
DataInforms
10.1K posts


🤯 There is no bound on context length in BDH-GPU, Dragon Hatchling, the new brain-inspired language model.
because of how it manages memory and updates signals layer by layer.
In a Transformer, the length of context is bounded by the size of the attention mechanism, since every new token must compare against all past tokens stored in the cache. That makes it scale poorly as context grows.
BDH-GPU instead uses local neuron updates. Each layer decides whether a past signal is still relevant. If the layer deems it irrelevant, it just weakens or skips that signal. This means not every token needs to be carried forward, only the ones that continue to matter.
As inputs pass through higher layers, the model naturally filters and denoises. Old signals that add noise fade out, while strong ones get reinforced. Because of this filtering, the model can keep track of important details across very long spans without memory overload.
Another key difference is that memory is stored in synaptic connections rather than in a giant cache of past tokens. That allows information to be compressed into the state of the network itself, not stored explicitly for every past token.
So the reason BDH-GPU avoids a strict limit is that it treats context as an evolving state rather than as a giant history buffer. That makes it possible to scale context length upward as long as noise is controlled.

English
Wow. 🧠
The paper presents Dragon Hatchling, a brain-inspired language model that matches Transformers using local neuron rules for reasoning and memory.
It links brain like local rules to Transformer level performance at 10M to 1B scale.
It makes internals easier to inspect because memory sits on specific neuron pairs and activations are sparse and often monosemantic.
You get reliable long reasoning and clearer debugging, because the model exposes which links carry which concepts in context.
The problem it tackles is long reasoning, models often fail when the task runs longer than training.
The model is a graph of many simple neurons with excitatory and inhibitory circuits and simple thresholds.
It stores short term memory in the strengths of connections using Hebbian learning, so links that fire together get stronger.
Those local rules behave like attention but at the level of single neurons and their links.
They also present BDH-GPU, a GPU friendly version that implements the same behavior as an attention model with a running state.
This design produces positive sparse activations, so only a small fraction of neurons fire at a time.
Many units become monosemantic, meaning one unit often maps to one clear concept even in models under 100M.
The theory ties the approach to distributed computing and explains how longer reasoning can scale with model size and time.
----
Paper – arxiv. org/abs/2509.26507
Paper Title: "The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain"

English

Thanks for reading! A bit about me:
Last year, I founded @4SocialsX — a premium personal branding agency helping top founders, VCs & execs attract capital, clients & talent.
If you found this valuable, follow me for more.

English
This tech giant owns the entire Kindle world, yet almost nobody knows their name.
e-Paper wouldn't exist without them.
They license their displays to Amazon, Sony, and even bus stations
Here’s what I call the most powerful monopoly in modern electronics… 🧵

English

How do you train small reasoning models more effectively?
This is a problem many AI devs run into. RL fine-tuning, in general, tends to plateau, especially for 1–2B models.
I think DeepSearch offers a really clean approach here. It takes the idea of Monte Carlo Tree Search (MCTS) at inference and moves it into the training loop. That shift unlocks better exploration and more efficient learning.
Here are my notes from the paper:
The loop involves four key ideas:
Searching During Training: Instead of only doing search at test-time, MCTS is run during RL training. A local UCT selector ranks siblings, while a global frontier scorer picks promising leaves across the whole tree based on parent value, entropy, and depth.
Learning From Both Wins and Confident Wrongs: If a correct solution isn’t found, the model still learns by supervising the confident wrong path (lowest entropy mistakes). Correct paths stay non-negative during updates, which helps with step-level credit assignment.
Stabilizing RL with Tree-GRPO: They refine PPO-style objectives with node-level q-values, mean-only normalization, and a soft clipping strategy. This avoids reward explosions while keeping gradients informative.
Staying Efficient: To cut wasted compute, DeepSearch filters to a hard subset of problems, caches solutions once they’re verified, and skips full search when an answer is already known.
All of these improvements lead to strong results.
DeepSearch-1.5B reaches 62.95% on AIME/AMC benchmarks, beating a top Nemotron baseline while using only ~330 GPU hours. By comparison, normal RL training plateaus lower even with 1,800+ GPU hours.
Paper: arxiv.org/abs/2509.25454
I think this paper offers a practical recipe for breaking through plateaus in small reasoning LMs:
• Move search into training, not just inference
• Supervise both right and wrong paths
• Use global prioritization to explore smarter
• Cache and filter to keep efficiency high

