Wenxuan Tan
15 posts


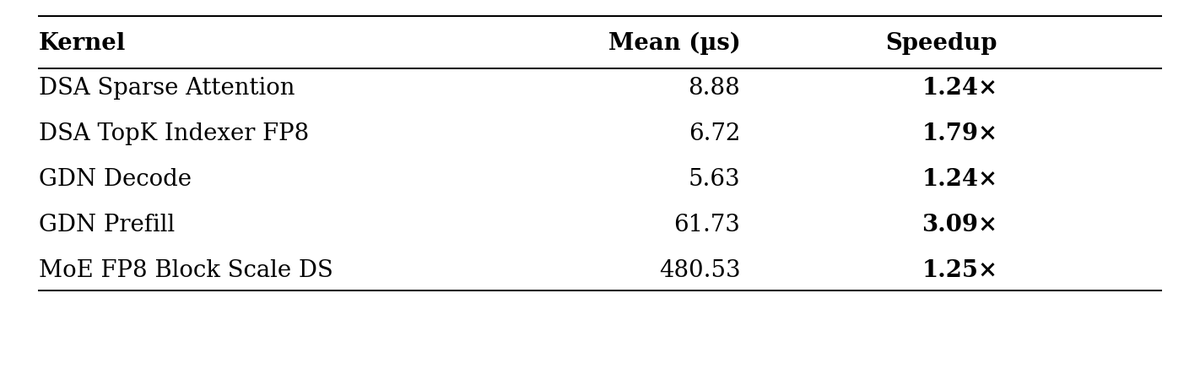
Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.

笑死了,Claude Opus4.8蒸馏了阿里巴巴Qwen啊🤣 通过API用中文问你是谁,会很大概率回答 我是通义千问(Qwen),是阿里巴巴集团旗下的统义实验室自主研发的超大规模语言模型。






(1/5) FP4 hardware is here, but 4-bit attention still kills model quality, blocking true end-to-end FP4 serving. To fix that, we propose Attn-QAT, the first systematic study of quantization-aware training for attention. The result: FP4 attention quality is comparable to BF16 attention with 1.1x–1.5x higher throughput than SageAttention3 on an RTX 5090 and 1.39x speedup over FlashAttention-4 on a B200. Blog: haoailab.com/blogs/attn-qat/ Code: github.com/hao-ai-lab/Fas… Checkpoints: huggingface.co/FastVideo/14B_…




🚀SonicMoE🚀: a blazingly-fast MoE implementation optimized for NVIDIA Hopper GPUs. SonicMoE reduces activation memory by 45% and is 1.86x faster on H100 than previous SOTA😃 Paper: arxiv.org/abs/2512.14080 Work with @MayankMish98, @XinleC295, @istoica05, @tri_dao





