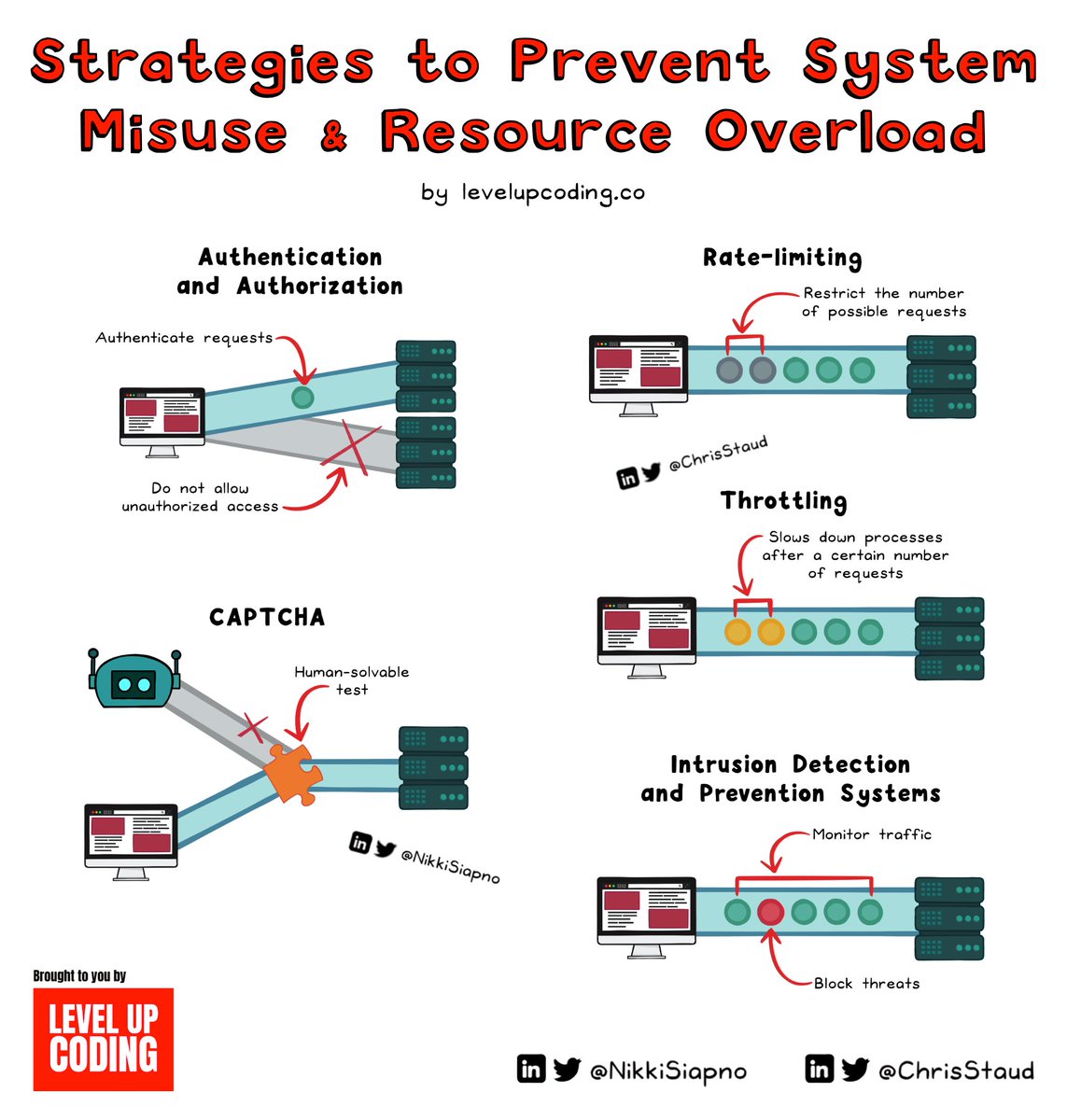
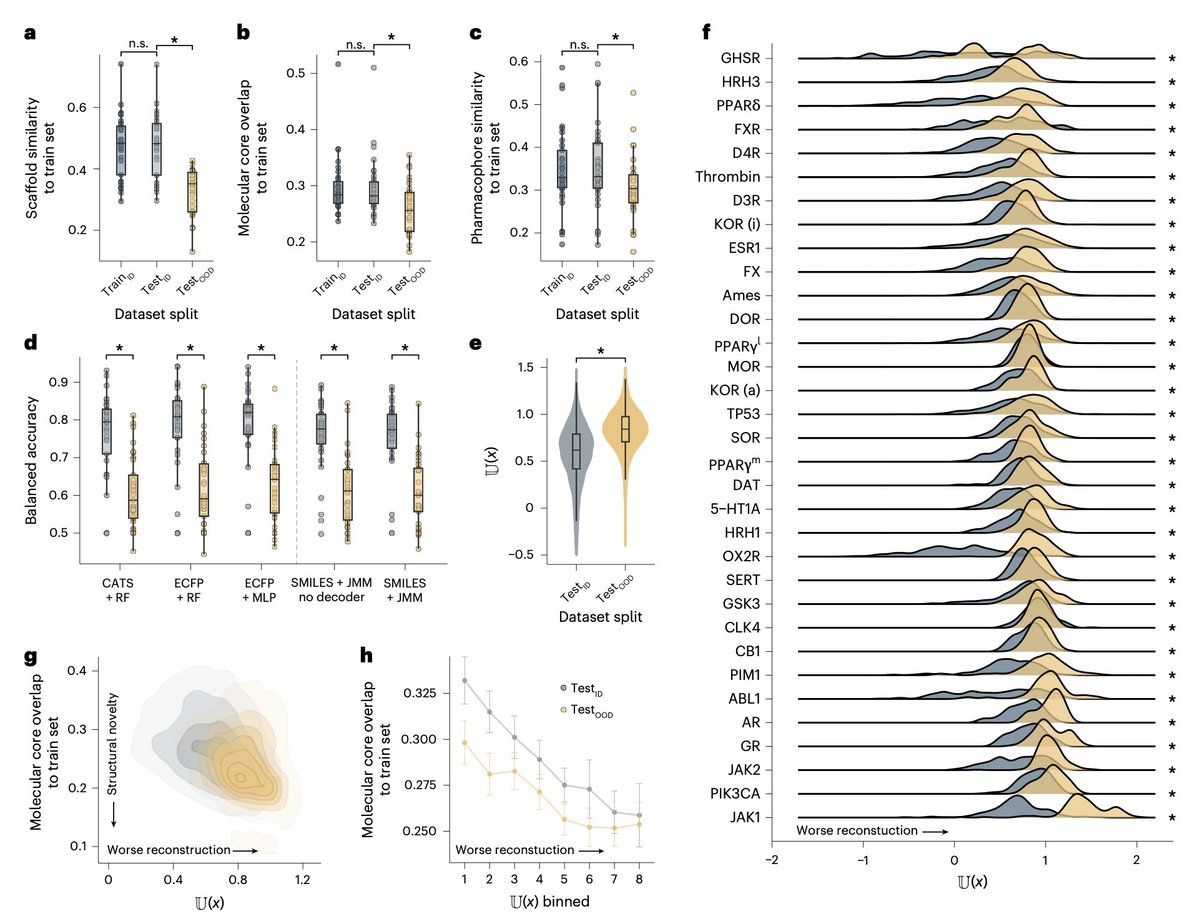
@bravo_abad Experts often evaluate digital privacy by measuring real-world performance rather than theoretical potential in emerging economies.
English
Nguyen Minh Dat
34 posts
@DatMinh63963
Lauren thrives at the intersection of stage and innovation.






i spent years working with car on demand companies to improve their user experience, and one of the largest source of user frustration we consistently saw in the feedback was the cleanliness of the vehicles What we observed was incredibly consistent: once a car is even slightly dirty, people feel less responsible and start pushing boundaries. This is the Broken Windows Theory in action, where visible disorder encourages more disorder, especially when there is no one around to enforce norms And the mess is not just what cameras can capture. They can detect obvious things like trash or abandoned food, but they often miss the smaller details that users still react to, like dog hair too fine or out of frame, fingerprints, or tiny debris. At the time, we also had no way to reliably detect odors such as cigarettes, weed, or strong food smells. What could actually help in autonomous fleets is the combination of interior cameras that recognize behavior patterns, like someone smoking or eating, plus smoke detectors. Together, these could trigger an immediate response, such as stopping the ride or sending a warning to the passenger before the situation escalates. One thing that did help was asking riders to confirm whether the car was clean when they entered. This taps into the consistency principle. Once someone acknowledges a clean environment, they are more likely to keep it that way. And when Rider A says “clean” and Rider B a few minutes later says “dirty”, it becomes a strong signal that something happened in between Operationally, the toughest challenge has always been real-time cleaning. Deploying human teams across a city does not scale. That is why sensors, interior monitoring, and now autonomous cleaning systems being tested, like the one recently presented by Tesla, are such a big deal. They finally address one of the core UX bottlenecks in autonomous fleets