English

That's a wrap! Over the next 24 days, I'm sharing the 24 concepts that helped me become a data scientist.
If you enjoyed this thread:
1. Follow me @mdancho84 for more of these
2. RT the tweet below to share this thread with your audience
Matt Dancho (Business Science)@mdancho84
Google just dropped a new Generative AI Python library for SQL Databases. Introducing Google GenAI Toolbox. This is what you need to know:
English
Google just dropped a new Generative AI Python library for SQL Databases.
Introducing Google GenAI Toolbox.
This is what you need to know:

English

10 Perplexity Deep Research prompts to turn you into a superhuman: 👇

English



Men taking estrogen do not get periods because they do not have a uterus, and therefore do not shed their uterine lining.
Thank you for attending my science class.
English

P.S. - It took me 3 years to become confident in algorithmic trading.
So I spent 100 hours and made a free course to help others.
Join my free Algo Trading with Python Course + Roadmap here: startalgorithmictrading.com/beginners-algo…
English
🚨BREAKING: Python's Newest Algorithmic Trading Tool.
Introducing Nautilus Trader. 100% free.
Here's what it does (and how to get started in under 3 minutes):
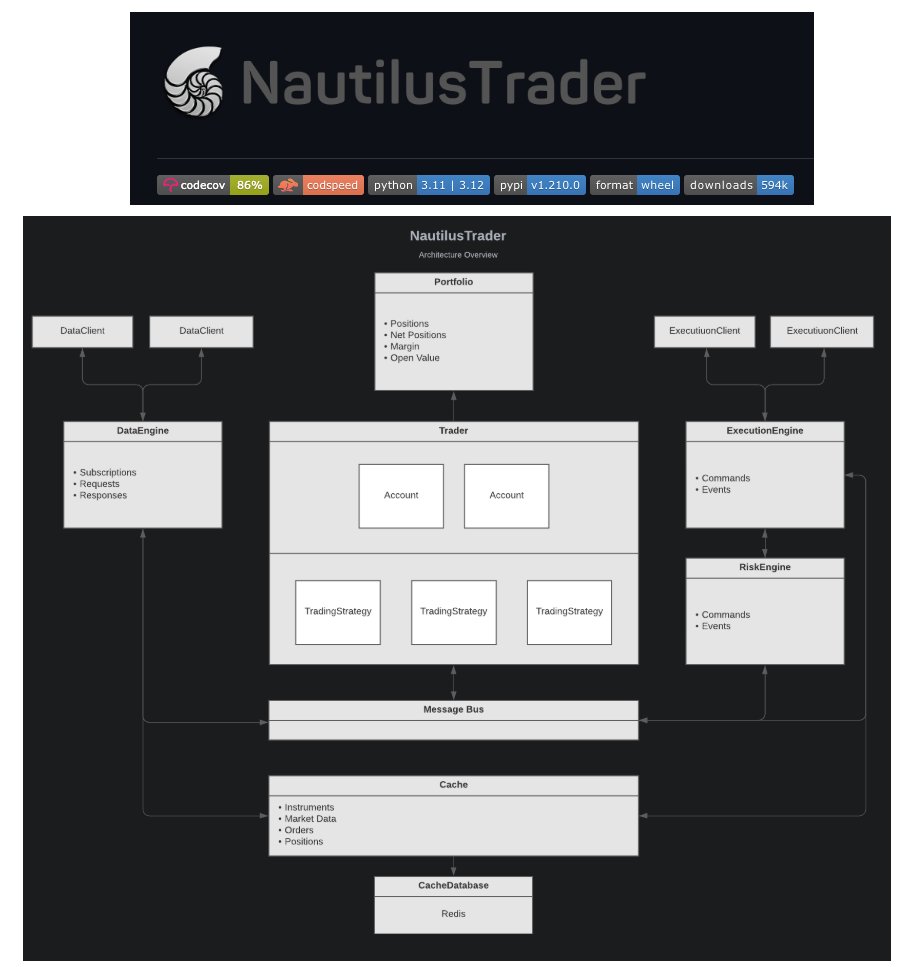
English
@Shariakill @grok - does the Quran actually say this - can you list references if so
English

