Drake retweetledi

Just off stage at #GoogleIO, some highlights from this morning 🧵
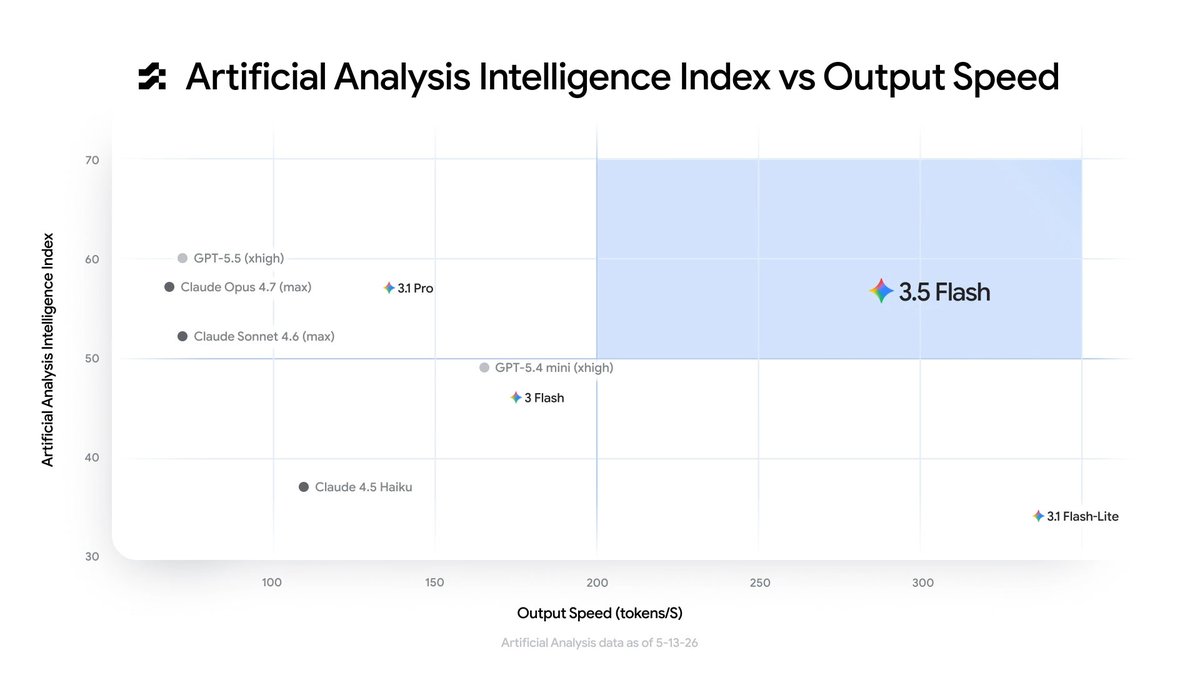
Gemini 3.5 Flash is available today for everyone in @antigravity and across our products and APIs.
Compared to 3.1 Pro, 3.5 Flash is better across almost all benchmarks with huge progress in coding. It’s also comparable to the best models but very fast (4x faster tokens/ second than other frontier models). And when looking at the intelligence versus output speed, it’s in a league of its own in the top right quadrant.
English