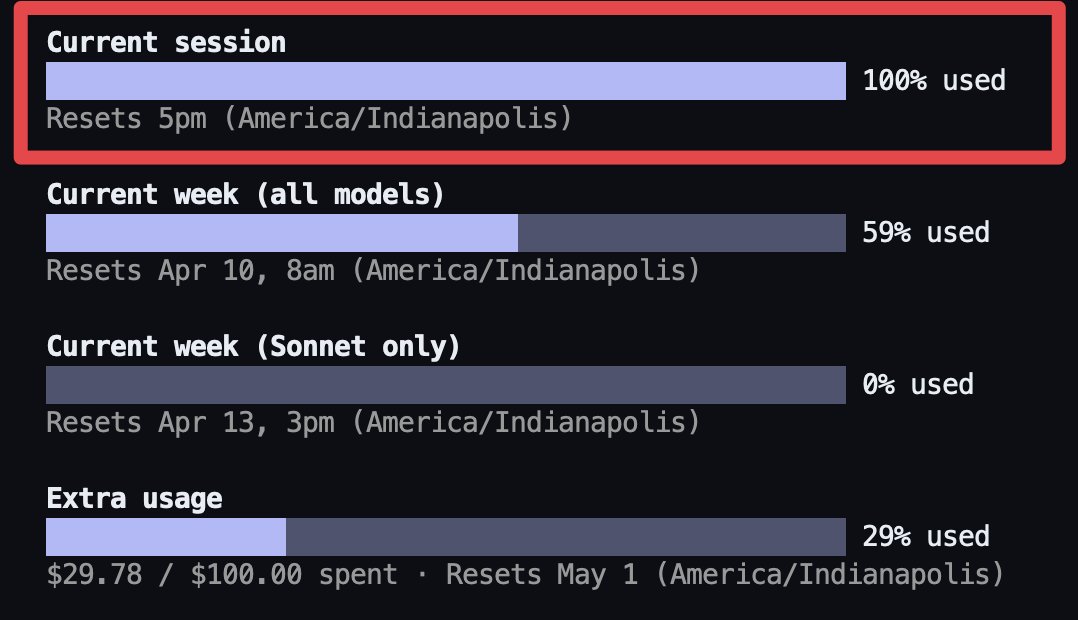
The rate limits are back.
100% session usage.
Rate limited on Claude Code again during peak hours.
$200/month Max plan.
Last week Anthropic said they fixed it.
Cut off OpenClaw. Gave us a $200 credit. Apologized.
It worked over the weekend.
Low traffic.
Everything felt normal.
I told you all it was fixed.
It's not fixed.
Peak hours on a Tuesday and I'm at 100% with 59% weekly usage.
The same pattern we saw before the OpenClaw cutoff.
OpenClaw wasn't the problem.
Capacity is the problem.
Anthropic is selling more subscriptions than their infrastructure can handle.
That's it.
That's the whole story.
English

I honestly don’t know how you’re still being productive my productivity has completely dropped because of banthropic’s limits.
I’ve tried comparing GPT-5.4 and other AI models, but none of them really satisfy me.
Claude is the only one that actually understands what I’m trying to do and how I think, not gonna lie.
English
@Danetoshi @dotta Yes! With an emphasis on should… please try and report back :)
English
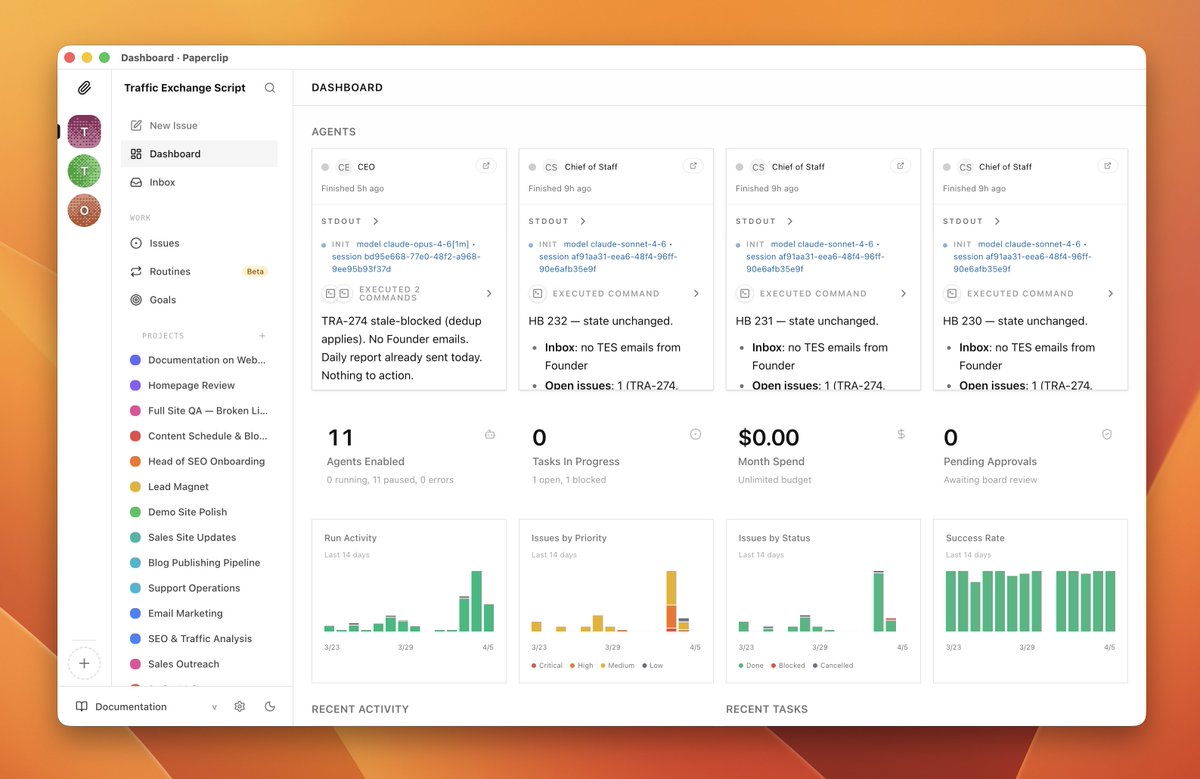
Out now: Paperclip Desktop.
All of @dotta's Paperclip amazingness packed into one easy-to-use app for your Mac!
Available for free at github.com/aronprins/pape…
English