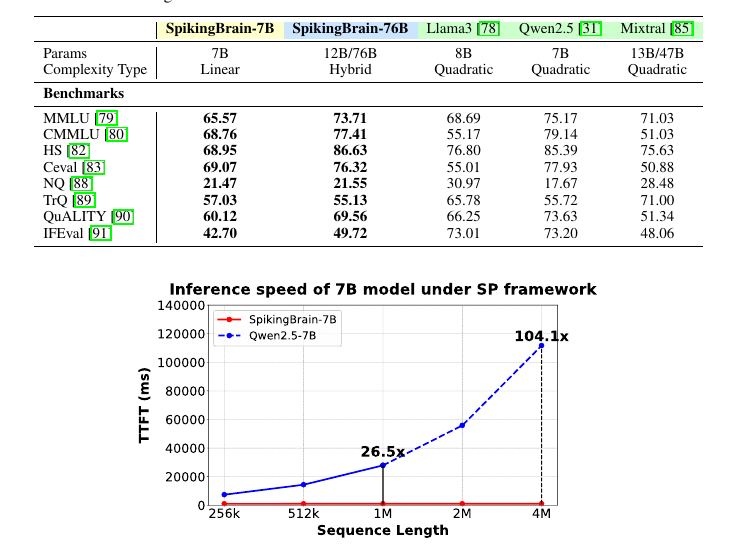
Overall, this paper ran a huge language model over insanely long inputs, like 4 million tokens, and made it generate the first word more than 100x faster than normal Transformers
And they can do this while training on only about 2% of the data that’s usually needed
How do they achieve it?
They basically copy two tricks from the brain.
First, instead of looking at all words all the time (which is very expensive), they use linear attention. That means the model keeps a running summary of past words, like a compressed memory, instead of storing everything in full.
Second, they add spiking neurons. These only “fire” when something really matters, instead of constantly doing math for every single signal. That makes the computations sparse, which saves a ton of energy and time
Together, these changes turn the model into something much leaner: it still learns well, but it runs way faster and uses way less power.
English
🇨🇳China unveils world's first brain-like AI Model SpikingBrain1.0
Upto 100X faster while being trained on less than 2% of the data typically required.
Designed to mimic human brain functionality, uses much less energy. A new paradigm in efficiency and hardware independence.
Marks a significant shift from current AI architectures
Unlike models such as GPT and LLaMA, which use attention mechanisms to process all input in parallel, SpikingBrain1.0 employs localized attention, focusing only on the most relevant recent context.
Potential Applications:
- Real-time, low-power environments
- Autonomous drones and edge computing
- Wearable devices requiring efficient processing
- Scenarios where energy consumption is critical
This project is part of a larger scientific pursuit of neuromorphic computing, which aims to replicate the remarkable efficiency of the human brain, which operates on only about 20 watts of power.
---
arxiv .org/abs/2509.05276

Rohan Paul@rohanpaul_ai
SpikingBrain’s technical report reveals a new family of brain-inspired LLMs. Learn how its hybrid-linear attention, conversion-based training, and spiking neurons deliver over 100x speedups and unprecedented efficiency on non-NVIDIA hardware. 100x faster first token at 4M tokens, with training on about 2% of the usual data. Transformers slow down as sequences grow, because each new token checks many earlier tokens and the memory cache keeps growing. SpikingBrain mixes 2 cheaper attentions, linear keeps a small running summary, sliding-window reads only a short slice. The 7B model alternates these layers for near linear cost, the 76B model adds parallel branches and a few full layers. Feed forward blocks use Mixture of Experts, a router picks a small set per token so most weights stay idle. The key idea is adaptive threshold spiking, activations become integer counts during training then expand into sparse events at inference. A light conversion pipeline remaps a standard checkpoint, extends context to 128k, then finishes with supervised fine tuning. Everything runs on MetaX C550 GPUs, the 7B model keeps memory near constant as inputs grow and accuracy stays close to baselines. ---- Paper – arxiv. org/abs/2509.05276 Paper Title: "SpikingBrain Technical Report: Spiking Brain-inspired Large Models"
English

