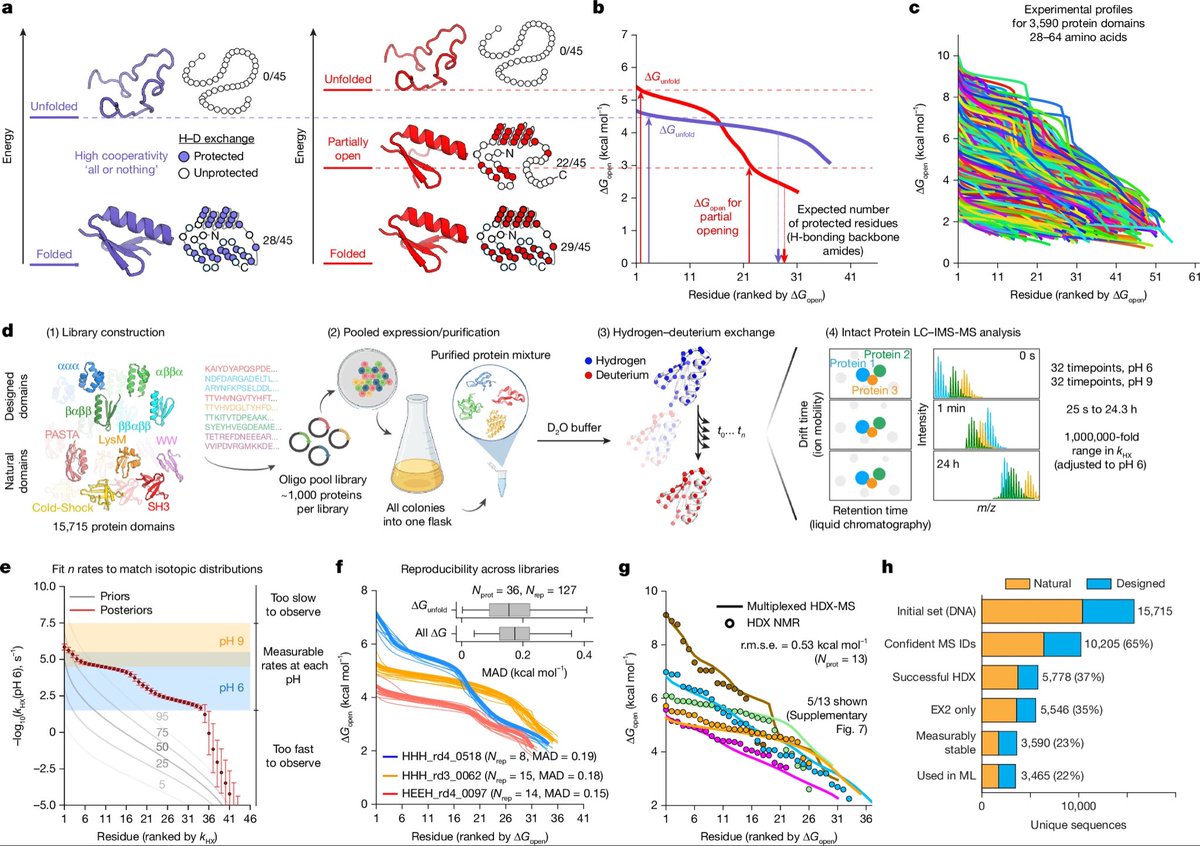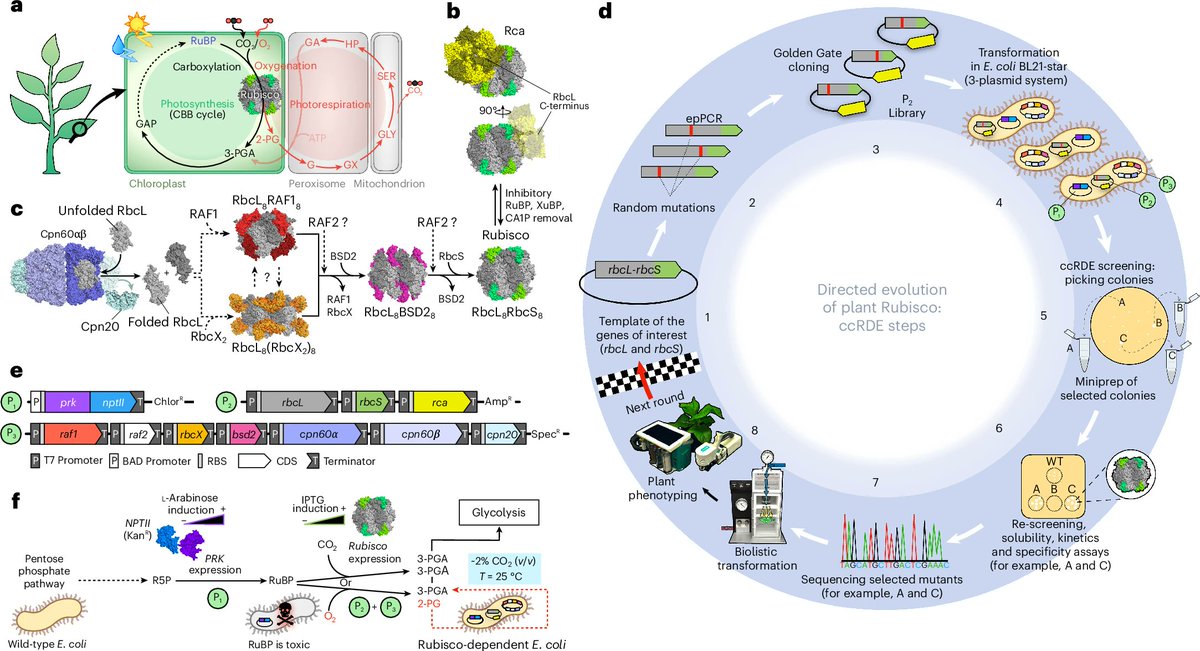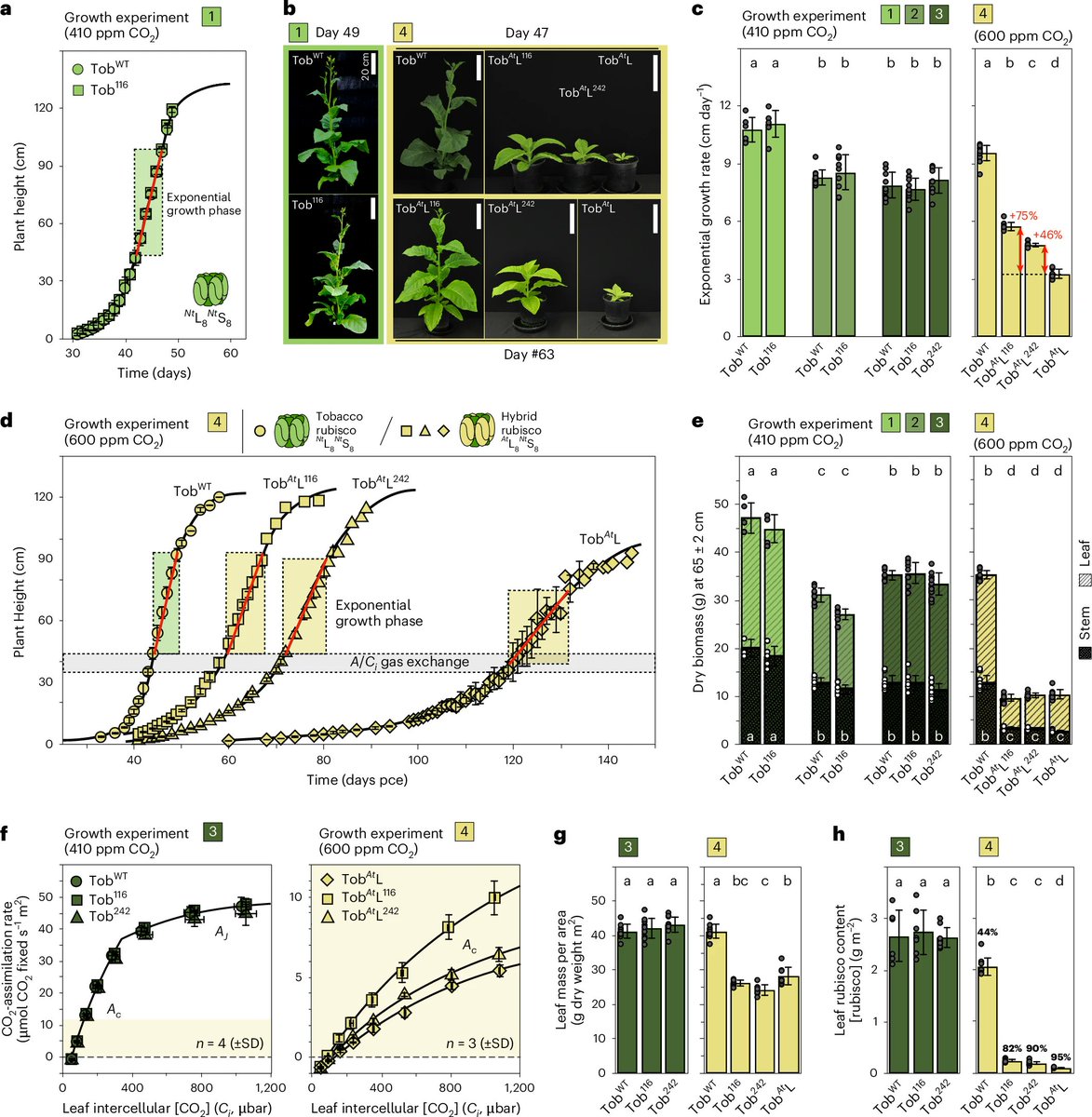
Sabitlenmiş Tweet

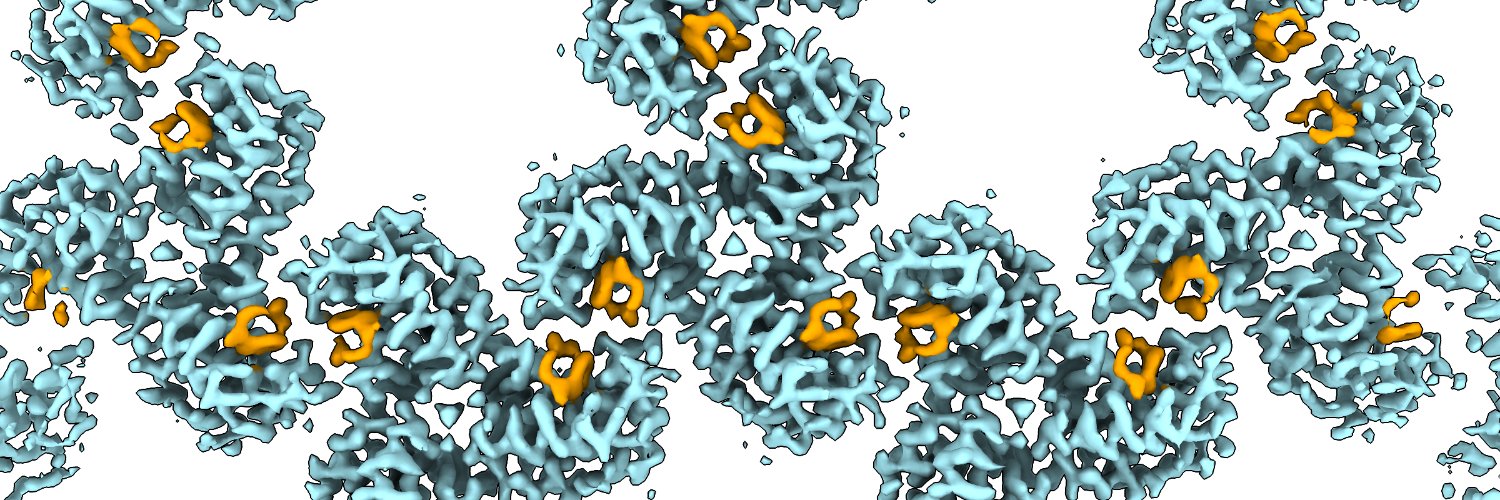
I am very happy to announce that we solved the in-virus #cryoEM structure of the #HIV matrix protein. The structure helped us to resolve a long mystery in HIV biology. A🧵1/5
Read more in @Nature : nature.com/articles/s4158… 🧪

John Briggs@BriggsGroup
Mature #HIV-1 contains >2000 copies of “spacer peptide 2”, but we didn’t know why. We now see that SP2 binds the matrix protein and triggers the change into its mature arrangement. Summary video from @MargotRiggi :
English