Most people look at ChatGPT and don't get it.
The real question isn't whether AI will improve—it's where value gets captured. Models or applications? We still don't know.
Listen now: Benedict Evans on The Knowledge Project
English

These guides are so worth bookmarking and revisiting!
Here's the unrolled version of this thread:
↳ typefully.com/DataChaz/6WtAe…
If this was useful, a like or repost means a lot and helps others find it too 🙏
Follow me → @datachaz for daily insights on LLMs and AI agents
Charly Wargnier@DataChaz
AI guides are flooding the scene, but these top 9 picks from OpenAI, Google, and Anthropic are the ones you can't miss 🧵 ↓
English
AI guides are flooding the scene, but these top 9 picks from OpenAI, Google, and Anthropic are the ones you can't miss 🧵 ↓

English
English

Introducing Oboe. Out now.
Human beings are getting stupider. We all know it.
Meanwhile, we’ve spent trillions to make the most incredible technology in the history of humanity, and we’ve outsourced all of our individual agency in the process.
(1/3)
English
DataInforms retweetledi

BREAKING:
The Prime Minister has just attacked and lied about me in Parliament
1. I did NOT state that ‘vaccines are linked to cancer’
I was presenting information about the possible link of the covid mRNA vaccine and cancer from US HHS data and quoting oncologist Professor Angus Dalgleish ‘it’s highly likely that the covid vaccines have been a significant factor in cancer of members of the royal family’
2. Conflating legitimate safety concerns of a novel mRNA technology with all vaccines is preposterous and dangerous
3. Research reveals that behaviour such as Starmer’s today is what is fuelling the concerning reduced uptake of vital traditional vaccines. gh.bmj.com/content/7/5/e0…
It’s no wonder trust in this Labour government is very low.
We need to do better
English

I hope you've found this thread helpful.
Follow me @connordavis_ai for more.
Like/Repost the quote below if you can:
Connor Davis@connordavis_ai
🚨 BREAKING: OpenAI just killed the “hallucinations are a glitch” myth. New paper shows hallucinations are inevitable with today’s training + eval setups. Here’s everything you need to know:
English
🚨 BREAKING: OpenAI just killed the “hallucinations are a glitch” myth.
New paper shows hallucinations are inevitable with today’s training + eval setups.
Here’s everything you need to know:

English

Thanks for reading!
If you enjoyed this thread, you'll love my newsletter...
Every Friday, I share my best investing tips:
- Super investor secrets
- Multi-baggers breakdowns
- Investing frameworks
I share it all in my newsletter.
Join here for free:
100baggerhunting.com
English

@RWMaloneMD If the first part is true - the second part should not be a question.
That someone in Congress poses this as if its a valid question proves we have gone full Clown World.
English

Well, Bernie wants to know - are the Senators on the Finance committee, who took $$$ from big Pharma all corrupt? What do y-all think?

English

9 core patterns for building Fault-Tolerant Applications
Fall seven times, stand up eight.
Follow @techNmak for more :)

English

FREE Python Courses (+ Certificates)
1. Start with this
kaggle.com/learn/python
2. Take any one of these
❯ openclassrooms.com/courses/690085…
❯ scaler.com/topics/course/…
❯ simplilearn.com/learn-python-b…
3. Then take this
netacad.com/courses/python…
4. Attempt for this certification
programming-25.mooc.fi
Or,
freecodecamp.org/learn/scientif…
Or,
cs50.harvard.edu/python/2022/
Or,
learn.saylor.org/course/view.ph…
Or,
hackerrank.com/skills-verific…
5. Take it to the next level
❯ Django
openclassrooms.com/courses/696719…
❯ Data Scrapping, NumPy, Pandas
scaler.com/topics/course/…
❯ Data Analysis
openclassrooms.com/courses/230473…
❯ Data Visualization
kaggle.com/learn/data-vis…
❯ Data Science
learn.saylor.org/course/view.ph…
❯ Machine Learning
developers.google.com/machine-learni…
❯ Deep Learning
kaggle.com/learn/intro-to…

English
Python is MUST in 2025.
This is how to START and MASTER it in 1 year:
English